Během posledního měsíce jsem se věnoval aplikacím Zkratky a Automator na iOS a macOS. Oba jsou velmoci, pokud jde o automatizaci v ekosystému Apple, a počínaje macOS Monterey letos na podzim budou Shortcuts nejpoužívanější aplikací pro automatizaci na všech zařízeních Apple. Proto jsem chtěl tento článek věnovat diskuzi o velmi silném tématu: Použití regulárního výrazu s aplikací Zkratky.
I když mám nějaké zázemí v informatice a programování, nějak jsem se nikdy nesetkal s regulárním výrazem. Možná mě to jméno vyděsilo, možná to byl kód, což je jeden z nejméně čitelných kódů, jaké jsem kdy viděl.
Ať už je to jakkoli, rozhodl jsem se podívat dále na regulární výraz poté, co jsem v posledních několika měsících pokryl aplikaci Zkratky. Zjistil jsem, že mnoho omezení, na která jsem narážel u zkratek a také u Automatoru, lze překonat pomocí regulárního výrazu.
Jinými slovy, nebylo to tak, že by tyto aplikace postrádaly funkce, ale že mi chybělo vzdělání.
Takže v dnešním příspěvku se vy a já společně naučíme detaily regulárního výrazu. Tímto způsobem můžete z každé z těchto aplikací vytěžit maximum.
Pokryjeme základy regulárního výrazu (začneme tím, co to je), co s ním můžete dělat v aplikaci Zkratky, některé webové stránky a zdroje, které můžete použít, pokud se sami nechcete učit regulární výraz, a poté se podíváme na základní koncepty a mechaniku regulárních výrazů Jazyk.
Dobře, můžeme začít!
Obsah
-
Co jsou regulární výrazy (tj. regulární výraz)?
- Věci, které můžete dělat s regulárním výrazem
- Jak můžete použít regulární výraz s aplikací Zkratky?
- Pomocí regex101.com otestujte své regulární výrazy
- Pokud se nechcete učit, jak používat regulární výraz v aplikaci Zkratky, přečtěte si toto
-
Regulární výraz pro začátečníky: Začněte používat regulární výraz pomocí klávesových zkratek
- Jaké jsou příchutě regulárních výrazů?
- Webové stránky a odkazy, které vám pomohou začít se učit regulární výrazy pomocí zkratek
- Jak provést základní textové vyhledávání pomocí regulárního výrazu pomocí zkratek
- Přidání proměnných komponent do vyhledávání podle regulárních výrazů
- Rozsahy mohou rozšířit vaše vyhledávání
- Jak vyloučit slova a znaky z vyhledávání regulárních výrazů pomocí zkratek
- Zástupné znaky vám mohou poskytnout více možností vyhledávání
- Pomocí kvantifikátorů zadejte délku textu, který hledáte
- Existuje několik dalších kvantifikátorů, o kterých budete chtít vědět
- Hledejte znaky na začátku a na konci řetězce textu
- Ukládejte textové řetězce pomocí funkce seskupování regulárního výrazu se zkratkami
-
Co teď?
- Jak bys to rozebral?
-
Začněte používat regulární výraz se zkratkami a posuňte svou automatizaci na další úroveň
- Související příspěvky:
Co jsou regulární výrazy (tj. regulární výraz)?
Regulární výraz neboli „regex“ je kousek kódu, který můžete použít k vyhledání části textu uvnitř větší části textu.
V případě, že to nevíte, kus textu v jiném textu se v programování nazývá „řetězec“. Například slovo „zelená“ je řetězec znaků z textu „Dnes jsem měl na sobě zelené kalhoty“.
Jinými slovy, regulární výraz je způsob, jak najít řetězec textu ve větším textu. A protože regex je napsán v kódu, můžete jej použít k provádění některých docela složitých operací.
Pokud například chcete vyhledat slovo „e-mail“, můžete snadno napsat kód regulárního výrazu, který vyhledá e-mail.
Pokud však chcete najít e-mail, který je uvnitř odstavce, a nevíte, co přesně tento e-mail je, budete muset vyhledat řetězec textu, který je naformátován jako e-mail. tj. řetězec, který následuje za „[e-mail chráněný]" formát.
Nyní řekněme, že nechcete najít pouze jeden e-mail z odstavce, ale také každý e-mailem. Možná je budete chtít rychle zkopírovat někam jinam, aktualizovat je na nový formát nebo je nahradit tak, aby všechny říkaly „[e-mail chráněný]“.
Jak budete stále zběhlejší a zkušenější s regulárním výrazem, budete schopni dělat všechny tyto věci a ještě více.

Věci, které můžete dělat s regulárním výrazem
Dobře, takže možná příklady s e-mailem, které jsem právě uvedl, nejsou tak praktické. Nebojte se – to je daleko od limitu toho, čeho můžete dosáhnout pomocí regulárního výrazu v aplikaci Zkratky.
Všeobecně řečeno, vše, co regulární výraz dokáže, spadá do jedné z těchto čtyř kategorií:
- Najděte řetězec textu ve větším kusu textu (tj. hledání slova/řetězce/typu řetězce na stránce textu).
- Potvrďte, že textový řetězec odpovídá požadovanému formátu (tj. zkontrolujte, zda je textový řetězec správně psán velkými písmeny/řazenými/interpunkčními).
- Nahraďte nebo vložte text do určité oblasti textu.
- Rozdělte řetězec textu v určených bodech (např. rozdělte část textu pokaždé, když je tam čárka).
Úroveň hloubky, kterou můžete použít k interakci s každým z těchto druhů funkcí, a způsob, jakým je můžete kombinovat, činí z regulárního výrazu neuvěřitelně mocný nástroj pro analýzu a manipulaci s textem.
Jak můžete použít regulární výraz s aplikací Zkratky?
Dobře, takže teď snad máte základní představu o tom, k čemu se používá regex. Je to typ kódu, který můžete použít k vyhledávání textu, i když přesně nevíte, o jaký text jde.
Jak vám to tedy pomůže v Zkratkách? Podobně jako přidávání skriptů do zkratek je to způsob, jak přejít od základní automatizace (Napište mi, až se otevřou přední dveře) na pokročilejší možnosti (Automaticky vytvořit událost kalendáře pro mé schůzky pokaždé, když dostanu z práce e-mail na schůzku Zoom).
Ke kontrole správnosti zadání můžete použít regulární výraz se zkratkami. Pokud například vytvoříte zástupce, který funguje pouze s adresami URL, můžete použít regulární výraz na začátku zástupce, abyste se ujistili, že uživatel spouští automatizaci na adrese URL.
Regulární výraz můžete kombinovat se skriptováním a vytvářet tak výkonné zkratky. Například, tato zkratka používá regex a skriptování k přeměně čárového kódu na adresu URL vašeho oblíbeného obchodu.
Když používáte aplikaci Zkratky na Macu (přichází na podzim 2021), můžete použít regulární výraz k provádění dávkových akcí u kusu textu. Můžete například zkopírovat všechny e-maily ve vybraném textu jako uspořádaný seznam. Nebo můžete všechna jména v dokumentu nahradit znaky „*“, abyste zajistili soukromí.
Můžete dokonce zkopírovat část textu z jedné aplikace, přeformátovat jej tak, aby odpovídal preferencím jiné aplikace, a poté jej vložit do jiné aplikace, to vše jediným kliknutím pravým tlačítkem.
Jinými slovy, regulární výraz vám dává úplnou kontrolu nad zpracováním textu pomocí aplikace Zkratky. To na první pohled nemusí znít moc užitečně, ale teď, když víte, že existuje, si jistě začnete všímat, kolik zkratek by se dalo touto funkcí vylepšit. A také si všimnete, že mnoho zkratek bez regulárního výrazu ani není možné.
Pomocí regex101.com otestujte své regulární výrazy
Jakmile začnete používat regulární výraz se zkratkami, dostanete se do bodu frustrace:
Je opravdu těžké otestovat váš regex kód. A to není jedinečné pro regulární výraz. Testování čehokoli pomocí aplikace Zkratky je trochu utrpení. Jediný způsob, jak toho dosáhnout, je spustit zástupce. Tato metoda není špatná, když právě testujete vestavěné funkce zkratek.
Ale pro testování kódu to neumožňuje kontrolu řádek po řádku a nenabízí mnoho zpětné vazby.
K tomu bych doporučil použít regex101.com. Je to stránka, do které můžete zadávat regulární kód v reálném čase. Můžete také zadat text do textového editoru na stejné webové stránce. Při psaní každého z nich uvidíte, zda váš regulární výraz funguje, proč funguje nebo nefunguje, a získáte informace o nalezených shodách.
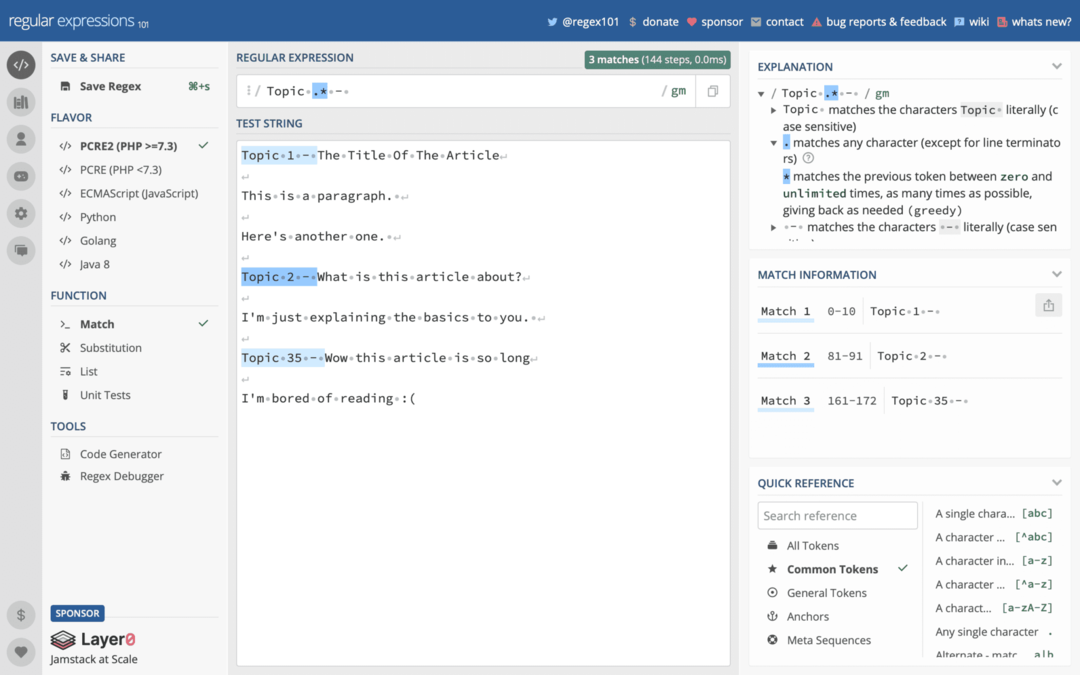
regex101.com používá jinou variantu regulárního výrazu než tu, kterou podporují zkratky (více o tom za minutu), ale je dostatečně blízko, že byste neměli narazit na příliš mnoho problémů.
Použití tohoto nástroje je skvělé, protože tam můžete nejprve napsat svůj regulární výraz a poté jej zkopírovat do aplikace Zkratky, jakmile bude fungovat, jak má.
Pokud se nechcete učit, jak používat regulární výraz v aplikaci Zkratky, přečtěte si toto
Chápu to – ne každý se bude chtít naučit používat regulární výraz se zkratkami. Je to dovednost, a to znamená, že to bude vyžadovat čas a praxi. Není to zdaleka tak jednoduché jako ostatní funkce přetahování v aplikaci Zkratky.
Bez obav! I když z aplikace Zkratky nebudete moci vytěžit tolik jako někdo, kdo si na naučení regulárního výrazu najde čas, stále máte k dispozici možnosti. Konkrétně existují weby a stránky online, kde lidé vytvořili seznam kousnutí regulárního kódu, který můžete zkopírovat a vložit do aplikace Zkratky.
Zde je několik odkazů, které můžete zkontrolovat, pokud se nechcete učit regulární výraz:
- https://www.shortcutfoo.com/app/dojos/regex/cheatsheet
- https://www.reddit.com/r/shortcuts/comments/9zo24n/regex_cookbook_for_shortcuts_reusable_regex_to/
- https://www.reddit.com/r/shortcuts/comments/b5labq/match_text_examples_for_the_beginner_a_regex/
- http://www.rexegg.com/regex-cookbook.html
Stačí si přečíst tyto odkazy a měli byste být schopni najít běžná řešení regulárních výrazů pro zkratky, které chcete vytvořit. Toto nebude možnost bez vzdělání, protože bude ještě chvíli trvat, než pochopíte, na co se díváte. Ale je to mnohem jednodušší a ideální řešení pro někoho, kdo nemá čas vkládat regulární výrazy.
To znamená, že musím přiznat, že regex není příliš těžké se naučit, zvláště pokud máte nějaké zkušenosti s kódem shellu nebo programováním pro začátečníky. Regulární výraz mi zpočátku připadal jako blábol, ale po hodině čtení článků a hraní si s regex101.com jsem mohl začít psát regulární výrazy pro své zkratky.
Je to jen známá věc – až se na to budete dívat dostatečně dlouho, přestane to vypadat tak divně. Takže pokud máte čas a jste jen vystrašení, nebuďte!
Regulární výraz pro začátečníky: Začněte používat regulární výraz pomocí klávesových zkratek
Dobrá, dost předmluvy! Měli byste mít představu o tom, co je regex, co umí, proč byste se ho měli naučit a dostatek informací, abyste se rozhodli, zda se ho chcete naučit. Nyní se pustíme do toho nejzákladnějšího.
Níže je spousta obsahu, ale nebojte se! Tento článek bude spíše studijním průvodcem. Doporučuji prolistovat každou sekci, abyste si udělali představu o mechanice, kterou regex používá. To by vám také mělo pomoci zamotat hlavu, pokud stále nevíte, co je regex.
Jakmile si vše prolétnete, doporučuji otevřít regex101.com a pohrát si s každým z nástrojů v každé sekci níže. To vám pomůže vidět, jak koncepty vypadají v praxi, a také zlepší vaši paměť. Poté, co to uděláte, můžete tento článek považovat pouze za referenční bod – něco, k čemu se můžete vrátit, když zapomenete na útržky regulárního výrazu.
OK Pojďme!
Jaké jsou příchutě regulárních výrazů?
Nejprve se podíváme na příchutě regulárních výrazů. Nebojte se – to neovlivní vaše každodenní používání regulárního výrazu se zkratkami. Je to jen něco, co je třeba si uvědomit, než začnete.
Existují různé verze regulárního výrazu, které jsou známé jako „příchutě“. Tyto různé verze jsou stále velmi podobné. Pokud se dokážete naučit číst a psát jednu příchuť, měli byste být schopni přečíst kteroukoli z nich. Budou jen malé rozdíly v tom, jak by měl být váš regulární kód naformátován.
V programování jsou tato specifika formátování známá jako „syntaxe“. Je to jen způsob, jakým musíte napsat svůj kód, aby tento kód pochopila aplikace, do které jej zapisujete.
Zde je důvod, proč na syntaxi záleží
"Ahoj příteli, jaký máš den?"
“, jdeš příteli? jak tvůj hej den"
Obě věty mají stejná slova, znaky a mezery. Pouze jeden však dává smysl, a to proto, že se řídí konvenční syntaxí.
Při kódování může jeden programovací jazyk rozumět první verzi, ale ne druhé. Pro jiný programovací jazyk však může druhý dávat úplný smysl, zatímco první vypadá jako blábol. Někomu, kdo umí anglicky, však pravděpodobně porozumíte záměru obou linií, i když člověku dá trochu práce, aby pochopil význam.
Tak (tak nějak) vypadají různé příchutě regulárního výrazu. Všechny budou vypadat trochu jinak a trochu podobně jako vy. Musíte však používat správnou příchuť pro aplikaci, kterou používáte, jinak tato aplikace nebude mít ponětí, co jste napsali.
Aplikace Zkratky rozumí příchuti regulárního výrazu ICU, takže to je příchuť, kterou budete chtít použít. Stránka regex101.com má několik různých příchutí, ze kterých si můžete vybrat v levé části stránky. Používá však PCRE, což je docela podobné JIP.
Je důležité vědět, že existují různé příchutě regulárního výrazu, protože nepochybně online narazíte na různé příchutě. Pokud najdete kousek regulárního výrazu, který chcete ukrást, ale nemůžete ho zprovoznit pomocí zkratek nebo prostě nevypadá správně, zkontrolujte, v jaké příchuti je napsán!
Webové stránky a odkazy, které vám pomohou začít se učit regulární výrazy pomocí zkratek
Další věc, kterou chci pokrýt, než začneme zkoumat skutečnou mechaniku psaní regulárního výrazu, jsou zdroje. V žádném případě netvrdím, že tento příspěvek je vyčerpávajícím zdrojem o učení regulárního výrazu. Má to být jen užitečný výchozí bod pro ty, kteří chtějí používat regulární výraz se zkratkami.
Pokud se chcete ponořit hlouběji do regulárního výrazu nebo máte pocit, že vám tento článek neposkytuje potřebnou pomoc, můžete se podívat na některé z těchto článků, průvodců a nástrojů:
- https://regex101.com – Web, který vám umožní otestovat váš regex kód v reálném čase.
- https://www.shortcutfoo.com/app/dojos/regex/cheatsheet – Cheat sheet, když zapomenete, co každá postava dělá
- http://www.rexegg.com – Tato webová stránka je komplexním zdrojem informací o všem, co potřebujete vědět o regulárním výrazu. Podívejte se na toto, pokud se chcete naučit regex.
- https://scottwillsey.com/blog/ios/regex1/ – Toto je čtyřdílná série blogů o používání regulárního výrazu se zkratkami. Zaujímám velmi odlišný přístup od tohoto průvodce, takže by to mělo být pěkným doprovodným seriálem k tomuto článku.
- Stack Overflow a Reddit jsou dobré webové stránky pro sdílení vašich regulárních otázek a pokroku, abyste získali rady a odpovědi.
Tyto zdroje se liší od zdrojů uvedených v Pokud se nechcete naučit používat regulární výraz v aplikaci Zkratky sekce, protože všechny budou vyžadovat, abyste se skutečně začali učit regulární výrazy. Jsou obsáhlejší, zatímco ostatní jsou pouze referenčními body.
Jak provést základní textové vyhledávání pomocí regulárního výrazu pomocí zkratek
V pořádku! Nyní jsme se dostali do bodu, na který všichni čekali: Naučíme se základy používání regulárního výrazu se zkratkami.
Začněme základním vyhledáváním, protože to je ta nejjednodušší věc, kterou můžete s regulárním výrazem udělat. Jak již bylo zmíněno, doporučuji mít regex101.com otevřený na jiné kartě, abyste jej mohli sledovat.
Ve své nejzákladnější podobě bude regulární výraz hledat (nebo zápas) cokoliv do něj napíšete. Například kdybych psal V pořádku jako můj regex kód by v této příručce našel každý výskyt slova „V pořádku“.
Na malých a velkých písmenech, mezerách a interpunkci záleží. To znamená, že V pořádku, v pořádku, V pořádku!, a V pořádku , všechny přinesou různé výsledky.
A to je vše! Kdykoli zadáte něco do vyhledávání podle regulárního výrazu bez použití jakýchkoli speciálních znaků, regulární výraz bude odpovídat všemu, co přesně odpovídá tomu, co jste zadali.
Má to jeden háček! Některé znaky na vaší klávesnici jsou také speciální regulární znaky. To znamená, že vykonávají nějakou funkci v regex kódu.
The ? symbol je jedním z takových znaků. Používá se v regex kódu jako kvantifikátor. Pokud se tedy pokusíte hledat „V pořádku?“ psaním V pořádku? jako váš regex kód nedostanete to, co chcete.
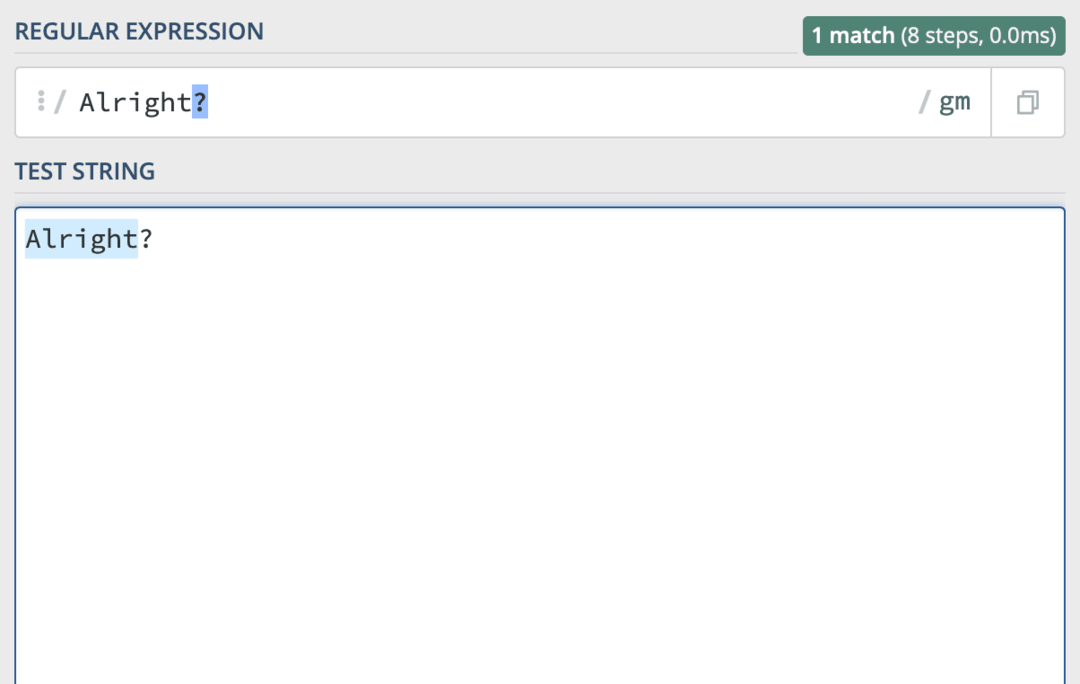
Chcete-li to opravit, musíte zadat, že chcete použít „?“ jako řetězec, nikoli jako speciální znak. Chcete-li to provést pro tuto postavu nebo kteroukoli jinou, přidejte a \ symbol těsně před znakem, jehož speciální vlastnosti chcete zrušit.
Takže pokud chcete hledat "V pořádku?" s regulárním výrazem bude váš kód vypadat takto:
V pořádku\?
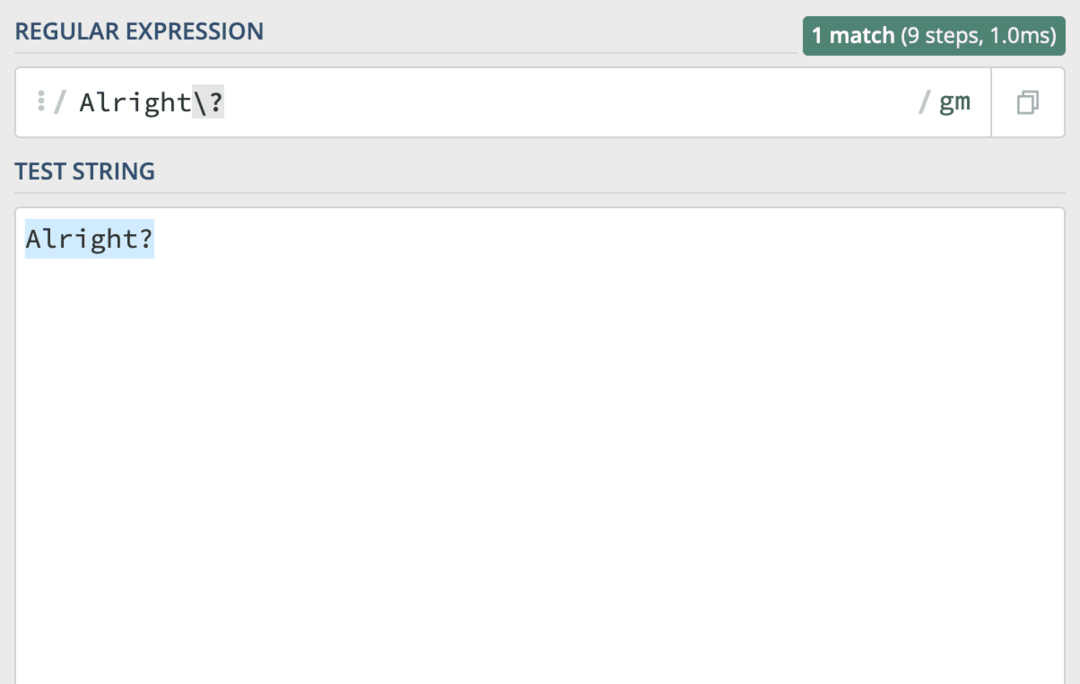
Pokud si nejste jisti, zda je konkrétní znak regulárním výrazem považován za speciální znak, můžete to zkontrolovat tento cheat list pro všechny speciální znaky v regulárním výrazu.
Vyhledejte více než jedno slovo pomocí znaku „nebo“.
Další důležitou součástí hledání řetězců pomocí regulárního výrazu je použití funkce „nebo“. Jedná se o znak, který můžete umístit mezi dvě slova/znaky a říci: „Přiřaď toto nebo toto“.
Pokud například chci v textu vyhledat slovo „v pořádku“ a „v pořádku“, použil bych | charakter. Jako tak:
Dobře|dobře
Pokud máte problém najít | charakter, podržte posun klávesu dolů a stiskněte \ klíč. Je to nad vrátit se na většině klávesnic.
Přidání proměnných komponent do vyhledávání podle regulárních výrazů
Dobře, takže teď, když víte, jaký je neutrální regulární výraz, je čas vybrat si svou první speciální postavu. To by byly hranaté závorky, což jsou tyto věci [].
Cokoli vložíte do těchto závorek, bude považováno za proměnnou složku vašeho vyhledávání regulárních výrazů. Do hranatých závorek můžete vložit libovolný počet znaků, ale pro každou shodu bude platný pouze jeden.
Dobře, zní to trochu složitě, ale není! Jak to vypadá v praxi:
-
[V pořádkubude odpovídat pouze slovu „V pořádku“. Tak nějak nesmyslně. -
[AB] Dobřebude odpovídat „V pořádku“ i „Blright“. -
Dobře[iouxyz]ghtbude odpovídat „V pořádku“, „V pořádku“, „V pořádku“, „V pořádku“ a tak dále.
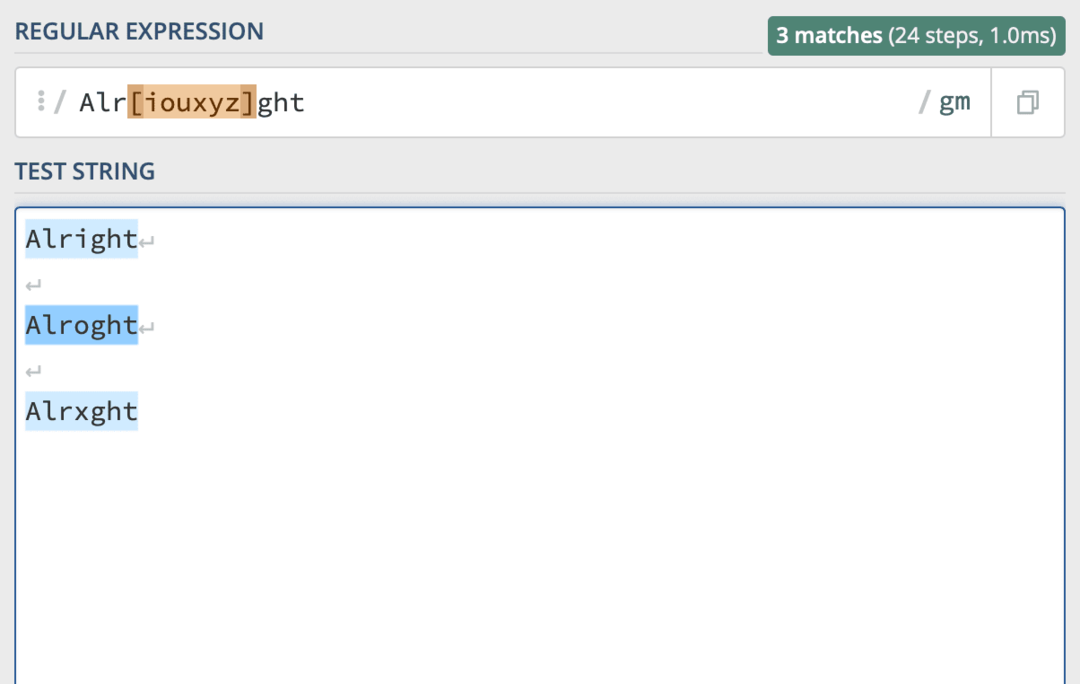
Znaky v hranatých závorkách můžete kombinovat a také použít více hranatých závorek na stejném řádku regulárního výrazu. [AB]r[i1]gh[tuvwxyz] je platný kus regulárního výrazu. Doufejme však, že to nebude vypadat tak chaoticky, jak to mohlo vypadat před pár minutami!
Rozsahy mohou rozšířit vaše vyhledávání
Dalším kouskem regulárního výrazu, který bude užitečný se zkratkami, je rozsah. Rozsahy vám umožňují určit rozsah znaků, které přijmete.
V předchozí části jste si možná všimli, že moje závorky obsahovaly mnoho po sobě jdoucích písmen. Nejdelší byl [tuvwxyz]. Tato písmena se objevují v abecedě ve stejném pořadí, těsně vedle sebe.
To znamená, že bych mohl místo vypisování použít rozsah. To by vypadalo takto:
dobře[t-z]
Tento kousek regex kódu bude dělat to samé jako dobře[tuvwxyz]. Je to prostě přehlednější a jednodušší na psaní.
Stejný rozsah byste mohli nahradit [a-z] pokud byste chtěli, aby akceptoval jakékoli malé písmeno z abecedy. Nebo můžete použít [0-9] pokud byste chtěli přijmout libovolné jednomístné číslo.
Můžete také kombinovat rozsahy ve stejné závorce. Například toto Dobře[i-ux-z]ght přijme „V pořádku“, „V pořádku“, „V pořádku“ a „V pořádku“, ale nebude akceptovat „V pořádku“ nebo „V pořádku“.
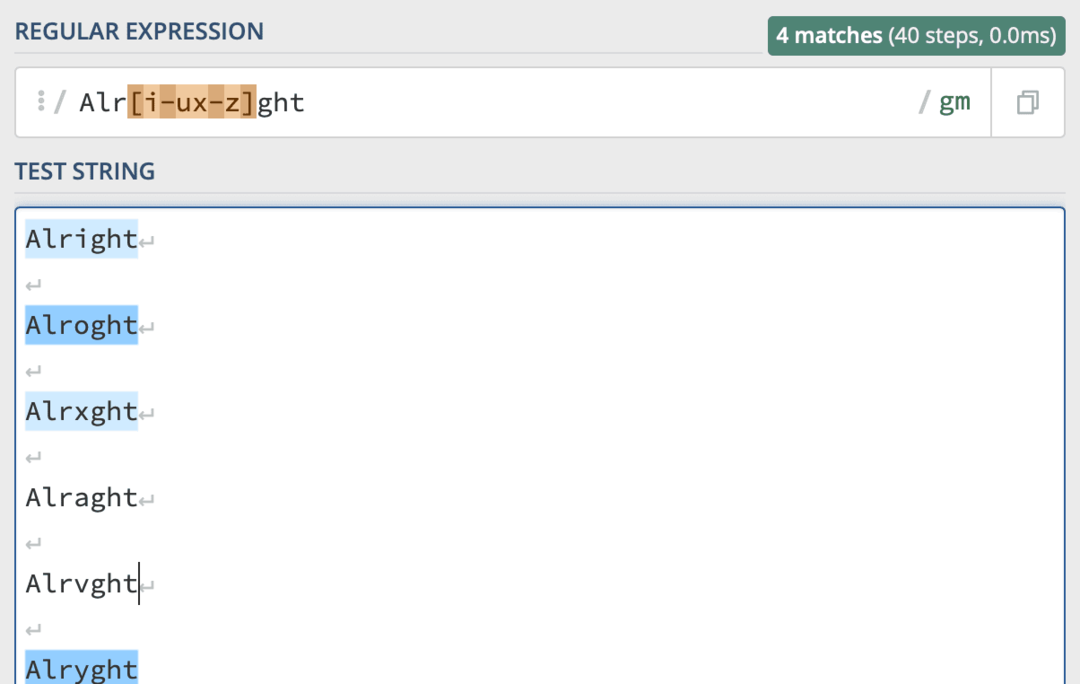
Existují další varianty slova „V pořádku“, které tento kód mimochodem přijme, a mnoho dalších, které ne. To je jen krátký výběr, aby věci zůstaly krátké.
Pokud máte problém pochopit co [i-ux-z] znamená, že by mohlo pomoci vidět to napsané takto:
[i-u, x-z]
To není správná syntaxe regulárního výrazu – k oddělení rozsahů byste neměli používat čárku. Ale doufejme, že to pomůže dát větší smysl!
K oddělení rozsahů nepotřebujete čárky v regulárním výrazu a nemusíte dávat rozsahy těsně vedle sebe. Mohl bys to změnit na [i-uabcx-z]. To by akceptovalo stejné rozsahy jako dříve plus znaky „a“, „b“ a „c“.
Jak vyloučit slova a znaky z vyhledávání regulárních výrazů pomocí zkratek
Dobře, takže teď se někam dostáváme! Pokud jste postupovali podle tohoto článku až do tohoto bodu, měli byste být schopni podívat se na níže uvedený kód a pochopit, k čemu se hodí:
App[p-r]le[Tt]ool[BbLF]ox
Pokud to dokážete přečíst, pak víte, že tento kus kódu regex obsahuje mnoho možných variant slova „AppleToolBox“. Co kdybychom tedy chtěli snížit počet přijatých variant, aniž bychom změnili náš sortiment?
Zde nastupuje postava „ne“. Vypadá to takto: ^. Pokud máte problém to najít na klávesnici (jako já), podržte posun a stiskněte tlačítko 6 klíč na klávesnici.
Chcete-li použít ^ znak, umístěte jej na začátek znaku, který chcete vyloučit.
Je v tom háček! The ^ znak nefunguje mimo funkci regulárního výrazu. Nemůžete jej pouze umístit před písmeno „A“, aby bylo toto písmeno vyloučeno z vašeho vyhledávání. Kód regulárního výrazu ^A bude pouze hledat velké „A“.
Místo toho jej zkombinujte se závorkami a dalšími speciálními znaky regulárního výrazu.
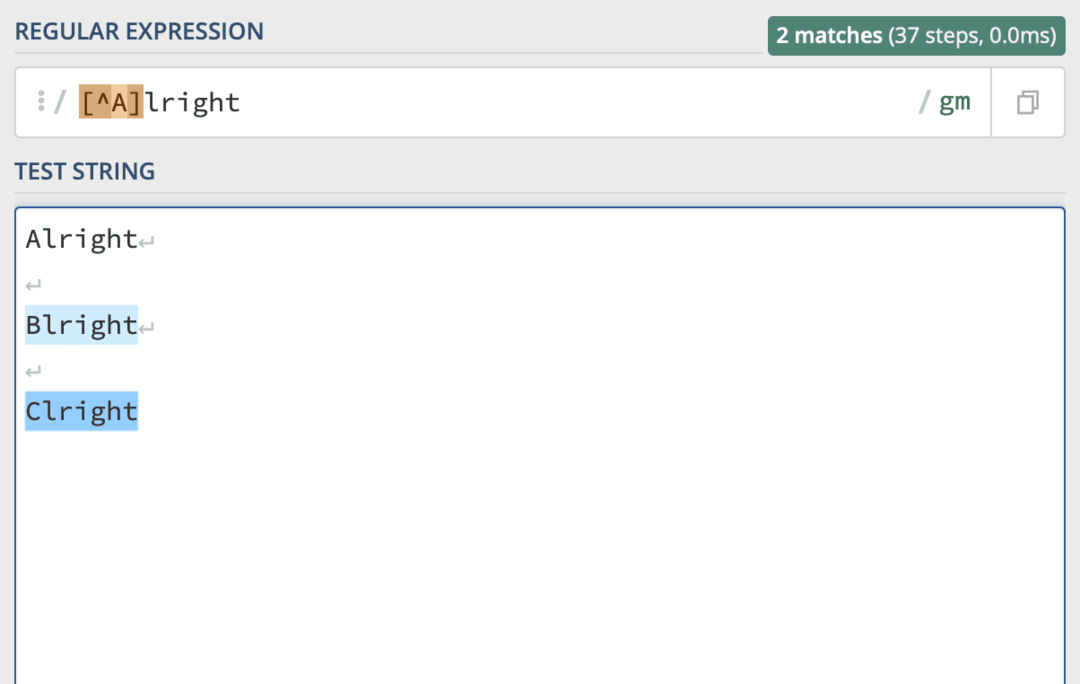
Pokud bych například chtěl vyhledat jakýkoli výskyt slova „V pořádku“, který nezačíná písmenem „A“, použil bych kód [^A] Dobře.
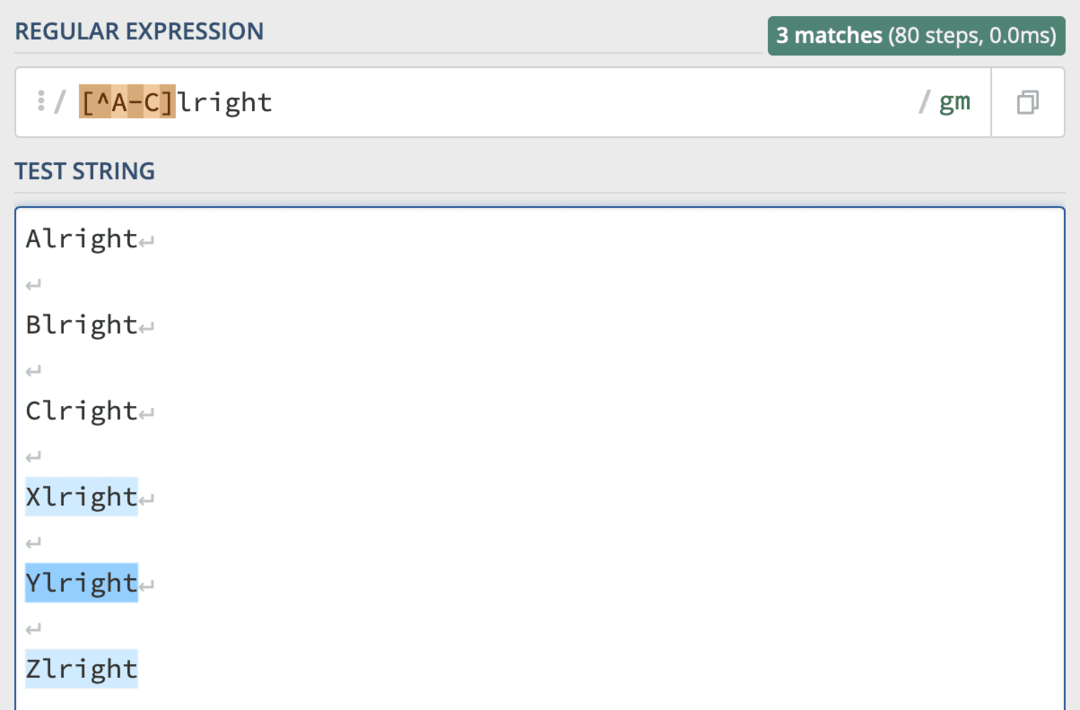
Můžete jej dokonce kombinovat s řadami! Stačí jej umístit na začátek vaší závorky a vše v této závorce, včetně rozsahů, bude z vašeho vyhledávání vyloučeno. Jako tak:
Co když chcete z vyhledávání vyloučit konkrétní slovo?
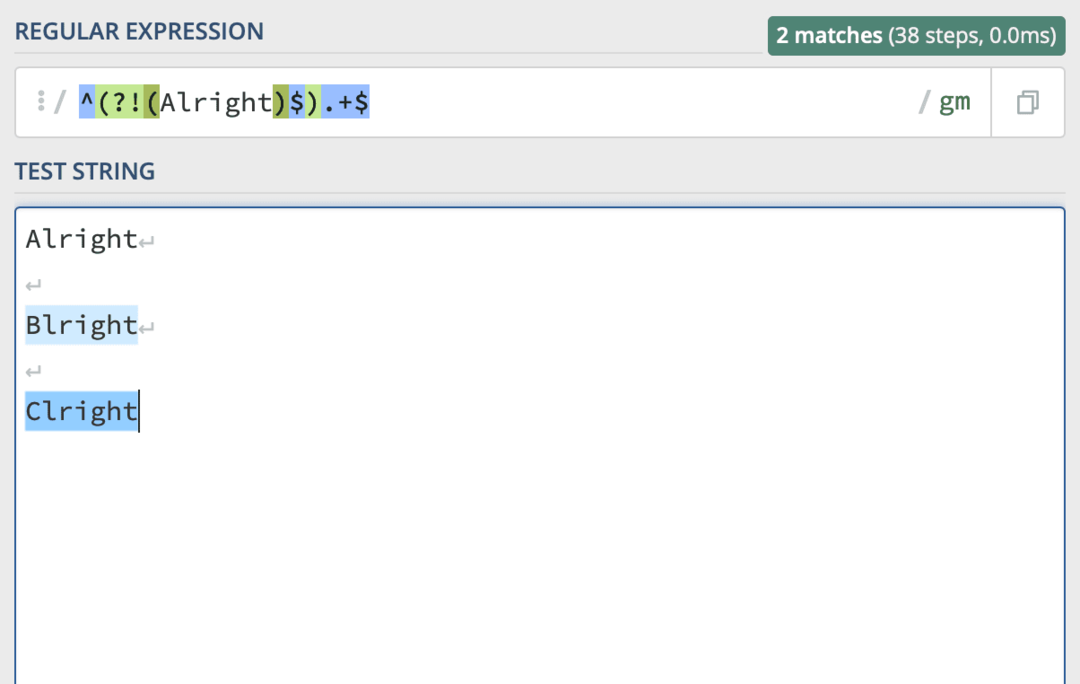
Tuto informaci jsem těžko hledal. Uživatel Stack Overflow však měl řešení a vypadá takto:
^(?!(slovo)$).+$
Stačí vyměnit slovo s jakýmkoli slovem, které chcete z vyhledávání vyloučit. Jako tak:
Můžete si přečíst příspěvek Stack Overflow tady pokud se chcete dozvědět více o tomto konkrétním případu použití.
Zástupné znaky vám mohou poskytnout více možností vyhledávání
To nás přivádí k zástupným znakům. Zástupný znak, což je tečka ., se používá k reprezentaci libovolného jednotlivého znaku, bar none. Pokud jen napíšete . jako váš regex kód se zkratkami vrátí každý jednotlivý znak v těle textu jako samostatnou shodu.
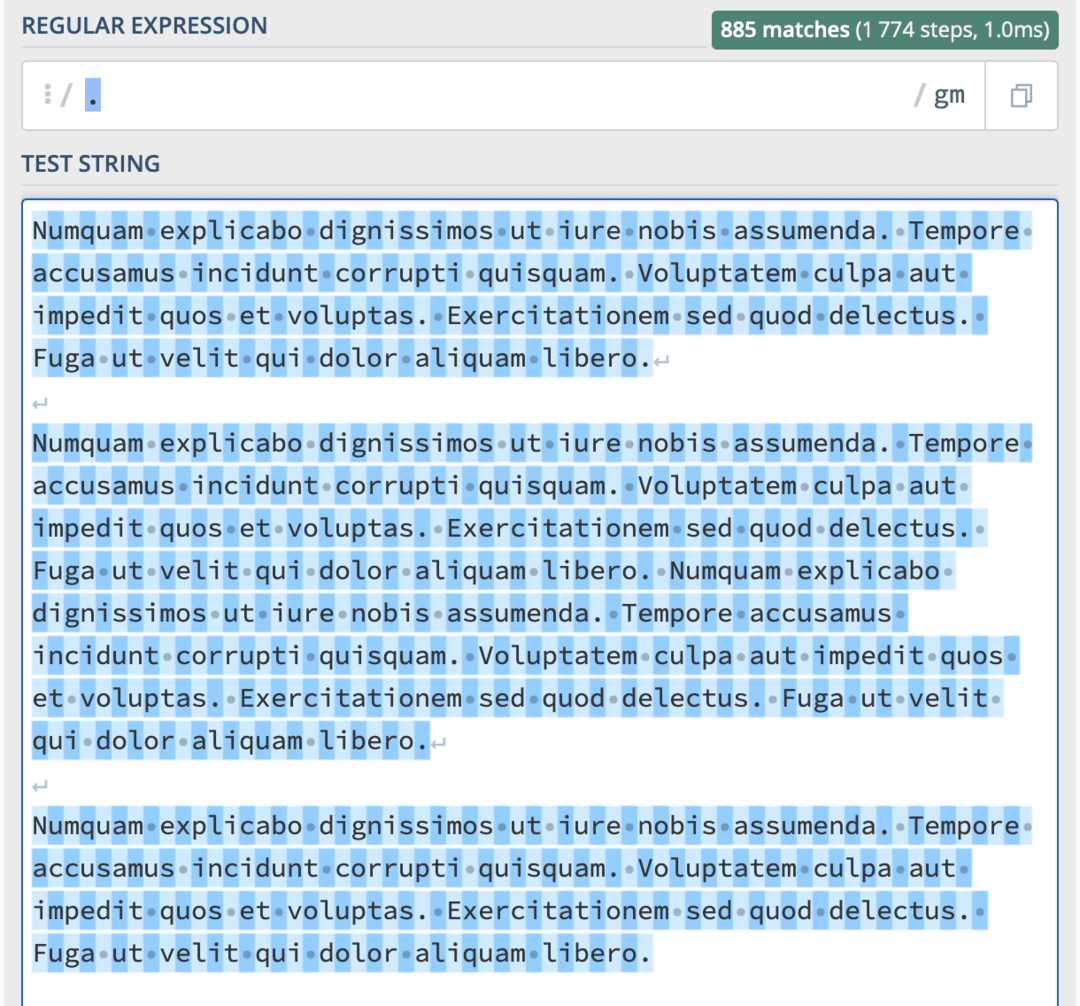
Samozřejmě bych to nedoporučoval používat pro tento účel! Místo toho jej doporučuji použít místo jednoho znaku ve slově. Například, Dobře bude odpovídat „V pořádku“, „Alrxght“, „Alr
A to je do značné míry vše! Zástupný znak je docela snadno pochopitelný. Hodí se ke všemu! Díky tomu je užitečné najít řetězce, které odpovídají konkrétnímu formátu a zároveň mají jedinečné znaky.
Například e-maily budou všechny vypadat velmi podobně, aniž by byly stejné. Zástupný znak vám může pomoci kombinovat prvky, o kterých víte, že tam budou (jako „.com“ a „@“), se znaky, které neznáte (jako „my_email567“, iCloud nebo „Gmail“).
Dalším zajímavým případem použití je použití . znak k vyhledání řetězců určité délky.
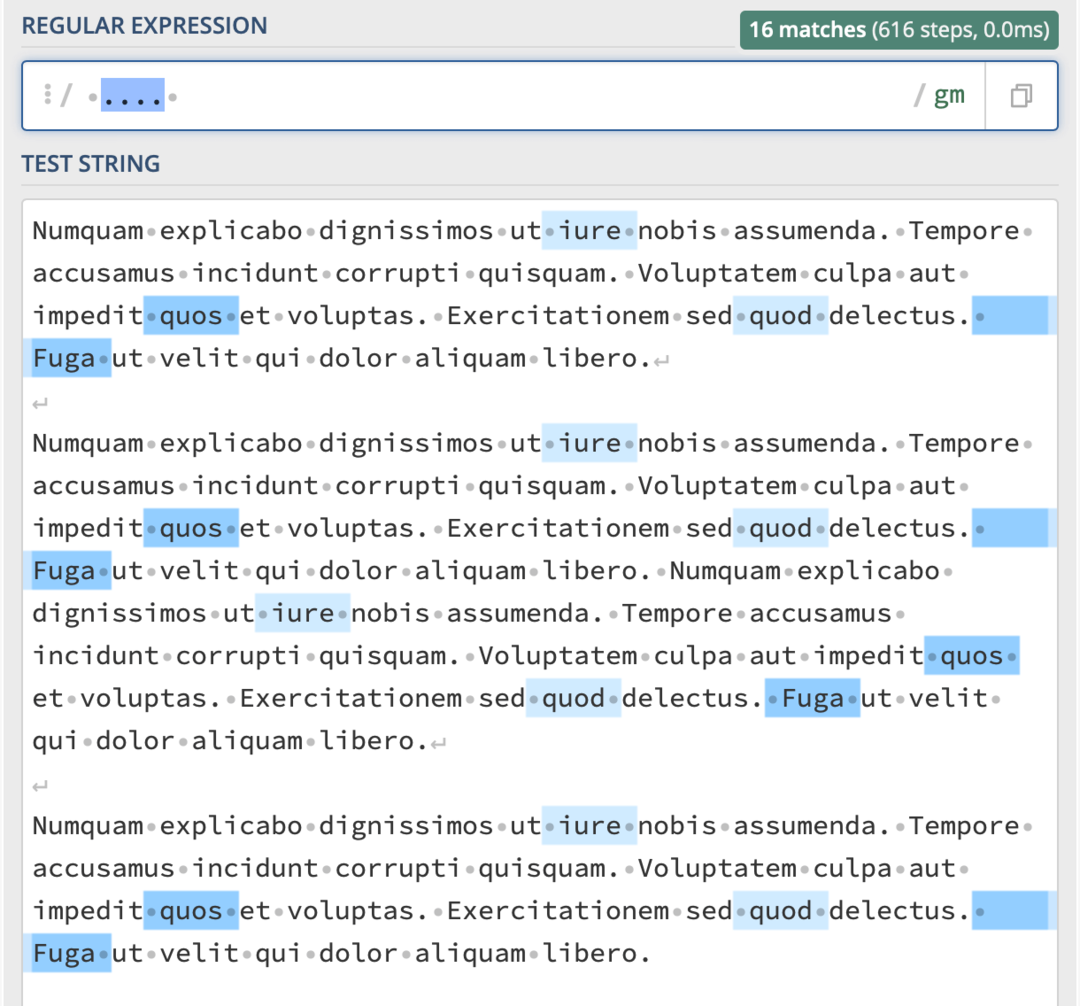
Například, pokud chci najít každý čtyřznakový řetězec v těle textu, mohl bych použít ... s mezerou na obou stranách.
A zde jsou všechny řetězce o sedmi znacích ve stejném těle textu:
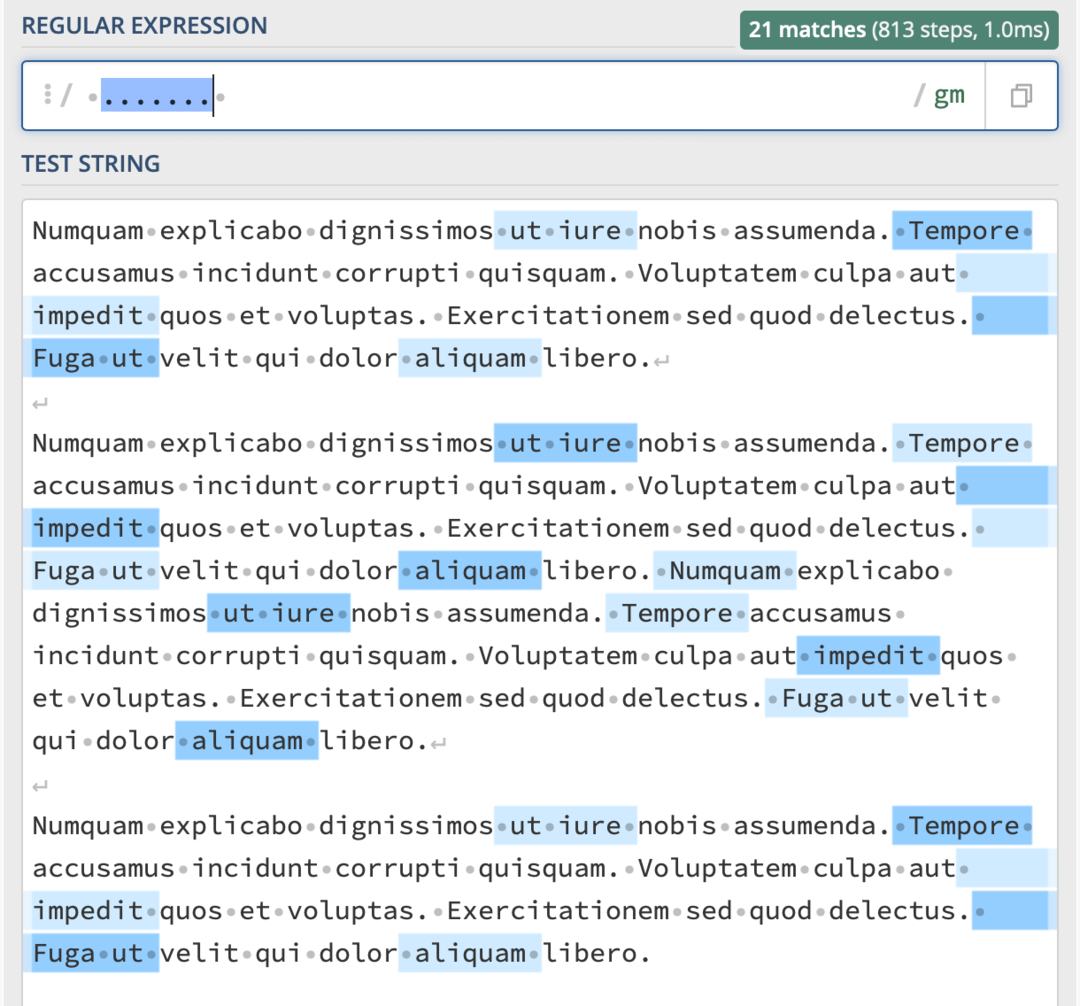
Všimněte si, že to není dokonalá metoda pro nalezení řetězců určité délky. Jak můžete vidět ve výše uvedených příkladech, některé řetězce se shodují, což by nemělo být, a některé, které by měly být, byly ignorovány. Je jen zajímavé si uvědomit, že můžete použít . znak k počítání znaků.
Také mějte na paměti, že . je speciální znak v regulárním výrazu. To znamená, že budete muset přidat a \ před ním, pokud chcete hledat období. To znamená, že budete muset použít V pořádku\. aby odpovídala „Dobře“.
Pomocí kvantifikátorů zadejte délku textu, který hledáte
Dobře, takže můžete technicky použít . znak k vyhledání řetězce, který zabírá určitý počet znaků. Většinou však budete chtít být konkrétnější.
Zde přicházejí na řadu kvantifikátory. Kvantifikátory vám umožňují určit délku řetězce, který hledáte, když používáte regulární výraz se zkratkami.
Řekněme například, že chcete najít jakékoli slovo, které má konkrétně tři písmena. Chcete-li to určit, budete chtít použít tyto závorky:
{}
Když umístíte tyto závorky za tyto [] závorky, určujete, že chcete řetězec, který odpovídá počtu znaků uvnitř tohoto {} a rozsah znaků v tomto specifikovaných [].
Jsem si jistý, že to teď nedává moc smysl, takže se podívejme na příklad!
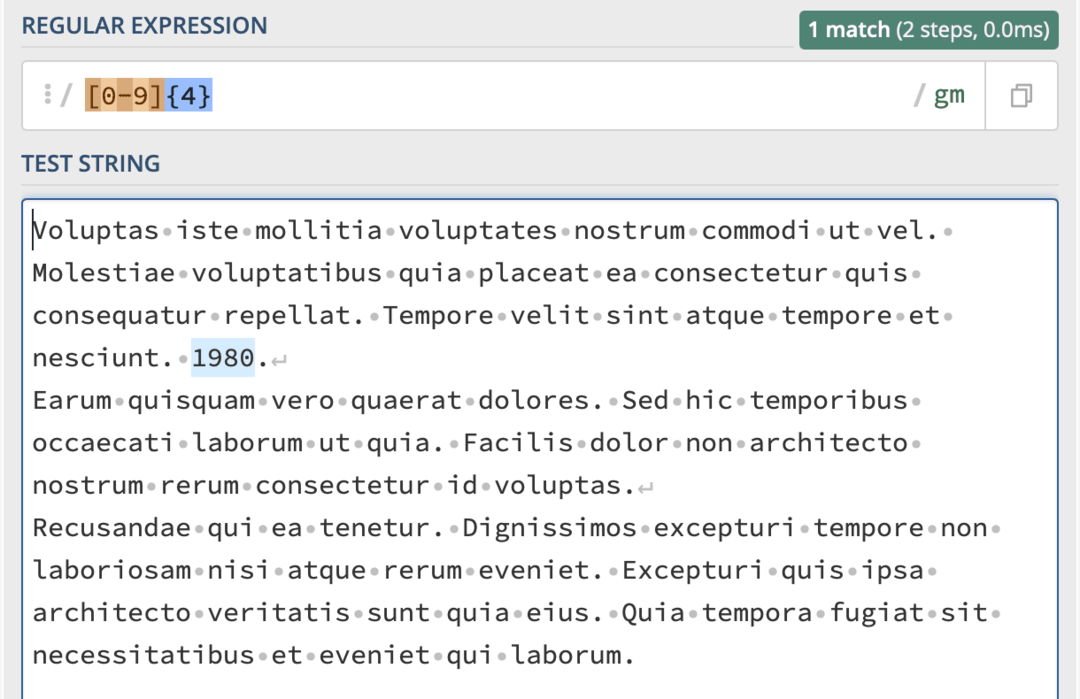
Řekněme, že chcete najít roky uvedené v textu. Protože rok se skládá ze čtyř čísel (samozřejmě ne každý rok od všech dob, jen mě sledujte zde), můžete tento kód použít k porovnání let v tomto textu:
[0-9]{4}
Tento kód říká, že chceme řetězec složený ze znaků od 0 do 9, který je konkrétně dlouhý čtyři znaky. Jak najde tento konkrétní řetězec, můžete vidět na následujícím snímku obrazovky:
Měl bych poznamenat, že s tímto kódem regulárního výrazu jsou nějaké problémy, a to, že nezohledňuje mezery ani interpunkci. Pokud tedy kód najde číslo delší než čtyři znaky, například „12345678“, najde řetězec „1234“ a řetězec „5678“.
Chcete-li tento problém vyřešit, budete chtít přidat mezeru na začátek kódu a závorku za {4} který obsahuje další mezeru, tečku, otazník, čárku a vykřičník. Tímto způsobem přehlédne dlouhé řetězce čísel, aniž by chyběly řetězce čísel, které mají na konci místo mezery interpunkci.
Můžete také chtít použít kvantifikátory k určení více než jedné délky řetězce. Například chci najít řetězec dlouhý čtyři znaky, ale také sedm a jedenáct. Takto by to vypadalo:
[a-z]{4,7,11}
Existuje několik dalších kvantifikátorů, o kterých budete chtít vědět
Dobře, takže stále existuje více kvantifikátorů! Těchto několik posledních kvantifikátorů je pro, když chcete určit délku řetězce, aniž byste byli příliš konkrétní.
Řekněme například, že chcete najít řetězec libovolné délky, kterému může odpovídat regulární výraz. Jako jméno! Jména (v západních zemích) začínají jedním velkým písmenem a končí náhodným počtem malých písmen, za nimiž následuje mezera. Chcete-li najít jméno, napište následující kód:
[A-Z][a-z]*
[A-Z] určuje, že prvním znakem řetězce by mělo být velké písmeno. [a-z]* určuje, že zbytek řetězce by měl být tvořen malými písmeny, ale nezáleží na tom, kolik písmen následuje. A mezera na konci znamená, že zápas ukončí, jakmile najde mezeru na konci malých písmen.
Zlaté kombo v regulárním výrazu je .*. To znamená, že se nekonečně shoduje s jakoukoli postavou. Jinými slovy, bude odpovídat celému tělu textu jako jedné položce.
Další kvantifikátor, který budete potřebovat znát, je +. Tenhle je stejně jako * kromě toho, že nebude odpovídat řetězci s nula znaky. * bude odpovídat libovolné délce řetězce, včetně řetězců, které nemají žádnou délku. +, na druhé straně potřebuje řetězec s alespoň jedním znakem nebo více.
Nakonec je tu ? kvantifikátor. Tohle je zvláštní. Určuje, že řetězec má buď nula znaků, nebo jeden znak. To je ono – buď nic, nebo jen jeden. Pokud tedy použijete kód [a-z]? s mezerou na začátku a na konci bude hledat jednotlivá písmena v těle textu.
Hledejte znaky na začátku a na konci řetězce textu
Blížíme se ke konci našeho průvodce používáním regulárního výrazu se zkratkami! Se zkratkami budete používat pouze dva další druhy regulárního kódu.
První jsou znaky, které vám umožňují přiřadit řetězce podle toho, jak začínají a/nebo končí.
Pokud není v závorkách, ^ role postavy se mění z významu „vyloučit“ na „začíná“. Určuje, že řetězec by měl začínat čímkoli chcete. Například když píšete ^A, které by odpovídalo písmenu „A“ v řetězcích „V pořádku“, „Apple“ a „A“.
Neodpovídá to však celému slovu. K tomu byste jej museli změnit na ^A[A-Za-z]*. To bude odpovídat prvnímu slovu odstavce/řetězce, pokud toto slovo začíná velkým „A“.
Jako vedlejší poznámku můžete napsat [A-Za-z] tak jako [A-z]. Znamená to totéž, jen jsem zjistil, že to první je o něco jasnější, když se učíte.
Chcete-li určit konec řetězce, budete chtít použít $ charakter. Funguje to stejně jako ^ charakter. Jediný rozdíl je, že to píšete na konec závorky/řetězce, nikoli na začátek.
Pokud byste například chtěli najít řetězce/odstavce končící na „le“, použili byste kód [A-z]*le$. To bude odpovídat výrazům „Tabulka“, „jablko“ a „schopný“, pokud jsou na konci řetězce nebo odstavce.
Regex dokonce odmítne tuto shodu, pokud je na konci řetězce mezera nebo interpunkční znaménko. "Stůl." nebude odpovídat tomuto kódu.
Chcete-li to vyřešit, můžete zohlednit interpunkci. Tento kód zohledňuje různé formy interpunkce a mezer, které se mohou vyskytnout na konci řetězce, včetně interpunkčního znaménka následovaného mezerou:
[A-z]*(le[\.\?!, ]?[ ]?)$
Tento kód bude odpovídat „Able“, „table.“, „Stable“ a „capable? “.
Ukládejte textové řetězce pomocí funkce seskupování regulárního výrazu se zkratkami
V pořádku! Dostali jste se na konec našeho průvodce AppleToolBox o používání regulárního výrazu se zkratkami. Zbývá se naučit ještě jednu funkci regulárního výrazu, a to seskupování.
Seskupování je pravděpodobně nejdůležitější funkcí regulárního výrazu, protože vám umožňuje dělat věci s kódem regulárního výrazu, který napíšete. Bez něj je regulární výraz pouze funkcí vyhledávání. Může vám sdělit pouze to, zda řetězec existuje ve větší části textu, tj. vrátí hodnotu „true“ nebo „false“.
Se seskupováním však můžete uložit výsledky svého regulárního kódu. A to znamená, že můžete kopírovat shody, ukládat je do proměnných, nahrazovat je jiným textem, upravovat jejich formátování a vše ostatní, co byste chtěli dělat s regulárním výrazem.
Naštěstí je seskupování super snadné! Cokoli chcete seskupit, vložte do závorek (). Cokoli vložíte do závorek, bude považováno za skupinu.
Pokud vložíte celý řádek regulárního kódu do závorek, např (.*@.*\..{3}), pak si tato skupina zapamatuje váš kód, což umožní její pozdější vyvolání.
Je důležité, abyste skupiny používali pouze tehdy, když to potřebujete. Protože jsou uloženy v paměti, mohou způsobit snížení výkonu vašeho kódu. Uložte si skupiny, až budou potřeba!
Skupiny můžete použít i pro organizaci
Skupiny můžete také použít k uspořádání kódu regulárního výrazu pomocí zkratek. Když to uděláte, skupina v závorkách nebude nutně zapamatována.
Řekněme například, že chci najít shodu se slovem „Ahoj“, kromě toho, že je mi jedno, jaké je poslední písmeno. Může to být jakékoli malé nebo velké písmeno nebo dokonce číslo. „Hell3838djdjajaksks“ a „Ahoj“ by se měly počítat jako shody. Na druhou stranu „peklo“ by se nemělo počítat.
Aby to fungovalo, napíšu kód Peklo[A-z]|[0-9]+. Ale toto je výsledek, který dostávám:
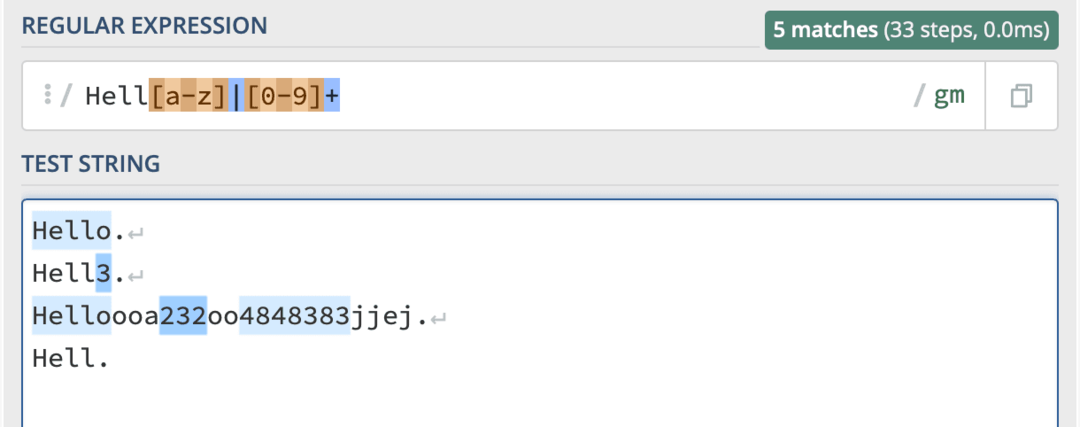
Důvod, proč neodpovídá tomu, co jsem očekával, je ten + se aplikuje pouze na [0-9] Závorka. Potřebuji, aby to platilo pro obě závorky.
Navíc tento kód říká, že chci buď peklo[A-z]nebo[0-9]. Takže hledá slova, která začínají na „Peklo“ a končí písmenem, nebo hledá libovolné řetězce čísel. Ve skutečnosti potřebuji, aby se shodovalo s výskyty slova „Hell“, které končí písmenem nebo číslem.
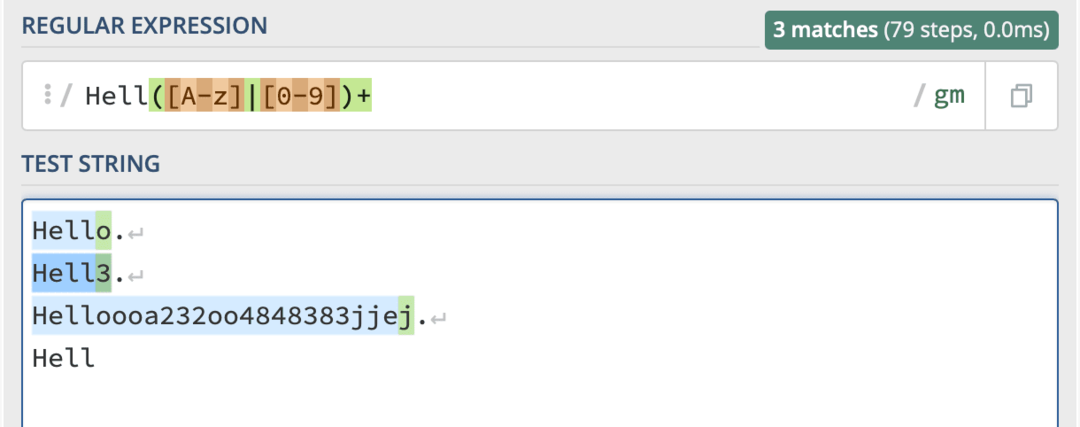
Abych to napravil, mohu použít skupinu a přepsat kód jako Peklo([A-z]|[0-9])+. Nyní hledá slovo „Hell“ následované libovolným písmenem nebo číslem. A protože + se vztahuje na obě závorky, může to být libovolná kombinace písmen a číslic, pokud je přítomno alespoň jedno písmeno nebo číslo.
Jak můžete vidět na níže uvedeném snímku obrazovky, tato skupina řeší můj problém, aniž by nutně ukládala informace do této skupiny:
Co teď?
A to je vše! To je téměř vše, co byste kdy chtěli vědět o používání regulárního výrazu se zkratkami. Doufejme, že se cítíte dostatečně sebevědomí, abyste mohli začít experimentovat s regulárním výrazem hned teď, i když vám to zpočátku nedávalo smysl.
Nyní, když znáte základy regulárního výrazu, jste připraveni jej začít používat ve svých zkratkách! Klávesové zkratky přijímají regulární výraz v následujících akcích:
- Shoda textu
- Nahradit text
Pomocí těchto dvou akcí zkratek můžete do svých zkratek vložit regulární výraz.
Spárujte to s automatizačními schopnostmi zkratek a máte k dispozici docela výkonný nástroj.
Regulární výraz můžete použít k usnadnění formátování textu v Zástupcích, k získávání informací z e-mailů, textů, webových stránek, soubory a události kalendáře, vytvořte text ve stanoveném formátu, zkontrolujte, zda byl vstup zadán správně, a více.
Řekněme například, že chcete najít shodu pro e-maily. Možná potřebujete zkontrolovat, že řetězec textu je e-mail, nebo možná chcete vytáhnout e-mail (y) z těla textu.
Jak bys to rozebral?
Víte, že základní strukturou e-mailu bude nějaká kombinace písmen, čísel a znaků, po nichž bude následovat symbol „@“, pak následovaný názvem webové stránky, jako je Gmail nebo iCloud, po kterém následuje „.com“, „.org“ nebo jiný druh tříznakové nejvyšší úrovně doména.
Chcete-li to napsat do regulárního výrazu, musíte zadat, že chcete řetězec o délce alespoň jednoho znaku, který bude bezprostředně následovat symbolem „@“, poté dalším řetězcem obsahujícím alespoň jeden znak, za ním následuje znak „.“ a poté řetězec tří znaky. To by vypadalo takto:
[e-mail chráněný]+\..{3}
Pokud toto vložíte do Shoda textu nebo Nahradit text akcí v Zkratkách, budete mít automatizaci, která dokáže najít, uložit a manipulovat s e-mailovou adresou.
Tento druh řešení problémů můžete použít k vymýšlení vlastních řešení regulárních výrazů nebo k nalezení řešení, která ostatní vytvořili online!
Začněte používat regulární výraz se zkratkami a posuňte svou automatizaci na další úroveň
A tak to, přátelé, opravdu je. Doufám, že se vám líbilo sledování tohoto článku! Toto je jeden z nejambicióznějších dílů, které jsem kdy napsal pro AppleToolBox. Musel jsem se naučit regulární výraz, abych to napsal, a doufám, že jsem vám při tom mohl pomoci se to naučit.
Používání regulárního výrazu se zkratkami se neliší od učení se, jak na svém smartphonu nebo počítači dělat cokoli jiného. Stačí věnovat trochu času a trpělivosti a nakonec se tam dostanete.
Další návody, návody a novinky o všech věcech Apple najdete ve zbytku blog AppleToolBox.
V pořádku [A-Z][a-z]+, uvidíme se příště!