Komputer awal sepenuhnya berurutan. Setiap instruksi yang diterima prosesor harus diselesaikan secara lengkap sebelum instruksi berikutnya dapat dimulai. Ada lima tahap untuk sebagian besar instruksi: Pengambilan instruksi, Penguraian kode instruksi, Eksekusi, Akses memori, dan Writeback. Masing-masing tahapan ini mendapatkan instruksi yang perlu diselesaikan, pisahkan operasi dari nilai yang ada dioperasi, jalankan operasi, buka register di mana hasilnya akan ditulis, dan tulis hasilnya ke yang dibuka daftar.
Masing-masing tahapan ini membutuhkan satu siklus untuk diselesaikan. Sayangnya, jika data tidak ada dalam register, maka harus diminta dari cache CPU atau RAM sistem. Ini jauh lebih lambat, menambahkan lusinan atau ratusan siklus jam latensi. Sementara itu, segala sesuatu yang lain perlu menunggu karena tidak ada data atau instruksi lain yang dapat diproses. Jenis desain prosesor ini disebut subskalar karena menjalankan kurang dari satu instruksi per siklus clock.

Pipelining ke skalar
Sebuah prosesor skalar dapat dicapai dengan menerapkan sistem pipa. Masing-masing dari lima tahap instruksi yang dieksekusi dijalankan di bit perangkat keras yang berbeda di inti prosesor yang sebenarnya. Jadi, jika Anda berhati-hati dengan data yang Anda masukkan ke perangkat keras untuk setiap tahap, Anda dapat membuat masing-masing dari mereka sibuk setiap siklus. Di dunia yang sempurna, ini dapat menghasilkan kecepatan 5x lebih tinggi dan prosesor menjadi skalar sempurna, menjalankan instruksi penuh per siklus.

Pada kenyataannya, program itu rumit dan mengurangi throughput. Misalnya, jika Anda memiliki dua instruksi tambahan “a = b + c” dan “d = e + f”, ini dapat dijalankan dalam pipeline tanpa masalah. Namun, jika Anda memiliki "a = b + c" diikuti oleh "d = a + e", Anda memiliki masalah. Dengan asumsi kedua instruksi ini secara langsung setelah satu sama lain, proses untuk menghitung nilai baru "a" tidak akan selesai, apalagi ditulis kembali ke memori sebelum instruksi kedua membaca nilai lama "a" dan kemudian memberikan jawaban yang salah untuk "d".
Perilaku ini dapat dilawan dengan penyertaan petugas operator, yang menganalisis instruksi yang akan datang dan memastikan bahwa tidak ada instruksi yang bergantung pada yang lain yang dijalankan dalam urutan yang terlalu dekat. Ini sebenarnya menjalankan program dalam urutan yang salah untuk memperbaikinya. Ini berfungsi, karena banyak instruksi tidak selalu bergantung pada hasil yang sebelumnya.
Memperluas pipa ke superscalar
Prosesor superscalar mampu menjalankan lebih dari satu instruksi penuh per siklus. Salah satu cara untuk melakukan ini adalah dengan memperluas pipa sehingga ada dua atau lebih bit perangkat keras yang dapat menangani setiap tahap. Dengan cara ini dua instruksi dapat berada di setiap tahap pipa di setiap siklus. Ini jelas menghasilkan peningkatan kompleksitas desain karena perangkat keras diduplikasi, namun, ia menawarkan kemungkinan penskalaan kinerja yang sangat baik.
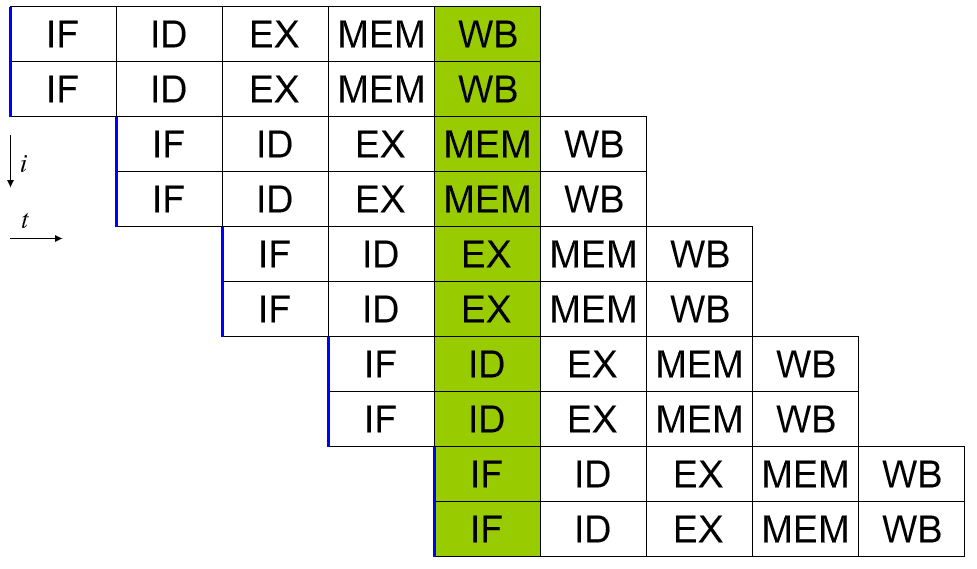
Peningkatan kinerja dari peningkatan jaringan pipa hanya sejauh ini secara efisien. Kendala termal dan ukuran menempatkan beberapa batasan. Ada juga komplikasi penjadwalan yang signifikan. Dispatcher yang efisien sekarang bahkan lebih kritis karena harus memastikan bahwa tidak satu pun dari dua set instruksi bergantung pada hasil dari instruksi lain yang sedang diproses.
Prediktor cabang adalah bagian dari operator yang semakin kritis semakin tinggi skalar prosesornya. Beberapa instruksi dapat memiliki dua hasil potensial, masing-masing mengarah ke instruksi berikut yang berbeda. Contoh sederhananya adalah pernyataan “jika”. "Jika ini benar lakukan itu, jika tidak lakukan hal lain ini". Sebuah prediktor cabang mencoba untuk memprediksi hasil dari operasi percabangan. Kemudian secara pre-emptive menjadwalkan dan mengeksekusi instruksi mengikuti apa yang diyakini sebagai kemungkinan hasil.
Ada banyak logika kompleks dalam prediktor cabang modern, yang dapat menghasilkan tingkat keberhasilan prediksi cabang di urutan 98%. Prediksi yang benar menghemat waktu yang bisa saja terbuang untuk menunggu hasil yang sebenarnya, prediksi yang salah mengharuskan prediksi instruksi dan salah satu hasilnya dibuang dan instruksi yang benar dijalankan di tempat mereka, yang datang dengan sedikit hukuman karena baru saja menunggu. Jadi, tingkat keberhasilan prediksi tinggi dapat meningkatkan kinerja secara nyata.
Kesimpulan
Sebuah prosesor komputer dianggap superscalar jika dapat melakukan lebih dari satu instruksi per siklus clock. Komputer awal sepenuhnya berurutan, hanya menjalankan satu instruksi pada satu waktu. Ini berarti bahwa setiap instruksi membutuhkan lebih dari satu siklus untuk diselesaikan sehingga prosesor ini adalah subskalar. Pipa dasar yang memungkinkan pemanfaatan perangkat keras khusus tahap untuk setiap tahap instruksi dapat mengeksekusi paling banyak satu instruksi per siklus jam, menjadikannya skalar.
Perlu dicatat bahwa tidak ada instruksi individu yang sepenuhnya diproses dalam satu siklus clock. Masih membutuhkan setidaknya lima siklus. Beberapa instruksi, bagaimanapun, dapat di dalam pipa sekaligus. Hal ini memungkinkan throughput satu atau lebih instruksi lengkap per siklus.
Superscalar tidak harus bingung dengan hyperscaler yang mengacu pada perusahaan yang dapat menawarkan sumber daya komputasi hyperscale. Komputasi hyperscale mencakup kemampuan untuk menskalakan sumber daya perangkat keras dengan mulus, seperti komputasi, memori, bandwidth jaringan, dan penyimpanan, sesuai permintaan. Ini biasanya ditemukan di pusat data besar dan lingkungan komputasi awan.