В почти всяка компютърна програма има части от кода, които се разклоняват в отделни пътища. Например оператор if-then-else има два възможни резултата. Тези твърдения не представляват проблем за последователните процесори, тъй като процесорът обработва всяка команда в ред. Разклоненията представляват голям проблем за конвейерните процесори, тъй като множество инструкции се изпълняват наведнъж.
Сценарият
В случай на програма с оператор за разклоняване с два възможни резултата, двата възможни кодови пътя не могат да бъдат на едно и също място. Обработката, необходима за завършване на двете опции, ще бъде различна. В противен случай програмата не би се разклонила. Вероятно ще има доста голям брой разклоняващи се оператори, които се вземат само веднъж, като оператор if.
Има също разклоняващи се оператори, които образуват цикъл. Въпреки че те може да не са толкова често срещани в численост, колкото твърденията за еднократна употреба, те обикновено се повтарят статистически. Може да се предположи, че е по-вероятно един клон да ви върне обратно в цикъл, отколкото не.
Защо това е проблем?
Няма значение как е формулиран този проблем в напълно последователен процесор. Това просто не е проблем. Кой клон ще бъде взет се знае преди да бъде обработена първата част от следващата инструкция.
В конвейерния процесор обаче следните инструкции се поставят на опашка. Те вече се обработват, когато процесорът знае кой клон се заема. И така, как трябва процесорът да се справи с този сценарий? Има няколко варианта. Най-лошото е просто да чакате и да оставите тръбопровода да не работи, докато чака отговора кой клон да поеме. Това би означавало, че всеки път, когато имате оператор за разклоняване, винаги ще губите поне толкова цикли процесорно време, колкото имате етапи в конвейера.
Като алтернатива можете да опитате да стартирате и двете опции в процес на изпълнение и да отхвърлите грешния избор. Това би имало половината от наказанието, ако не правите нищо, но все пак ще доведе до наказание за производителност при всяко изявление за разклоняване. Като се има предвид, че съвременните процесори могат също така да изпълняват инструкции без ред, потенциално бихте могли да опитате да изпълните всяка инструкция за разклоняване възможно най-скоро. Така че резултатът от него е известен, преди да е необходимо. Тази опция може да бъде полезна, освен че не е мащабируема. Да предположим, че имате относително висока плътност на разклонени изрази. В този случай просто няма да можете да стартирате всички от тях рано, без да имате известно време на празен ход.
Как наистина се решава този проблем
В действителност процесорът включва предсказател на разклонения. Предсказателят на разклонения се опитва да познае кой резултат от избор на разклоняване ще бъде взет. След това процесорът приема, че прогнозата е правилна и планира инструкции. Ако предсказателят на разклонения е точен, няма наказание за ефективността.
Ако предикторът на разклонения направи грешка, трябва да прочистите тръбопровода и да започнете да обработвате действителния резултат. Това наистина води до малко по-лошо изпълнение, отколкото да не сте направили нищо и просто да изчакате резултата. За да получите най-добра производителност, важно е да се уверите, че предикторът на разклонения е възможно най-точен. Има набор от различни подходи към това.
Съответстващ код
В машинния код разклонението винаги е избор между четене на следващата инструкция или преминаване към набор от инструкции другаде. Някои ранни реализации на предсказатели на клонове просто предполагаха, че всички клонове винаги или никога няма да бъдат взети. Това внедряване може да има изненадващо добър процент на успех, ако компилаторите познават това поведение и го познават предназначени да коригират машинния код, така че най-вероятният резултат да съответства на общия процесор предположение. Това изисква много настройка и коригиране на навиците за разработка на софтуер.
Друга алтернатива беше да се научи от статистиката, че циклите обикновено се вземат и винаги прескачат, ако клонът върви назад в поток от инструкции и никога не прескачайте, ако скокът е напред, защото това обикновено би било статистически по-малко вероятното състояние на напускане цикъл. Това са и двата вида статично предвиждане на разклонения, при което резултатът от разклонение се предвижда по време на компилиране.
Динамични предсказатели на клонове
Съвременните предсказатели на клонове са динамични, като използват статистика от текущо изпълняваната програма за постигане на по-добри проценти на успех при предсказанията. Броячът на насищане е основа за всички текущи предиктори на разклонения. Първото предположение се решава статично или на случаен принцип. След като даден клон е бил взет или не, този резултат се съхранява в част от паметта. Следващият път, когато същият клон се появи, предикторът на клонове прогнозира същия резултат като преди.
Това естествено води до добри нива на прогнозиране за цикли. Има две версии за това. Ранните версии просто използваха един бит данни, за да покажат дали клонът е бил взет или не. По-късните версии използват два бита, за да посочат слабо или силно взет или невзет избор. Тази настройка все още може да предвиди резултата от извършване на цикъл, ако програмата се върне към него, като цяло увеличава процента на успех.
Модели за проследяване
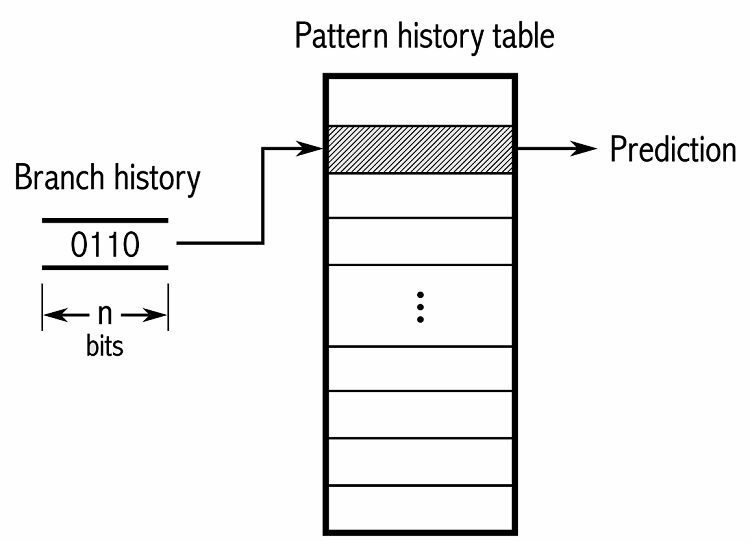
За да проследят моделите, някои предсказатели на клонове следят хронологията на направените избори. Например, да предположим, че един цикъл се извиква непрекъснато, но се завърта само около четири пъти, преди да излезе от цикъла. В този случай адаптивен предиктор на две нива може да идентифицира този модел и да предскаже, че ще се случи отново. Това увеличава процента на успеваемост още повече в сравнение с обикновен наситен брояч. Съвременните предсказатели на клонове надграждат това допълнително, като използват невронна мрежа за откриване и прогнозиране на модели.
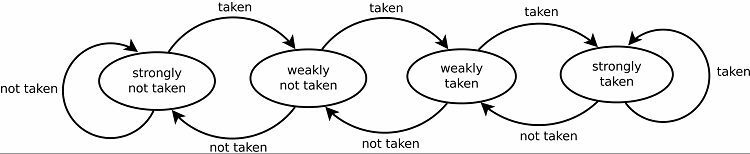
Някои предсказатели на разклонения използват множество алгоритми и след това сравняват резултатите, за да решат кое предсказание да използвате. Някои системи следят всяка инструкция за разклоняване поотделно в така нареченото предсказване на локално разклоняване. Други използват глобална система за прогнозиране на разклонения, за да проследят всички скорошни инструкции за разклоняване. И двете имат своите приложения и недостатъци.
Заключение
Предсказателят на разклонения е специална част от конвейерния процесор. Той се опитва да предвиди резултата от инструкция за разклоняване, преди действителната инструкция да бъде обработена. Това е основна функция на конвейерния процесор, тъй като позволява на процесора да поддържа конвейера наситен, дори ако не е сигурен какви инструкции трябва да бъдат изпълнени. Те не предлагат намаляване на производителността, когато са правилни. Съвременните алгоритми могат да бъдат точни при относително предвидими работни натоварвания до 97% от времето.
Няма идеален метод за прогнозиране, така че реализациите варират. Въздействието върху производителността от правенето на грешна прогноза зависи от дължината на конвейера. По-конкретно, дължината на тръбопровода, преди да може да се определи дали прогнозата е грешна. Това също зависи от това колко инструкции има във всеки етап на конвейер. Съвременните настолни процесори от висок клас имат около 19 етапа на конвейер и могат да изпълняват поне четири инструкции едновременно във всеки етап.