I næsten ethvert computerprogram er der dele af koden, der forgrener sig i separate stier. For eksempel har en hvis-så-else-udsagn to mulige udfald. Disse udsagn giver ikke noget problem for sekventielle processorer, da CPU'en behandler hver kommando i rækkefølge. Filialer udgør et stort problem for pipelinede processorer, da flere instruktioner udføres på én gang.
Scenariet
I tilfælde af et program med en forgreningserklæring med to mulige udfald, kan de to mulige kodestier ikke være på samme sted. Den behandling, der kræves for at fuldføre begge muligheder, vil være anderledes. Ellers ville programmet ikke forgrene sig. Der vil sandsynligvis være et rimeligt antal forgreningsudsagn, der kun tages én gang, som en if-sætning.
Der er også forgreningsudsagn, der danner en løkke. Selvom disse måske ikke er så numerisk almindelige som engangsudsagn, gentages de generelt statistisk. Det kan antages, at det er mere sandsynligt, at en gren vil tage dig tilbage rundt i en løkke end ikke.
Hvorfor er dette et problem?
Det er ligegyldigt, hvordan dette problem er formuleret i en fuldt sekventiel processor. Det er simpelthen ikke et problem. Hvilken gren der tages vides før første del af den følgende instruktion behandles.
I en pipelinet processor er de følgende instruktioner imidlertid i kø. De er allerede ved at blive behandlet, når processoren ved, hvilken filial der tages. Så hvordan skal processoren håndtere dette scenarie? Der er et par muligheder. Det værste er simpelthen at vente og lade rørledningen stå stille, mens den venter på svaret på, hvilken gren den skal tage. Dette ville betyde, at hver gang du har en forgreningserklæring, vil du altid miste mindst lige så mange cyklusser af processortid, som du har stadier i pipelinen.
Alternativt kan du prøve at køre begge muligheder i pipelinen og kassere det forkerte valg. Dette ville have halvdelen af straffen for ikke at gøre noget, men stadig pådrage sig en præstationsstraf for hver forgrening. I betragtning af at moderne CPU'er også kan køre instruktioner ude af drift, kan du potentielt forsøge at køre hver forgreningsinstruktion så hurtigt som muligt. Så resultatet er kendt, før det er nødvendigt. Denne mulighed kan være nyttig, bortset fra at den ikke er skalerbar. Antag, at du har en relativt høj tæthed af forgreningsudsagn. I så fald vil du simpelthen ikke være i stand til at køre dem alle tidligt uden at have lidt ledig tid.
Hvordan er dette problem virkelig løst
I virkeligheden indbefatter processoren en grenprædiktor. Grenprædiktoren forsøger at gætte, hvilket resultat af et forgreningsvalg der vil blive taget. Processoren antager derefter, at forudsigelsen er korrekt, og planlægger instruktioner. Hvis grenprædiktoren er nøjagtig, er der ingen præstationsstraf.
Hvis forgreningsprædiktoren laver en fejl, skal du skylle rørledningen og begynde at behandle det faktiske resultat. Dette resulterer i en lidt værre præstationsstraf end at have gjort ingenting og bare ventet på resultatet. For at få den bedste ydeevne er det vigtigt at sikre, at grenprædiktoren er så nøjagtig som muligt. Der er en række forskellige tilgange til dette.
Matchende kode
I maskinkode er en gren altid et valg mellem at læse den næste instruktion eller hoppe til et sæt instruktioner et andet sted. Nogle tidlige implementeringer af grenprædiktorer antog simpelthen, at alle grene altid eller aldrig ville blive taget. Denne implementering kan have en overraskende god succesrate, hvis compilere kender denne adfærd og er det designet til at justere maskinkoden, så det mest sandsynlige resultat stemmer overens med processorens generelle antagelse. Dette kræver en masse tuning og justering af softwareudviklingsvaner.
Et andet alternativ var at lære af statistikken, at sløjfer generelt tages og altid hoppe, hvis grenen går baglæns i instruktionsstrøm og hop aldrig, hvis hoppet er fremad, fordi det normalt ville være den statistisk mindre sandsynlige tilstand for at forlade en sløjfe. Disse er begge typer statisk grenforudsigelse, hvor resultatet af en gren forudsiges på kompileringstidspunktet.
Dynamiske grenprædiktorer
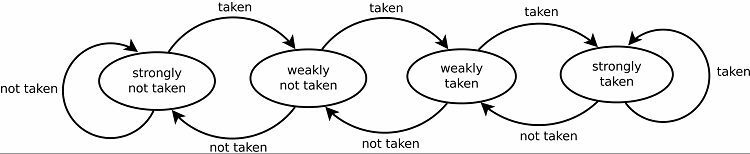
Moderne brancheforudsigere er dynamiske og bruger statistikker fra det aktuelle program for at opnå bedre forudsigelsessuccesrater. En mættende tæller er grundlaget for alle nuværende grenprædiktorer. Det første gæt afgøres statisk eller tilfældigt. Når en gren er blevet taget eller ikke er taget, gemmes dette resultat i en del af hukommelsen. Næste gang den samme gren kommer rundt, forudsiger grenprædiktoren det samme resultat som før.
Dette resulterer naturligvis i gode forudsigelseshastigheder for loops. Der er to versioner af dette. De tidlige versioner brugte simpelthen en enkelt bit data til at indikere, om grenen blev taget eller ej. Senere versioner bruger to bits til at angive et svagt eller stærkt taget eller ikke taget valg. Denne opsætning kan stadig forudsige resultatet af at tage en løkke, hvis programmet vender tilbage til det, hvilket generelt øger succesraterne.
Sporingsmønstre
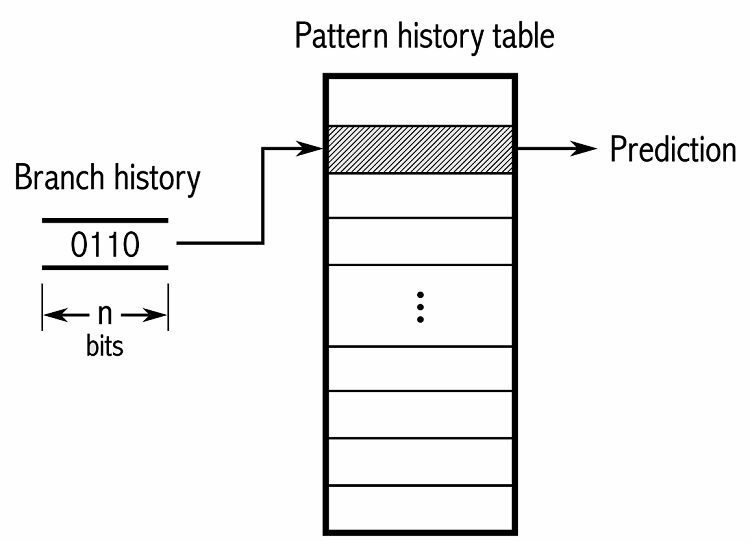
For at spore mønstre holder nogle grenprædiktorer styr på en historik over, hvilke valg der blev taget. Antag for eksempel, at en løkke konstant kaldes, men kun går rundt fire gange, før den bryder ud af løkken. I så fald kan en adaptiv prædiktor på to niveauer identificere dette mønster og forudsige, at det sker igen. Dette øger succesraterne endnu mere over en simpel mættet tæller. Moderne grenprædiktorer bygger videre på dette ved at bruge et neuralt netværk til at spotte og forudsige mønstre.
Nogle grenprædiktorer bruger flere algoritmer og sammenligner derefter resultaterne for at afgøre, hvilken forudsigelse der skal bruges. Nogle systemer holder styr på hver forgreningsinstruktion separat i det, der kaldes lokal afdelingsforudsigelse. Andre bruger et globalt brancheforudsigelsessystem til at spore alle seneste forgreningsinstruktioner. Begge har deres anvendelser og ulemper.
Konklusion
En grenprædiktor er en speciel del af en pipelinet CPU. Den forsøger at forudsige resultatet af en forgreningsinstruktion, før den faktiske instruktion behandles. Dette er en kernefunktion af en pipelinet CPU, da den tillader CPU'en at holde pipelinen mættet, selvom den er usikker på, hvilke instruktioner der skal udføres. De giver ingen reduktion i ydeevnen, når de er korrekte. Moderne algoritmer kan være nøjagtige i relativt forudsigelige arbejdsbelastninger så meget som 97 % af tiden.
Der er ingen perfekt metode til forudsigelse, så implementeringerne varierer. Effekten af at lave en forkert forudsigelse afhænger af længden af rørledningen. Specifikt kan længden af rørledningen før det bestemmes, om forudsigelsen var forkert. Det afhænger også af, hvor mange instruktioner der er i hvert pipelinestadie. Moderne avancerede desktop-CPU'er har omkring 19 pipeline-trin og kan køre mindst fire instruktioner samtidigt i hvert trin.