In quasi tutti i programmi per computer, ci sono parti del codice che si ramificano in percorsi separati. Ad esempio, un'istruzione if-then-else ha due possibili risultati. Queste istruzioni non presentano alcun problema ai processori sequenziali, poiché la CPU elabora ogni comando in ordine. I rami rappresentano un grosso problema per i processori pipeline, poiché più istruzioni vengono eseguite contemporaneamente.
Lo scenario
Nel caso di un programma con un'istruzione branching con due possibili esiti, i due possibili percorsi di codice non possono trovarsi nello stesso posto. L'elaborazione richiesta per completare entrambe le opzioni sarà diversa. Altrimenti, il programma non si ramificherebbe. Probabilmente ci sarà un discreto numero di istruzioni ramificate che vengono prese solo una volta, come un'istruzione if.
Ci sono anche istruzioni ramificate che formano un ciclo. Anche se questi potrebbero non essere numericamente comuni come le dichiarazioni monouso, sono generalmente ripetuti statisticamente. Si può presumere che è più probabile che un ramo ti riporti indietro in un ciclo piuttosto che no.
Perché questo è un problema?
Non importa come questo problema sia formulato in un processore completamente sequenziale. Semplicemente non è un problema. Quale ramo verrà preso è noto prima che venga elaborata la prima parte dell'istruzione successiva.
In un processore pipeline, tuttavia, le seguenti istruzioni sono accodate. Sono già in fase di elaborazione quando il processore sa quale ramo viene preso. Quindi, come dovrebbe il processore gestire questo scenario? Ci sono alcune opzioni. Il peggio è semplicemente aspettare e lasciare la pipeline inattiva mentre attende la risposta su quale ramo prendere. Ciò significherebbe che ogni volta che si dispone di un'istruzione branching, si perderebbero sempre almeno tanti cicli di tempo del processore quante sono le fasi nella pipeline.
In alternativa, puoi provare a eseguire entrambe le opzioni nella pipeline e scartare la scelta sbagliata. Ciò comporterebbe la metà della penalità di non fare nulla, ma incorrerebbe comunque in una penalità di prestazione su ogni dichiarazione di ramificazione. Dato che le moderne CPU possono anche eseguire istruzioni fuori servizio, potresti potenzialmente tentare di eseguire ogni istruzione di ramificazione il prima possibile. Quindi il suo risultato è noto prima che sia necessario. Questa opzione potrebbe essere utile, tranne per il fatto che non è scalabile. Supponiamo di avere una densità relativamente alta di istruzioni ramificate. In tal caso, non sarai semplicemente in grado di eseguirli tutti in anticipo senza avere un po' di tempo di inattività.
Come viene davvero affrontato questo problema
In realtà, il processore include un predittore di ramificazione. Il predittore di ramificazione tenta di indovinare quale risultato di una scelta di ramificazione verrà preso. Il processore presume quindi che la previsione sia corretta e pianifica le istruzioni. Se il predittore di diramazione è accurato, non vi è alcuna penalizzazione delle prestazioni.
Se il predittore di diramazione commette un errore, è necessario svuotare la pipeline e iniziare a elaborare il risultato effettivo. Ciò si traduce in una penalità di prestazione leggermente peggiore rispetto a non aver fatto nulla e aver semplicemente aspettato il risultato. Per ottenere le migliori prestazioni, è importante assicurarsi che il predittore di diramazione sia il più accurato possibile. C'è una gamma di approcci diversi a questo.
Codice di corrispondenza
Nel codice macchina, un ramo è sempre una scelta tra leggere l'istruzione successiva o saltare a un insieme di istruzioni altrove. Alcune prime implementazioni di predittori di rami presumevano semplicemente che tutti i rami sarebbero stati sempre o mai presi. Questa implementazione può avere una percentuale di successo sorprendentemente buona se i compilatori conoscono questo comportamento e lo sono progettato per regolare il codice macchina in modo che il risultato più probabile sia allineato con il generale del processore assunzione. Ciò richiede molta messa a punto e regolazione delle abitudini di sviluppo del software.
Un'altra alternativa era imparare dalla statistica che i loop sono generalmente presi e saltano sempre se il ramo va indietro nel flusso di istruzioni e non saltare mai se il salto è in avanti perché quello sarebbe normalmente lo stato statisticamente meno probabile di lasciare a ciclo continuo. Questi sono entrambi i tipi di previsione del ramo statico, in cui il risultato di un ramo viene previsto in fase di compilazione.
Predittori di rami dinamici
I moderni predittori di filiale sono dinamici e utilizzano le statistiche del programma attualmente in esecuzione per ottenere tassi di successo delle previsioni migliori. Un contatore di saturazione è una base per tutti gli attuali predittori di diramazione. La prima ipotesi viene decisa in modo statico o casuale. Una volta che un ramo è stato preso o non preso, quel risultato viene archiviato in una porzione di memoria. La prossima volta che si verifica lo stesso ramo, il predittore di ramo prevede lo stesso risultato di prima.
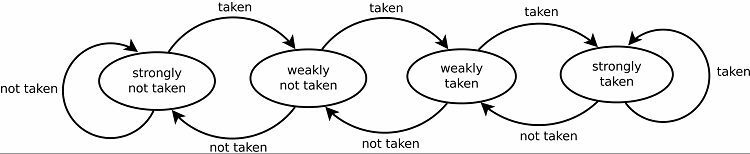
Ciò si traduce naturalmente in buoni tassi di previsione per i loop. Ci sono due versioni di questo. Le prime versioni utilizzavano semplicemente un singolo bit di dati per indicare se il ramo era stato preso o meno. Le versioni successive usano due bit per indicare una scelta presa o non presa debolmente o fortemente. Questa configurazione può ancora prevedere il risultato dell'esecuzione di un ciclo se il programma ritorna ad esso, aumentando generalmente le percentuali di successo.
Modelli di tracciamento
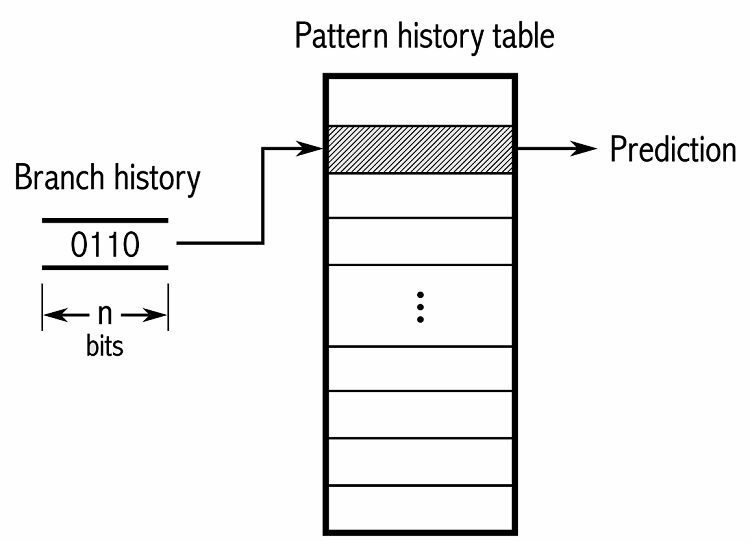
Per tenere traccia dei modelli, alcuni predittori di ramo tengono traccia di una cronologia delle scelte effettuate. Ad esempio, supponiamo che un ciclo venga chiamato continuamente ma che venga eseguito solo quattro volte prima di interromperlo. In tal caso, un predittore adattivo a due livelli può identificare questo modello e prevedere che si ripeta. Ciò aumenta ulteriormente le percentuali di successo rispetto a un semplice contatore saturo. I moderni predittori di ramo si basano ulteriormente su questo utilizzando una rete neurale per individuare e prevedere i modelli.
Alcuni predittori di ramo utilizzano più algoritmi e quindi confrontano i risultati per decidere quale previsione utilizzare. Alcuni sistemi tengono traccia di ciascuna istruzione di diramazione separatamente in quella che viene chiamata previsione di diramazione locale. Altri utilizzano un sistema globale di previsione delle diramazioni per tenere traccia di tutte le recenti istruzioni di diramazione. Entrambi hanno i loro usi e svantaggi.
Conclusione
Un predittore di ramo è una parte speciale di una CPU pipeline. Tenta di prevedere il risultato di un'istruzione di ramificazione prima che l'istruzione effettiva venga elaborata. Questa è una funzione fondamentale di una CPU pipeline in quanto consente alla CPU di mantenere la pipeline satura anche se non è sicuro di quali istruzioni devono essere eseguite. Non offrono alcuna riduzione delle prestazioni quando sono corretti. Gli algoritmi moderni possono essere accurati in carichi di lavoro relativamente prevedibili fino al 97% delle volte.
Non esiste un metodo di previsione perfetto, quindi le implementazioni variano. L'impatto sulle prestazioni di una previsione errata dipende dalla lunghezza della pipeline. In particolare, la lunghezza della pipeline prima che possa essere determinata se la previsione era errata. Dipende anche da quante istruzioni sono presenti in ciascuna fase della pipeline. Le moderne CPU desktop di fascia alta hanno circa 19 fasi della pipeline e possono eseguire almeno quattro istruzioni contemporaneamente in ciascuna fase.