Varhaiset tietokoneet olivat täysin peräkkäisiä. Jokainen prosessorin saama ohje oli suoritettava kokonaisuudessaan järjestyksessä ennen kuin seuraava voitiin käynnistää. Useimmissa ohjeissa on viisi vaihetta: käskyn nouto, käskyn purku, suoritus, muistin käyttö ja takaisinkirjoitus. Vastaavasti nämä vaiheet saavat suoritettavan käskyn, erottavat toiminnon arvojen olemisesta suorita operaatio, avaa rekisteri, johon tulos kirjoitetaan, ja kirjoita tulos avattavaan rekisteröidy.
Jokaisen näistä vaiheista tulisi kestää yksi sykli. Valitettavasti, jos tiedot eivät ole rekisterissä, se on pyydettävä CPU-välimuistista tai järjestelmän RAM-muistista. Tämä on paljon hitaampaa ja lisää kymmeniä tai satoja kellojaksoja latenssiin. Sillä välin kaiken muun on odotettava, koska muita tietoja tai ohjeita ei voida käsitellä. Tämän tyyppistä prosessorin rakennetta kutsutaan subskalaariksi, koska se suorittaa vähemmän kuin yhden käskyn kellojaksoa kohden.

Liukutus skalaariin
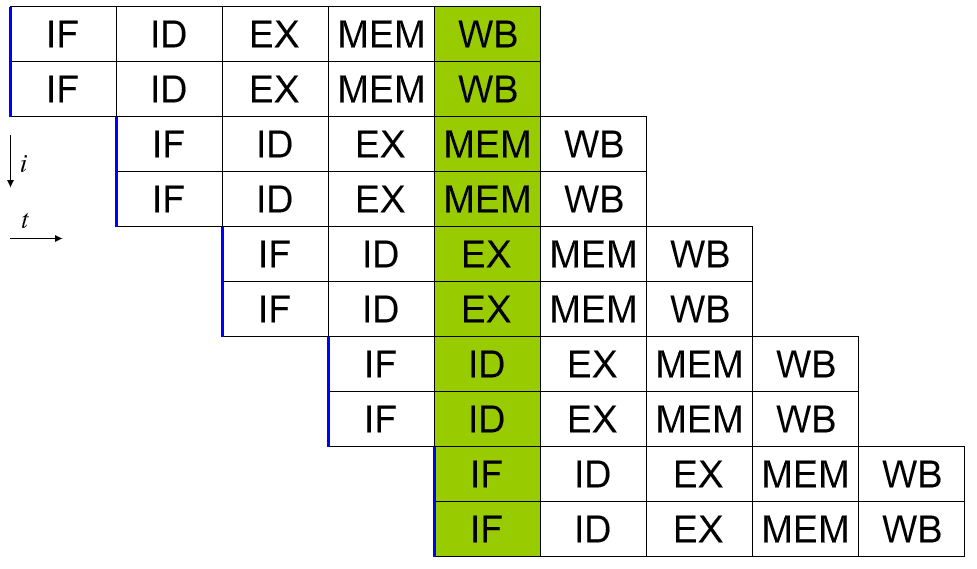
Skalaariprosessori voidaan saavuttaa käyttämällä järjestelmäliukuhihnaa. Jokainen suoritettavan käskyn viidestä vaiheesta suoritetaan eri laitteiston bitteissä varsinaisessa prosessoriytimessä. Jos siis olet varovainen laitteistoon syöttämiesi tietojen kanssa kussakin vaiheessa, voit pitää jokaisen niistä kiireisenä joka sykli. Täydellisessä maailmassa tämä voi johtaa 5-kertaiseen nopeuteen ja prosessorin täydelliseen skalaariin, joka suorittaa täyden ohjeen sykliä kohden.

Todellisuudessa ohjelmat ovat monimutkaisia ja vähentävät suorituskykyä. Jos sinulla on esimerkiksi kaksi lisäyskäskyä "a = b + c" ja "d = e + f", ne voidaan suorittaa putkessa ilman ongelmia. Jos sinulla on kuitenkin "a = b + c" ja "d = a + e", sinulla on ongelma. Olettaen, että nämä kaksi ohjetta ovat suoraan toistensa perässä, "a":n uuden arvon laskentaprosessi ei ole valmis, puhumattakaan siitä, että kirjoitetaan takaisin muistiin ennen kuin toinen käsky lukee "a":n vanhan arvon ja antaa sitten väärän vastauksen "d".
Tätä käyttäytymistä voidaan torjua ottamalla mukaan lähettäjä, joka analysoi tulevia ohjeita ja varmistaa, ettei toisesta riippuvaista käskyä ajeta liian läheisessä peräkkäisessä järjestyksessä. Se itse asiassa suorittaa ohjelman väärässä järjestyksessä korjatakseen tämän. Tämä toimii, koska monet ohjeet eivät välttämättä perustu edellisen tulokseen.
Liukulinjan laajentaminen superskalaariin
Superskalaariprosessori pystyy suorittamaan useamman kuin yhden täyden käskyn sykliä kohden. Yksi tapa tehdä tämä on laajentaa liukuhihnaa siten, että jokaisessa vaiheessa on kaksi tai useampia laitteistobittejä. Näin kaksi käskyä voi olla liukuhihnan jokaisessa vaiheessa jokaisessa syklissä. Tämä luonnollisesti lisää suunnittelun monimutkaisuutta, koska laitteisto monistetaan, mutta se tarjoaa erinomaiset suorituskyvyn skaalausmahdollisuudet.
Suorituskyvyn kasvu kasvavista putkistoista vain skaalautuu toistaiseksi tehokkaaksi. Lämpö- ja kokorajoitukset asettavat joitain rajoituksia. On myös merkittäviä aikataulukomplikaatioita. Tehokas työnvälittäjä on nyt entistä kriittisempi, koska sen on varmistettava, ettei kumpikaan kahdesta käskyjoukosta ole riippuvainen muiden käsiteltävien ohjeiden tuloksesta.
Haaraennustaja on osa lähettäjästä, joka muuttuu yhä kriittisemmäksi, mitä korkeampi superskalaari prosessori on. Joillakin ohjeilla voi olla kaksi mahdollista tulosta, joista jokainen johtaa erilaisiin seuraaviin ohjeisiin. Yksinkertainen esimerkki olisi "jos"-lause. "Jos tämä on totta, tee niin, muuten tee tämä toinen asia." Haaraennustaja yrittää ennustaa haarautumisoperaation lopputuloksen. Sen jälkeen se ajoittaa ja suorittaa ohjeet ennakoivasti noudattaen sitä, mitä se uskoo olevan todennäköinen.
Nykyaikaisissa haaraennusteissa on paljon monimutkaista logiikkaa, joka voi johtaa haaran ennustamisen onnistumisprosentteihin noin 98 %. Oikea ennuste säästää aikaa, joka olisi voitu hukata todellista tulosta odotellessa, virheellinen ennuste edellyttää, että ennustettu ohjeet ja kaikki niiden tulokset hylätään ja oikeat ohjeet ajetaan niiden tilalle, mikä tuo mukanaan pienen rangaistuksen odotti. Siten korkean ennusteen onnistumisprosentit voivat parantaa suorituskykyä huomattavasti.
Johtopäätös
Tietokoneen prosessoria pidetään superskalaarina, jos se pystyy suorittamaan useamman kuin yhden käskyn kellojaksoa kohden. Varhaiset tietokoneet olivat täysin peräkkäisiä, ja ne suorittivat vain yhden käskyn kerrallaan. Tämä tarkoitti sitä, että jokaisen käskyn suorittaminen kesti useamman kuin yhden syklin, joten nämä prosessorit olivat subskalaarisia. Perusliukuhihna, joka mahdollistaa vaihekohtaisen laitteiston hyödyntämisen käskyn jokaisessa vaiheessa, voi suorittaa enintään yhden käskyn kellojaksoa kohden, mikä tekee siitä skalaarisen.
On huomattava, että yksittäistä käskyä ei käsitellä täysin yhdessä kellojaksossa. Se kestää silti vähintään viisi sykliä. Useita ohjeita voi kuitenkin olla valmisteilla kerralla. Tämä mahdollistaa yhden tai useamman valmiin käskyn suorituskyvyn sykliä kohden.
Superscalaria ei pidä sekoittaa hyperscaleriin, joka viittaa yrityksiin, jotka voivat tarjota hyperskaalattavia laskentaresursseja. Hyperscale-laskenta sisältää mahdollisuuden skaalata saumattomasti laitteistoresursseja, kuten laskentaa, muistia, verkon kaistanleveyttä ja tallennustilaa kysynnän mukaan. Tämä löytyy tyypillisesti suurista datakeskuksista ja pilvilaskentaympäristöistä.