Frühe Computer waren vollständig sequentiell. Jede Anweisung, die der Prozessor erhielt, musste der Reihe nach vollständig ausgeführt werden, bevor die nächste gestartet werden konnte. Die meisten Befehle bestehen aus fünf Stufen: Befehlsabruf, Befehlsdecodierung, Ausführung, Speicherzugriff und Rückschreiben. Jeweils diese Stufen erhalten die Anweisung, die abgeschlossen werden muss, trennen Sie die Operation von den Werten bearbeitet, führe die Operation aus, öffne das Register, in das das Ergebnis geschrieben werden soll, und schreibe das Ergebnis in das geöffnete Register registrieren.
Jede dieser Phasen sollte einen Zyklus in Anspruch nehmen. Wenn sich die Daten nicht in einem Register befinden, müssen sie leider aus dem CPU-Cache oder dem System-RAM angefordert werden. Dies ist viel langsamer und fügt Dutzende oder Hunderte von Taktzyklen Latenz hinzu. In der Zwischenzeit muss alles andere warten, da keine anderen Daten oder Anweisungen verarbeitet werden können. Diese Art von Prozessordesign wird als subskalar bezeichnet, da es weniger als einen Befehl pro Taktzyklus ausführt.

Pipelining zu Skalar
Ein Skalarprozessor kann durch Anwenden einer Systempipeline erreicht werden. Jede der fünf Stufen einer ausgeführten Anweisung läuft in unterschiedlichen Hardware-Bits im eigentlichen Prozessorkern. Wenn Sie also vorsichtig mit den Daten umgehen, die Sie für jede Stufe in die Hardware einspeisen, können Sie jeden von ihnen in jedem Zyklus beschäftigen. In einer perfekten Welt könnte dies zu einer 5-fachen Beschleunigung führen und dazu, dass der Prozessor perfekt skalar ist und eine vollständige Anweisung pro Zyklus ausführt.

In der Realität sind Programme komplex und reduzieren den Durchsatz. Wenn Sie beispielsweise zwei Additionsanweisungen „a = b + c“ und „d = e + f“ haben, können diese problemlos in einer Pipeline ausgeführt werden. Wenn Sie jedoch „a = b + c“ gefolgt von „d = a + e“ haben, haben Sie ein Problem. Unter der Annahme, dass diese beiden Anweisungen direkt aufeinander folgen, ist der Prozess zur Berechnung des neuen Werts von „a“ noch nicht abgeschlossen. geschweige denn in den Speicher zurückgeschrieben werden, bevor der zweite Befehl den alten Wert von „a“ liest und dann die falsche Antwort für gibt "d".
Diesem Verhalten kann durch die Einbindung eines Dispatchers entgegengewirkt werden, der anstehende Instruktionen analysiert und sicherstellt, dass keine von einer anderen abhängige Instruktion zu dicht hintereinander ausgeführt wird. Es führt das Programm tatsächlich in der falschen Reihenfolge aus, um dies zu beheben. Das funktioniert, weil viele Anweisungen nicht unbedingt auf das Ergebnis einer vorherigen angewiesen sind.
Erweiterung der Pipeline auf Superskalar
Ein superskalarer Prozessor kann mehr als einen vollständigen Befehl pro Zyklus ausführen. Eine Möglichkeit, dies zu tun, besteht darin, die Pipeline so zu erweitern, dass es zwei oder mehr Hardware-Bits gibt, die jede Stufe handhaben können. Auf diese Weise können sich in jedem Zyklus zwei Befehle in jeder Stufe der Pipeline befinden. Dies führt natürlich zu einer erhöhten Designkomplexität, da die Hardware dupliziert wird, bietet jedoch hervorragende Möglichkeiten zur Leistungsskalierung.
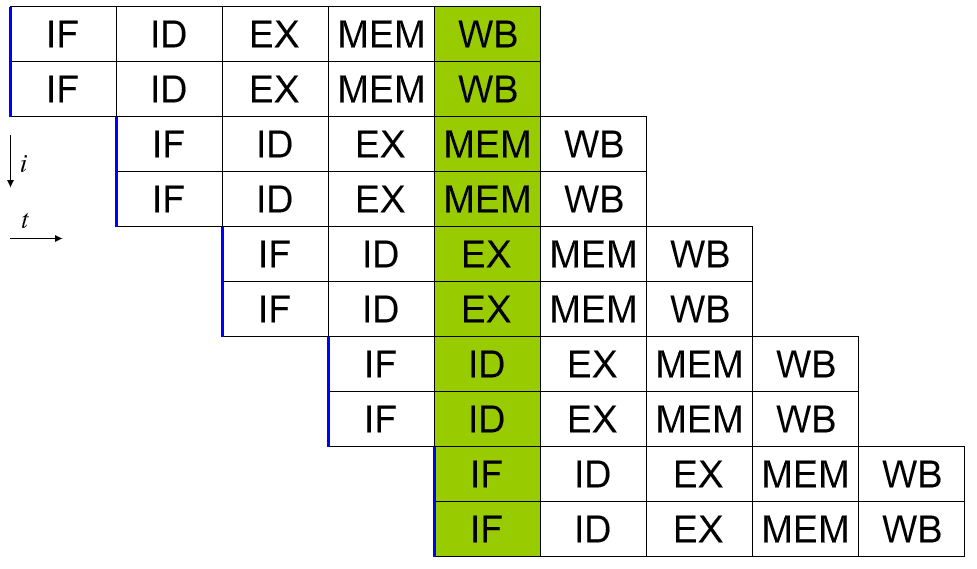
Die Leistungssteigerung durch zunehmende Pipelines skaliert jedoch nur so weit effizient. Thermische und Größenbeschränkungen setzen einige Grenzen. Es gibt auch erhebliche Planungskomplikationen. Ein effizienter Dispatcher ist jetzt noch kritischer, da er sicherstellen muss, dass sich keiner der beiden Sätze von Anweisungen auf das Ergebnis einer der anderen verarbeiteten Anweisungen verlässt.
Ein Verzweigungsprädiktor ist ein Teil des Dispatchers, der immer kritischer wird, je höher der Superskalar-Prozessor ist. Einige Anweisungen können zwei mögliche Ergebnisse haben, von denen jedes zu unterschiedlichen folgenden Anweisungen führt. Ein einfaches Beispiel wäre eine „if“-Anweisung. „Wenn dies wahr ist, tue das, sonst tue das andere“. Ein Verzweigungsvorhersageversuch versucht, das Ergebnis einer Verzweigungsoperation vorherzusagen. Es plant dann präventiv die Anweisungen und führt sie entsprechend dem seiner Meinung nach wahrscheinlichen Ergebnis aus.
Es gibt eine Menge komplexer Logik in modernen Verzweigungsprädiktoren, die zu Erfolgsraten der Verzweigungsvorhersage in der Größenordnung von 98 % führen kann. Eine korrekte Vorhersage erspart die Zeit, die mit dem Warten auf das tatsächliche Ergebnis verschwendet werden könnte, eine falsche Vorhersage erfordert die Vorhersage Anweisungen und alle ihre Ergebnisse werden verworfen und die wahren Anweisungen werden an ihrer Stelle ausgeführt, was mit einer leichten Strafe gegenüber dem Haben von gerecht einhergeht gewartet. So können hohe Vorhersageerfolgsraten die Leistung spürbar steigern.
Fazit
Ein Computerprozessor gilt als superskalar, wenn er mehr als einen Befehl pro Taktzyklus ausführen kann. Frühe Computer waren vollständig sequentiell und führten jeweils nur eine Anweisung aus. Dies bedeutete, dass jeder Befehl mehr als einen Zyklus benötigte, um vollständig ausgeführt zu werden, und diese Prozessoren waren daher subskalar. Eine grundlegende Pipeline, die die Nutzung der stufenspezifischen Hardware für jede Stufe eines Befehls ermöglicht, kann höchstens einen Befehl pro Taktzyklus ausführen, wodurch sie skalar wird.
Es ist zu beachten, dass kein einzelner Befehl in einem einzelnen Taktzyklus vollständig verarbeitet wird. Es dauert immer noch mindestens fünf Zyklen. Es können jedoch mehrere Befehle gleichzeitig in der Pipeline sein. Dies ermöglicht einen Durchsatz von einem oder mehreren abgeschlossenen Befehlen pro Zyklus.
Superskalar sollte nicht mit Hyperscaler verwechselt werden, was sich auf Unternehmen bezieht, die Hyperscale-Computing-Ressourcen anbieten können. Hyperscale Computing umfasst die Möglichkeit, Hardwareressourcen wie Rechenleistung, Arbeitsspeicher, Netzwerkbandbreite und Speicher nahtlos je nach Bedarf zu skalieren. Dies ist typischerweise in großen Rechenzentren und Cloud-Computing-Umgebungen zu finden.