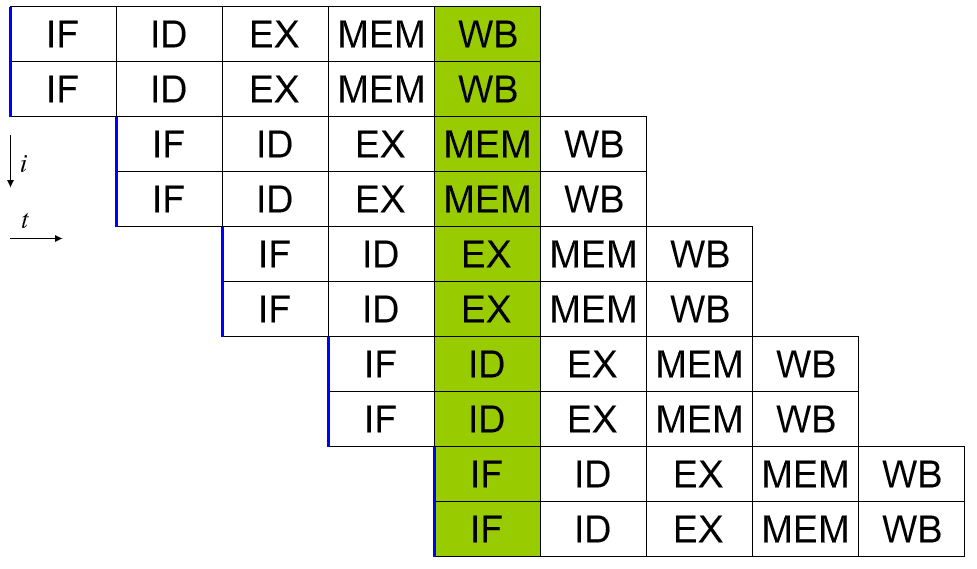
Les premiers ordinateurs étaient entièrement séquentiels. Chaque instruction reçue par le processeur devait être entièrement exécutée avant que la suivante puisse être lancée. Il y a cinq étapes dans la plupart des instructions: récupération d'instructions, décodage d'instructions, exécution, accès mémoire et écriture différée. Respectivement ces étapes reçoivent l'instruction qui doit être complétée, séparent l'opération des valeurs à opéré, exécuter l'opération, ouvrir le registre sur lequel le résultat sera écrit, et écrire le résultat dans le registre ouvert S'inscrire.
Chacune de ces étapes devrait prendre un cycle à compléter. Malheureusement, si les données ne sont pas dans un registre, elles doivent être demandées à partir du cache CPU ou de la RAM système. C'est beaucoup plus lent, ajoutant des dizaines ou des centaines de cycles d'horloge de latence. En attendant, tout le reste doit attendre car aucune autre donnée ou instruction ne peut être traitée. Ce type de conception de processeur est appelé sous-scalaire car il exécute moins d'une instruction par cycle d'horloge.

Pipeline vers scalaire
Un processeur scalaire peut être obtenu en appliquant un pipeline système. Chacune des cinq étapes d'une instruction en cours d'exécution s'exécute dans différents bits de matériel dans le cœur du processeur réel. Ainsi, si vous faites attention aux données que vous introduisez dans le matériel pour chaque étape, vous pouvez occuper chacune d'elles à chaque cycle. Dans un monde parfait, cela pourrait conduire à une accélération de 5 fois et au processeur d'être parfaitement scalaire, exécutant une instruction complète par cycle.

En réalité, les programmes sont complexes et réduisent le débit. Par exemple, si vous avez deux instructions d'addition "a = b + c" et "d = e + f", celles-ci peuvent être exécutées dans un pipeline sans problème. Si, cependant, vous avez "a = b + c" suivi de "d = a + e", vous avez un problème. En supposant que ces deux instructions se suivent directement, le processus de calcul de la nouvelle valeur de "a" ne sera pas terminé, et encore moins être réécrit en mémoire avant que la deuxième instruction ne lise l'ancienne valeur de "a" et donne ensuite la mauvaise réponse pour "ré".
Ce comportement peut être contré par l'inclusion d'un répartiteur, qui analyse les instructions à venir et s'assure qu'aucune instruction dépendante d'une autre n'est exécutée en succession trop rapprochée. Il exécute en fait le programme dans le mauvais ordre pour résoudre ce problème. Cela fonctionne, car de nombreuses instructions ne reposent pas nécessairement sur le résultat d'une précédente.
Extension du pipeline au superscalaire
Un processeur superscalaire est capable d'exécuter plus d'une instruction complète par cycle. Une façon d'y parvenir consiste à étendre le pipeline afin qu'il y ait deux éléments matériels ou plus capables de gérer chaque étape. De cette façon, deux instructions peuvent se trouver à chaque étape du pipeline à chaque cycle. Cela se traduit évidemment par une complexité de conception accrue car le matériel est dupliqué, cependant, cela offre d'excellentes possibilités de mise à l'échelle des performances.
L'augmentation des performances due à l'augmentation des pipelines ne s'échelonne jusqu'à présent que de manière efficace. Les contraintes thermiques et dimensionnelles imposent certaines limites. Il existe également d'importantes complications d'ordonnancement. Un répartiteur efficace est maintenant encore plus critique car il doit s'assurer qu'aucun des deux ensembles d'instructions ne repose sur le résultat de l'une des autres instructions en cours de traitement.
Un prédicteur de branche est une partie du répartiteur qui devient de plus en plus critique à mesure qu'un processeur est hautement superscalaire. Certaines instructions peuvent avoir deux résultats potentiels, chacun conduisant à des instructions suivantes différentes. Un exemple simple serait une instruction « si ». "Si c'est vrai, fais ça, sinon fais autre chose". Un prédicteur de branchement tente de prédire le résultat d'une opération de branchement. Il planifie et exécute ensuite de manière préventive les instructions en fonction de ce qu'il pense être le résultat probable.
Il y a beaucoup de logique complexe dans les prédicteurs de branche modernes, qui peuvent entraîner des taux de réussite de prédiction de branche de l'ordre de 98 %. Une prédiction correcte permet d'économiser le temps qui aurait pu être perdu à attendre le résultat réel, une prédiction incorrecte nécessite que la prédiction les instructions et l'un de leurs résultats soient ignorés et les vraies instructions soient exécutées à leur place, ce qui entraîne une légère pénalité pour avoir juste attendu. Ainsi, des taux de réussite de prédiction élevés peuvent augmenter sensiblement les performances.
Conclusion
Un processeur informatique est considéré comme superscalaire s'il peut exécuter plus d'une instruction par cycle d'horloge. Les premiers ordinateurs étaient entièrement séquentiels, exécutant une seule instruction à la fois. Cela signifiait que chaque instruction prenait plus d'un cycle pour se terminer et que ces processeurs étaient donc sous-scalaires. Un pipeline de base qui permet l'utilisation du matériel spécifique à chaque étape d'une instruction peut exécuter au plus une instruction par cycle d'horloge, ce qui le rend scalaire.
Il convient de noter qu'aucune instruction individuelle n'est entièrement traitée en un seul cycle d'horloge. Il faut encore au moins cinq cycles. Cependant, plusieurs instructions peuvent être dans le pipeline à la fois. Cela permet un débit d'une ou plusieurs instructions terminées par cycle.
Superscalar ne doit pas être confondu avec hyperscaler qui fait référence aux entreprises qui peuvent offrir des ressources informatiques hyperscale. L'informatique à très grande échelle inclut la possibilité de mettre à l'échelle de manière transparente les ressources matérielles, telles que le calcul, la mémoire, la bande passante réseau et le stockage, en fonction de la demande. Cela se trouve généralement dans les grands centres de données et les environnements de cloud computing.