První počítače byly zcela sekvenční. Každá instrukce, kterou procesor obdržel, musela být dokončena úplně, než mohla být spuštěna další. Většina instrukcí má pět fází: načtení instrukce, dekódování instrukce, provedení, přístup do paměti a zpětný zápis. Respektive tyto fáze dostanou pokyn, který je třeba dokončit, oddělit operaci od aktuálních hodnot provozován, proveďte operaci, otevřete registr, do kterého bude výsledek zapsán, a zapište výsledek do otevřeného Registrovat.
Každá z těchto fází by měla trvat jeden cyklus. Bohužel, pokud data nejsou v registru, musí být vyžádána z mezipaměti CPU nebo systémové RAM. To je mnohem pomalejší a přidává desítky nebo stovky hodinových cyklů latence. Mezitím musí vše ostatní počkat, protože žádná další data ani pokyny nelze zpracovat. Tento typ konstrukce procesoru se nazývá subskalární, protože běží méně než jedna instrukce na takt.

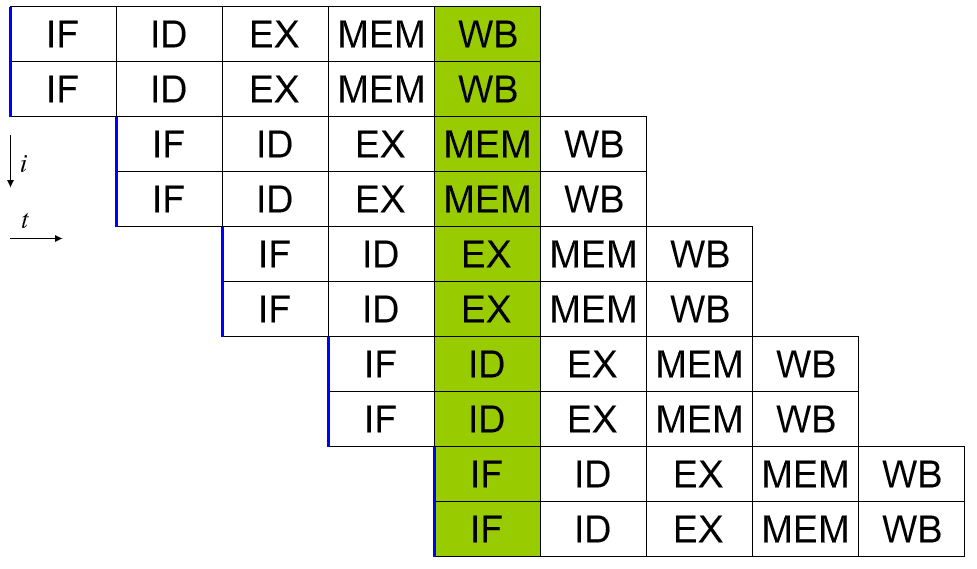
Zřetězení na skalární
Skalárního procesoru lze dosáhnout použitím systémového potrubí. Každá z pěti fází prováděné instrukce běží v různých bitech hardwaru ve skutečném jádru procesoru. Pokud jste tedy opatrní s daty, která vkládáte do hardwaru pro každou fázi, můžete každou z nich zaměstnat v každém cyklu. V dokonalém světě by to mohlo vést k 5násobnému zrychlení a k tomu, aby byl procesor dokonale skalární a spouštěl úplnou instrukci za cyklus.

Ve skutečnosti jsou programy složité a snižují propustnost. Například, pokud máte dvě sčítací instrukce „a = b + c“ a „d = e + f“, lze je bez problémů spustit v potrubí. Pokud však máte „a = b + c“ následované „d = a + e“, máte problém. Za předpokladu, že tyto dvě instrukce jsou bezprostředně po sobě, proces výpočtu nové hodnoty „a“ nebude dokončen, natož aby byl zapsán zpět do paměti předtím, než druhá instrukce přečte starou hodnotu „a“ a pak dá špatnou odpověď pro „d“.
Tomuto chování lze čelit zahrnutím dispečera, který analyzuje nadcházející instrukce a zajišťuje, že žádná instrukce, která je závislá na jiné, neproběhne příliš těsně za sebou. Ve skutečnosti spouští program ve špatném pořadí, aby to napravil. Funguje to, protože mnoho instrukcí se nemusí nutně spoléhat na výsledek předchozího.
Rozšíření potrubí na superskalární
Superskalární procesor je schopen spustit více než jednu úplnou instrukci za cyklus. Jedním ze způsobů, jak toho dosáhnout, je rozšířit potrubí tak, aby existovaly dva nebo více bitů hardwaru, které zvládnou každou fázi. Tímto způsobem mohou být v každé fázi potrubí v každém cyklu dvě instrukce. To samozřejmě vede ke zvýšené složitosti návrhu, protože hardware je duplikován, nicméně nabízí vynikající možnosti škálování výkonu.
Nárůst výkonu z rostoucích potrubí se však zatím efektivně škáluje. Tepelná a velikostní omezení kladou určitá omezení. Existují také značné komplikace plánování. Efektivní dispečer je nyní ještě kritičtější, protože musí zajistit, aby žádná ze dvou sad instrukcí nespoléhala na výsledek jakékoli jiné zpracovávané instrukce.
Prediktor větve je část dispečera, která se stává čím dál tím kritičtější, čím je procesor více superskalární. Některé pokyny mohou mít dva potenciální výsledky, z nichž každý vede k různým následujícím pokynům. Jednoduchým příkladem by bylo prohlášení „pokud“. "Pokud je to pravda, udělejte to, jinak udělejte tuto jinou věc." Prediktor větvení se pokouší předpovědět výsledek operace větvení. Poté preventivně naplánuje a provede pokyny podle toho, co považuje za pravděpodobný výsledek.
V moderních prediktorech větví je mnoho složité logiky, která může vést k úspěšnosti předpovědi větví řádově 98 %. Správná předpověď šetří čas, který mohl být promarněn čekáním na skutečný výsledek, nesprávná předpověď vyžaduje, aby předpovídaná instrukce a všechny jejich výsledky byly zahozeny a na jejich místě byly spuštěny skutečné instrukce, což je spojeno s mírnou penalizací za to, že právě čekal. Vysoká míra úspěšnosti predikce tak může výrazně zvýšit výkon.
Závěr
Počítačový procesor je považován za superskalární, pokud může provádět více než jednu instrukci za cyklus hodin. Rané počítače byly zcela sekvenční a spouštěly vždy pouze jednu instrukci. To znamenalo, že dokončení každé instrukce trvalo více než jeden cyklus, a proto byly tyto procesory subskalární. Základní pipeline, která umožňuje využití hardwaru specifického pro daný stupeň pro každý stupeň instrukce, může provést maximálně jednu instrukci za cyklus hodin, takže je skalární.
Je třeba poznamenat, že žádná jednotlivá instrukce není plně zpracována v jediném hodinovém cyklu. Stále to trvá nejméně pět cyklů. V procesu však může být více instrukcí najednou. To umožňuje propustnost jedné nebo více dokončených instrukcí na cyklus.
Superskalar by neměl být zaměňován s hyperscaler, který odkazuje na společnosti, které mohou nabídnout hyperscale výpočetní zdroje. Hyperscale computing zahrnuje schopnost plynule škálovat hardwarové zdroje, jako je výpočetní technika, paměť, šířka pásma sítě a úložiště, podle potřeby. To se obvykle vyskytuje ve velkých datových centrech a prostředích cloud computingu.