Téměř v každém počítačovém programu existují části kódu, které se větví do samostatných cest. Například příkaz if-then-else má dva možné výsledky. Tato prohlášení nepředstavují žádný problém pro sekvenční procesory, protože CPU zpracovává každý příkaz v pořadí. Větve představují velký problém pro zřetězené procesory, protože se provádí více instrukcí najednou.
Scénář
V případě programu s větveným příkazem se dvěma možnými výsledky nemohou být dvě možné cesty kódu na stejném místě. Zpracování potřebné k dokončení obou možností se bude lišit. Jinak by se program nerozvětvil. Pravděpodobně bude existovat značný počet větvených příkazů, které se použijí pouze jednou, například příkaz if.
Existují také větvené příkazy, které tvoří smyčku. I když tyto nemusí být číselně běžné jako jednorázové příkazy, obecně se statisticky opakují. Dá se předpokládat, že je pravděpodobnější, že vás pobočka vezme zpět do smyčky, než ne.
Proč je to problém?
Nezáleží na tom, jak je tento problém formulován v plně sekvenčním procesoru. Jednoduše to není problém. Která větev bude použita, je známo před zpracováním první části následující instrukce.
V zřetězeném procesoru jsou však následující instrukce zařazeny do fronty. Jsou již zpracovávány, když procesor ví, která větev se bere. Jak by tedy měl procesor zvládnout tento scénář? Možností je několik. Nejhorší je prostě čekat a nechat potrubí nečinné, zatímco čeká na odpověď, na kterou větev se má vzít. To by znamenalo, že pokaždé, když máte větvený příkaz, vždy ztratíte alespoň tolik cyklů procesorového času, kolik máte fází v potrubí.
Případně můžete zkusit spustit obě možnosti v potrubí a zahodit nesprávnou volbu. To by mělo poloviční trest za nicnedělání, ale stále by to znamenalo trest za výkon za každé větvení. Vzhledem k tomu, že moderní CPU mohou také spouštět instrukce mimo provoz, můžete se potenciálně pokusit spustit každou větvenou instrukci co nejdříve. Jeho výsledek je tedy znám dříve, než je potřeba. Tato možnost může být užitečná, ale není škálovatelná. Předpokládejme, že máte relativně vysokou hustotu větvených příkazů. V takovém případě je jednoduše nebudete moci spustit všechny dříve, aniž byste měli nějakou dobu nečinnosti.
Jak se tento problém skutečně řeší
Ve skutečnosti procesor obsahuje prediktor větvení. Prediktor větvení se pokouší uhodnout, jaký výsledek volby větvení bude přijat. Procesor pak předpokládá, že předpověď je správná a naplánuje instrukce. Pokud je prediktor větvení přesný, nedochází k žádnému trestu za výkon.
Pokud prediktor větvení udělá chybu, musíte propláchnout potrubí a začít zpracovávat skutečný výsledek. To má za následek o něco horší výkonovou penalizaci, než kdybychom nic neudělali a jen čekali na výsledek. Chcete-li dosáhnout nejlepšího výkonu, je důležité zajistit, aby byl prediktor větvení co nejpřesnější. K tomu existuje řada různých přístupů.
Odpovídající kód
Ve strojovém kódu je větev vždy volbou mezi čtením další instrukce nebo skokem na sadu instrukcí jinde. Některé rané implementace větvených prediktorů jednoduše předpokládaly, že všechny větve budou vždy nebo nikdy převzaty. Tato implementace může mít překvapivě dobrou úspěšnost, pokud kompilátory toto chování znají a jsou navrženy tak, aby upravily strojový kód tak, aby se nejpravděpodobnější výsledek shodoval s obecným nastavením procesoru předpoklad. To vyžaduje hodně ladění a úpravy návyků vývoje softwaru.
Další alternativou bylo naučit se ze statistiky, že smyčky se obecně berou a vždy přeskakují, pokud se větev vrátí zpět tok instrukcí a nikdy neskočit, pokud je skok vpřed, protože to by normálně byl statisticky méně pravděpodobný stav opuštění a smyčka. Jedná se o oba typy statické predikce větvení, kde je výsledek větvení předpovídán v době kompilace.
Dynamické prediktory větví
Moderní prediktory větví jsou dynamické a využívají statistiky z aktuálně spuštěného programu k dosažení lepší úspěšnosti predikce. Čítač saturace je základem pro všechny současné prediktory větví. První tip se rozhoduje staticky nebo náhodně. Jakmile je větev převzata nebo ne, výsledek se uloží do části paměti. Když se příště stejná větev objeví, prediktor větve předpovídá stejný výsledek jako předtím.
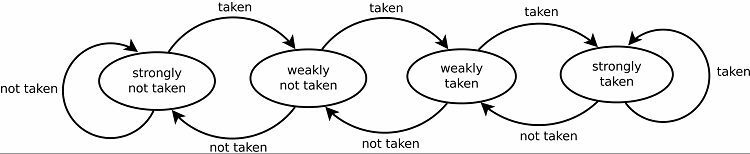
To přirozeně vede k dobrým předpovědím pro smyčky. Existují dvě verze tohoto. Rané verze jednoduše používaly jediný bit dat k označení, zda byla větev odebrána nebo ne. Pozdější verze používají dva bity k označení slabě nebo silně přijaté nebo nepřijaté volby. Toto nastavení může stále předvídat výsledek smyčky, pokud se k ní program vrátí, což obecně zvyšuje úspěšnost.
Sledovací vzory
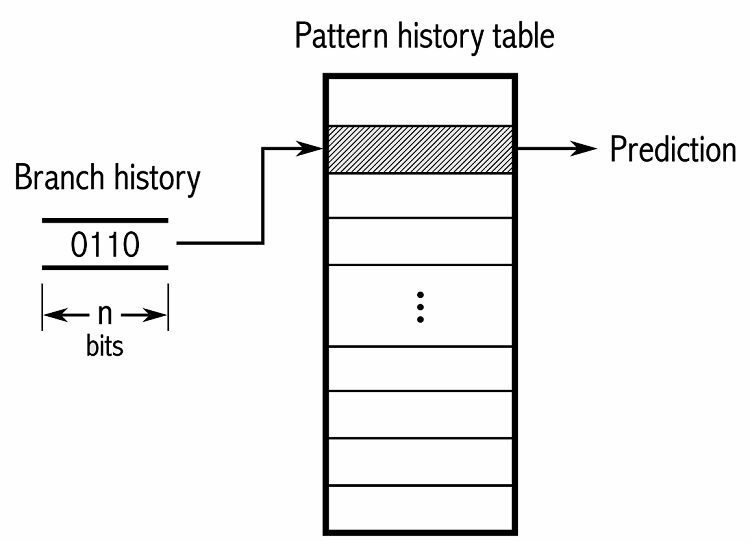
Aby bylo možné sledovat vzory, některé prediktory větví sledují historii toho, jaké volby byly přijaty. Předpokládejme například, že smyčka je nepřetržitě volána, ale před jejím přerušením se opakuje pouze čtyřikrát. V takovém případě může dvouúrovňový adaptivní prediktor identifikovat tento vzorec a předpovědět, že se bude opakovat. To zvyšuje úspěšnost ještě více přes jednoduchý saturovaný čítač. Moderní prediktory větví na tom dále staví pomocí neuronové sítě k rozpoznání a předpovědi vzorců.
Některé prediktory větví používají více algoritmů a poté porovnávají výsledky, aby se rozhodly, kterou předpověď použít. Některé systémy sledují každou instrukci větvení samostatně v tom, co se nazývá predikce místní větve. Jiní používají globální systém predikce větvení ke sledování všech posledních instrukcí větvení. Obojí má své využití i stinné stránky.
Závěr
Prediktor větvení je speciální součástí zřetězeného CPU. Pokouší se předpovědět výsledek větvené instrukce před zpracováním skutečné instrukce. Toto je základní funkce zřetězeného CPU, protože umožňuje CPU udržet zřetězení nasycené, i když si není jisté, jaké instrukce je třeba provést. Pokud jsou správné, nenabízejí žádné snížení výkonu. Moderní algoritmy mohou být přesné v relativně předvídatelných pracovních zátěžích až 97 % času.
Neexistuje žádná dokonalá metoda predikce, takže implementace se liší. Dopad na výkon chybné předpovědi závisí na délce potrubí. Konkrétně lze určit délku potrubí před tím, zda byla předpověď špatná. Záleží také na tom, kolik instrukcí je v každé fázi potrubí. Moderní špičkové stolní procesory mají přibližně 19 zřetězených fází a v každé fázi mohou spouštět alespoň čtyři instrukce současně.