In fast jedem Computerprogramm gibt es Teile des Codes, die sich in separate Pfade verzweigen. Beispielsweise hat eine if-then-else-Anweisung zwei mögliche Ergebnisse. Diese Anweisungen stellen für sequentielle Prozessoren kein Problem dar, da die CPU jeden Befehl der Reihe nach verarbeitet. Verzweigungen stellen ein großes Problem für Pipeline-Prozessoren dar, da mehrere Befehle gleichzeitig ausgeführt werden.
Das Szenario
Im Fall eines Programms mit einer Verzweigungsanweisung mit zwei möglichen Ergebnissen können die beiden möglichen Codepfade nicht an derselben Stelle sein. Die Verarbeitung, die zum Abschließen einer der beiden Optionen erforderlich ist, ist unterschiedlich. Andernfalls würde das Programm nicht verzweigen. Es wird wahrscheinlich eine ganze Reihe von Verzweigungsanweisungen geben, die nur einmal verwendet werden, wie z. B. eine if-Anweisung.
Es gibt auch Verzweigungsanweisungen, die eine Schleife bilden. Auch wenn diese zahlenmäßig nicht so häufig sind wie Einwegangaben, werden sie im Allgemeinen statistisch wiederholt. Es ist davon auszugehen, dass es wahrscheinlicher ist, dass eine Abzweigung Sie um eine Schleife zurückführt, als nicht.
Warum ist das ein Problem?
Es spielt keine Rolle, wie dieses Problem in einem vollständig sequentiellen Prozessor formuliert wird. Es ist einfach kein Problem. Welche Verzweigung genommen wird, ist bekannt, bevor der erste Teil der folgenden Anweisung verarbeitet wird.
In einem Pipeline-Prozessor werden jedoch die folgenden Befehle in eine Warteschlange gestellt. Sie werden bereits verarbeitet, wenn der Prozessor weiß, welcher Zweig genommen wird. Wie also soll der Prozessor mit diesem Szenario umgehen? Es gibt einige Optionen. Das Schlimmste ist einfach zu warten und die Pipeline im Leerlauf zu lassen, während sie auf die Antwort wartet, welche Verzweigung genommen werden soll. Dies würde bedeuten, dass Sie jedes Mal, wenn Sie eine Verzweigungsanweisung haben, immer mindestens so viele Zyklen an Prozessorzeit verlieren würden, wie Sie Stufen in der Pipeline haben.
Alternativ könnten Sie versuchen, beide Optionen in der Pipeline auszuführen und die falsche Auswahl zu verwerfen. Dies hätte die Hälfte der Strafe, nichts zu tun, würde aber dennoch eine Leistungseinbuße bei jeder Verzweigungsanweisung nach sich ziehen. Da moderne CPUs auch Anweisungen außer der Reihe ausführen können, könnten Sie möglicherweise versuchen, jede Verzweigungsanweisung so schnell wie möglich auszuführen. Das Ergebnis ist also bekannt, bevor es benötigt wird. Diese Option könnte hilfreich sein, außer dass sie nicht skalierbar ist. Angenommen, Sie haben eine relativ hohe Dichte an Verzweigungsanweisungen. In diesem Fall können Sie einfach nicht alle vorzeitig ausführen, ohne etwas Leerlaufzeit zu haben.
Wie wird dieses Problem wirklich angegangen?
In Wirklichkeit enthält der Prozessor einen Verzweigungsprädiktor. Der Verzweigungsvorhersageversuch versucht zu erraten, welches Ergebnis einer Verzweigungsauswahl genommen wird. Der Prozessor nimmt dann an, dass die Vorhersage korrekt ist, und plant Anweisungen. Wenn die Verzweigungsvorhersage genau ist, gibt es keine Leistungseinbuße.
Wenn der Verzweigungsprädiktor einen Fehler macht, müssen Sie die Pipeline leeren und mit der Verarbeitung des tatsächlichen Ergebnisses beginnen. Dies führt zu einer etwas schlimmeren Leistungseinbuße, als nichts getan und nur auf das Ergebnis gewartet zu haben. Um die beste Leistung zu erzielen, ist es wichtig sicherzustellen, dass die Verzweigungsvorhersage so genau wie möglich ist. Dazu gibt es verschiedene Ansätze.
Passender Code
Im Maschinencode ist eine Verzweigung immer eine Wahl zwischen dem Lesen der nächsten Anweisung oder dem Springen zu einer Reihe von Anweisungen an anderer Stelle. Einige frühe Implementierungen von Verzweigungsprädiktoren gingen einfach davon aus, dass alle Verzweigungen immer oder nie genommen würden. Diese Implementierung kann eine überraschend gute Erfolgsrate haben, wenn Compiler dieses Verhalten kennen und sind entwickelt, um den Maschinencode so anzupassen, dass das wahrscheinlichste Ergebnis mit dem allgemeinen des Prozessors übereinstimmt Annahme. Dies erfordert eine Menge Tuning und Anpassung der Softwareentwicklungsgewohnheiten.
Eine andere Alternative war, aus der Statistik zu lernen, dass Schleifen generell genommen werden und immer dann springen, wenn der Ast rückwärts in die geht Befehlsstrom und springen Sie niemals, wenn der Sprung vorwärts erfolgt, da dies normalerweise der statistisch unwahrscheinlichere Zustand des Verlassens von a wäre Schleife. Dies sind beide Arten der statischen Verzweigungsvorhersage, bei der das Ergebnis einer Verzweigung zur Kompilierzeit vorhergesagt wird.
Dynamische Verzweigungsprädiktoren
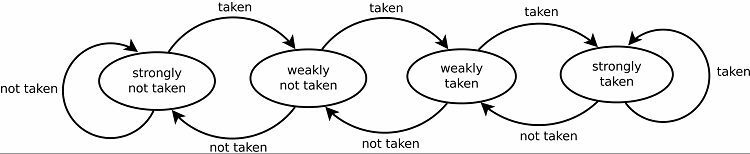
Moderne Verzweigungsprädiktoren sind dynamisch und verwenden Statistiken aus dem aktuell laufenden Programm, um bessere Vorhersageerfolgsraten zu erzielen. Ein Sättigungszähler ist eine Basis für alle aktuellen Verzweigungsprädiktoren. Die erste Vermutung wird statisch oder zufällig entschieden. Sobald eine Verzweigung genommen oder nicht genommen wurde, wird dieses Ergebnis in einem Teil des Speichers gespeichert. Das nächste Mal, wenn dieselbe Verzweigung auftritt, sagt der Verzweigungsvorhersager dasselbe Ergebnis wie zuvor voraus.
Dies führt natürlich zu guten Vorhersageraten für Schleifen. Davon gibt es zwei Versionen. Die frühen Versionen verwendeten einfach ein einzelnes Datenbit, um anzuzeigen, ob die Verzweigung genommen wurde oder nicht. Spätere Versionen verwenden zwei Bits, um eine schwach oder stark getroffene oder nicht getroffene Wahl anzuzeigen. Dieses Setup kann immer noch das Ergebnis einer Schleife vorhersagen, wenn das Programm zu ihr zurückkehrt, was im Allgemeinen die Erfolgsraten erhöht.
Verfolgungsmuster
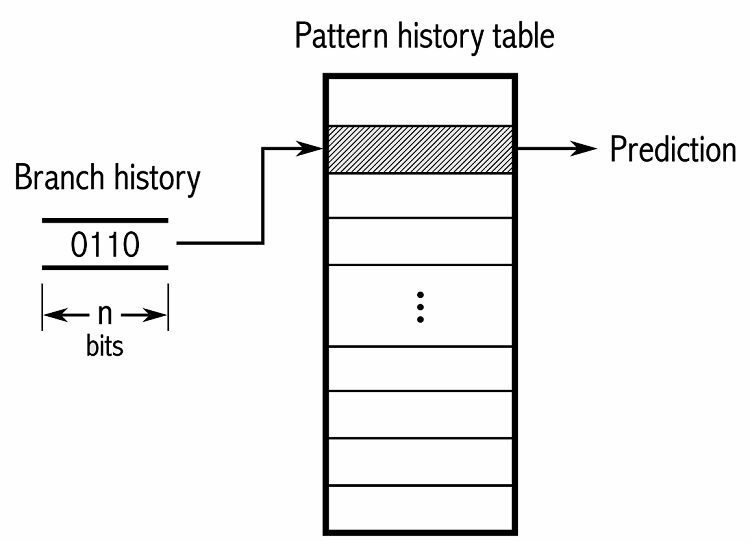
Um Muster zu verfolgen, verfolgen einige Verzweigungsprädiktoren einen Verlauf der getroffenen Entscheidungen. Angenommen, eine Schleife wird kontinuierlich aufgerufen, aber nur viermal wiederholt, bevor sie aus der Schleife ausbricht. In diesem Fall kann ein zweistufiger adaptiver Prädiktor dieses Muster identifizieren und vorhersagen, dass es erneut auftritt. Dies erhöht die Erfolgsrate gegenüber einem einfachen gesättigten Zähler noch weiter. Moderne Verzweigungsprädiktoren bauen darauf weiter auf, indem sie ein neuronales Netzwerk verwenden, um Muster zu erkennen und vorherzusagen.
Einige Verzweigungsprädiktoren verwenden mehrere Algorithmen und vergleichen dann die Ergebnisse, um zu entscheiden, welche Vorhersage verwendet werden soll. Einige Systeme verfolgen jeden Verzweigungsbefehl separat in der sogenannten lokalen Verzweigungsvorhersage. Andere verwenden ein globales Verzweigungsvorhersagesystem, um alle kürzlichen Verzweigungsanweisungen zu verfolgen. Beide haben ihre Vor- und Nachteile.
Fazit
Ein Verzweigungsprädiktor ist ein spezieller Teil einer Pipeline-CPU. Es versucht, das Ergebnis einer Verzweigungsanweisung vorherzusagen, bevor die eigentliche Anweisung verarbeitet wird. Dies ist eine Kernfunktion einer Pipeline-CPU, da sie es der CPU ermöglicht, die Pipeline gesättigt zu halten, selbst wenn sie nicht sicher ist, welche Anweisungen ausgeführt werden müssen. Sie bieten keine Leistungsminderung, wenn sie korrekt sind. Moderne Algorithmen können bei relativ vorhersehbaren Workloads bis zu 97 % der Zeit genau sein.
Es gibt keine perfekte Vorhersagemethode, daher variieren die Implementierungen. Die Leistungsauswirkung einer falschen Vorhersage hängt von der Länge der Pipeline ab. Insbesondere kann die Länge der Pipeline vorher bestimmt werden, wenn die Vorhersage falsch war. Es hängt auch davon ab, wie viele Anweisungen sich in jeder Pipeline-Stufe befinden. Moderne High-End-Desktop-CPUs haben etwa 19 Pipeline-Stufen und können in jeder Stufe mindestens vier Befehle gleichzeitig ausführen.