Dans presque tous les programmes informatiques, certaines parties du code se divisent en chemins séparés. Par exemple, une instruction if-then-else a deux résultats possibles. Ces instructions ne présentent aucun problème pour les processeurs séquentiels, car le processeur traite chaque commande dans l'ordre. Les branches présentent un gros problème pour les processeurs en pipeline, car plusieurs instructions sont exécutées à la fois.
Le scénario
Dans le cas d'un programme avec une instruction de branchement avec deux résultats possibles, les deux chemins de code possibles ne peuvent pas être au même endroit. Le traitement requis pour compléter l'une ou l'autre des options sera différent. Sinon, le programme ne créerait pas de branche. Il y aura probablement un bon nombre d'instructions de branchement qui ne seront prises qu'une seule fois, comme une instruction if.
Il existe également des instructions de branchement qui forment une boucle. Bien que celles-ci ne soient pas aussi courantes numériquement que les déclarations à usage unique, elles sont généralement répétées statistiquement. On peut supposer qu'il est plus probable qu'une branche vous ramène dans une boucle que non.
Pourquoi c'est un problème?
Peu importe la façon dont ce problème est formulé dans un processeur entièrement séquentiel. Ce n'est tout simplement pas un problème. La branche qui sera prise est connue avant que la première partie de l'instruction suivante ne soit traitée.
Dans un processeur en pipeline, cependant, les instructions suivantes sont mises en file d'attente. Ils sont déjà en cours de traitement lorsque le processeur sait quelle branche est prise. Alors, comment le processeur doit-il gérer ce scénario? Il y a quelques options. Le pire est simplement d'attendre et de laisser le pipeline inactif pendant qu'il attend la réponse sur la branche à prendre. Cela signifierait que chaque fois que vous avez une instruction de branchement, vous perdriez toujours au moins autant de cycles de temps processeur que vous avez d'étapes dans le pipeline.
Alternativement, vous pouvez essayer d'exécuter les deux options dans le pipeline et ignorer le mauvais choix. Cela entraînerait la moitié de la pénalité de ne rien faire, mais entraînerait toujours une pénalité de performance sur chaque instruction de branchement. Étant donné que les processeurs modernes peuvent également exécuter des instructions dans le désordre, vous pouvez potentiellement essayer d'exécuter chaque instruction de branchement dès que possible. Ainsi, son résultat est connu avant qu'il ne soit nécessaire. Cette option pourrait être utile, sauf qu'elle n'est pas évolutive. Supposons que vous ayez une densité relativement élevée d'instructions de branchement. Dans ce cas, vous ne pourrez tout simplement pas les exécuter tous tôt sans avoir un temps d'inactivité.
Comment ce problème est-il vraiment résolu
En réalité, le processeur comprend un prédicteur de branchement. Le prédicteur de branchement tente de deviner quel résultat d'un choix de branchement sera pris. Le processeur suppose alors que la prédiction est correcte et planifie les instructions. Si le prédicteur de branche est précis, il n'y a pas de pénalité de performances.
Si le prédicteur de branche fait une erreur, vous devez vider le pipeline et commencer à traiter le résultat réel. Cela entraîne une pénalité de performance légèrement pire que de ne rien faire et d'attendre le résultat. Pour obtenir les meilleures performances, il est important de s'assurer que le prédicteur de branche est aussi précis que possible. Il existe une gamme d'approches différentes à cet égard.
Code correspondant
Dans le code machine, une branche est toujours un choix entre lire l'instruction suivante ou sauter à un ensemble d'instructions ailleurs. Certaines premières implémentations de prédicteurs de branche supposaient simplement que toutes les branches seraient toujours ou ne seraient jamais prises. Cette implémentation peut avoir un taux de réussite étonnamment bon si les compilateurs connaissent ce comportement et sont conçu pour ajuster le code machine afin que le résultat le plus probable s'aligne sur le processeur général supposition. Cela nécessite beaucoup de réglage et d'ajustement des habitudes de développement de logiciels.
Une autre alternative consistait à apprendre de la statistique que les boucles sont généralement prises et sautent toujours si la branche recule dans le flux d'instructions et ne jamais sauter si le saut est vers l'avant car ce serait normalement l'état statistiquement le moins probable de quitter un boucle. Ce sont deux types de prédiction de branche statique, où le résultat d'une branche est prédit au moment de la compilation.
Prédicteurs dynamiques de branche
Les prédicteurs de branche modernes sont dynamiques et utilisent les statistiques du programme en cours d'exécution pour obtenir de meilleurs taux de réussite des prédictions. Un compteur saturant est une base pour tous les prédicteurs de branche actuels. La première estimation est décidée de manière statique ou aléatoire. Une fois qu'une branche a été prise ou non, ce résultat est stocké dans une partie de la mémoire. La prochaine fois que la même branche apparaît, le prédicteur de branche prédit le même résultat qu'avant.
Cela se traduit naturellement par de bons taux de prédiction pour les boucles. Il existe deux versions de cela. Les premières versions utilisaient simplement un seul bit de données pour indiquer si la branche était prise ou non. Les versions ultérieures utilisent deux bits pour indiquer un choix faiblement ou fortement pris ou non pris. Cette configuration peut toujours prédire le résultat de la prise d'une boucle si le programme y revient, augmentant généralement les taux de réussite.
Modèles de suivi
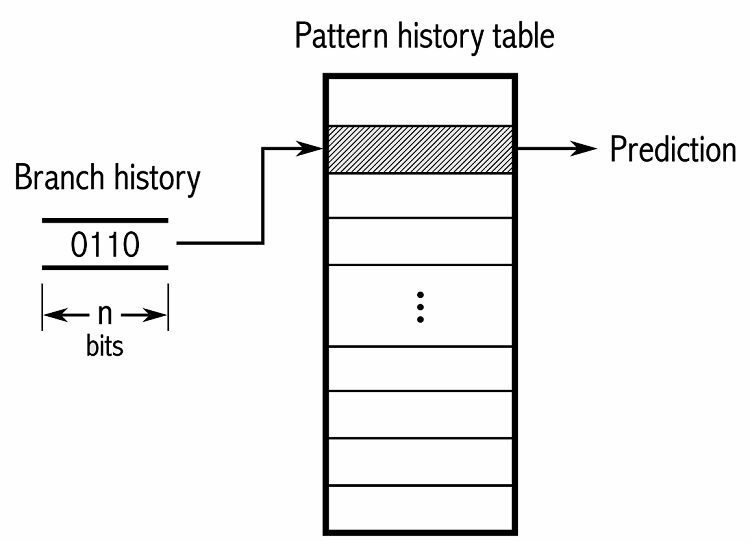
Pour suivre les modèles, certains prédicteurs de branche gardent une trace d'un historique des choix qui ont été faits. Par exemple, supposons qu'une boucle soit appelée en continu mais ne boucle que quatre fois environ avant de sortir de la boucle. Dans ce cas, un prédicteur adaptatif à deux niveaux peut identifier ce modèle et prédire qu'il se reproduira. Cela augmente encore plus les taux de réussite par rapport à un simple compteur saturé. Les prédicteurs de branche modernes s'appuient sur cela en utilisant un réseau de neurones pour repérer et prédire les modèles.
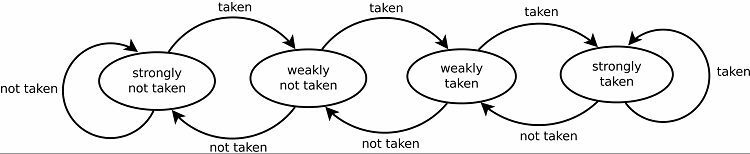
Certains prédicteurs de branche utilisent plusieurs algorithmes, puis comparent les résultats pour décider quelle prédiction utiliser. Certains systèmes gardent une trace de chaque instruction de branchement séparément dans ce qu'on appelle la prédiction de branchement local. D'autres utilisent un système global de prédiction de branchement pour suivre toutes les instructions de branchement récentes. Les deux ont leurs avantages et leurs inconvénients.
Conclusion
Un prédicteur de branche est une partie spéciale d'un processeur en pipeline. Il tente de prédire le résultat d'une instruction de branchement avant que l'instruction réelle ne soit traitée. Il s'agit d'une fonction essentielle d'un processeur en pipeline car il permet au processeur de maintenir le pipeline saturé même s'il n'est pas sûr des instructions à exécuter. Ils n'offrent aucune réduction des performances lorsqu'ils sont corrects. Les algorithmes modernes peuvent être précis dans des charges de travail relativement prévisibles jusqu'à 97 % du temps.
Il n'y a pas de méthode de prédiction parfaite, donc les implémentations varient. L'impact sur les performances d'une prédiction erronée dépend de la longueur du pipeline. Plus précisément, la longueur du pipeline avant de pouvoir déterminer si la prédiction était erronée. Cela dépend également du nombre d'instructions dans chaque étape du pipeline. Les processeurs de bureau haut de gamme modernes ont environ 19 étapes de pipeline et peuvent exécuter au moins quatre instructions simultanément à chaque étape.