I primi computer erano interamente sequenziali. Ogni istruzione ricevuta dal processore doveva essere completata per intero in ordine prima che potesse essere avviata quella successiva. Ci sono cinque fasi per la maggior parte delle istruzioni: recupero dell'istruzione, decodifica dell'istruzione, esecuzione, accesso alla memoria e writeback. Rispettivamente queste fasi ottengono l'istruzione che deve essere completata, separano l'operazione dai valori in essere operato, eseguire l'operazione, aprire il registro su cui verrà scritto il risultato e scrivere il risultato nell'open Registrati.
Ciascuna di queste fasi dovrebbe richiedere un ciclo per essere completata. Sfortunatamente, se i dati non sono in un registro, devono essere richiesti dalla cache della CPU o dalla RAM di sistema. Questo è molto più lento, aggiungendo dozzine o centinaia di cicli di clock di latenza. Nel frattempo, tutto il resto deve attendere poiché non è possibile elaborare altri dati o istruzioni. Questo tipo di progettazione del processore è chiamato subscalare poiché esegue meno di un'istruzione per ciclo di clock.

Pipelining a scalare
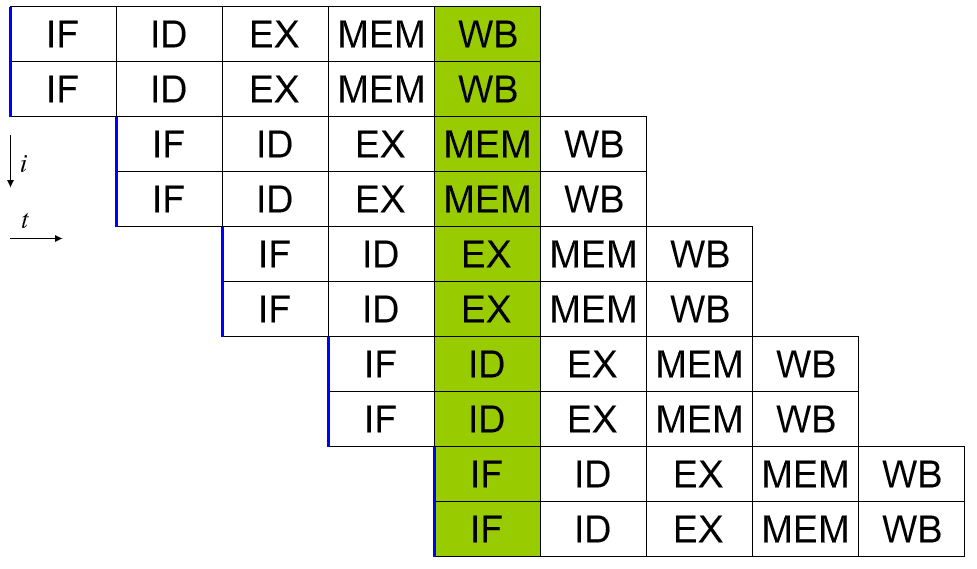
Un processore scalare può essere ottenuto applicando una pipeline di sistema. Ciascuna delle cinque fasi di un'istruzione eseguita viene eseguita in diversi bit di hardware nel core del processore effettivo. Pertanto, se stai attento con i dati che inserisci nell'hardware per ogni fase, puoi tenerli occupati ogni ciclo. In un mondo perfetto, questo potrebbe portare a una velocità 5 volte superiore e al processore perfettamente scalare, eseguendo un'istruzione completa per ciclo.

In realtà, i programmi sono complessi e riducono il throughput. Ad esempio, se hai due istruzioni di addizione "a = b + c" e "d = e + f", queste possono essere eseguite in una pipeline senza problemi. Se, invece, hai “a = b + c” seguito da “d = a + e” hai un problema. Supponendo che queste due istruzioni siano direttamente una dopo l'altra, il processo per calcolare il nuovo valore di "a" non sarà completato, per non parlare di essere riscritto in memoria prima che la seconda istruzione legga il vecchio valore di "a" e quindi fornisca la risposta sbagliata "d".
Questo comportamento può essere contrastato con l'inclusione di un dispatcher, che analizza le istruzioni imminenti e garantisce che nessuna istruzione dipendente da un'altra venga eseguita in una successione troppo ravvicinata. In realtà esegue il programma nell'ordine sbagliato per risolvere questo problema. Funziona, perché molte istruzioni non si basano necessariamente sul risultato di una precedente.
Espandere la pipeline a superscalare
Un processore superscalare è in grado di eseguire più di un'istruzione completa per ciclo. Un modo per farlo è espandere la pipeline in modo che ci siano due o più bit di hardware in grado di gestire ogni fase. In questo modo possono essere presenti due istruzioni in ogni fase della pipeline in ogni ciclo. Ciò si traduce ovviamente in una maggiore complessità di progettazione poiché l'hardware è duplicato, tuttavia offre eccellenti possibilità di ridimensionamento delle prestazioni.
Tuttavia, l'aumento delle prestazioni derivante dall'aumento delle condutture aumenta solo fino ad ora in modo efficiente. I vincoli termici e dimensionali pongono alcuni limiti. Ci sono anche complicazioni di pianificazione significative. Un dispatcher efficiente è ora ancora più critico in quanto deve garantire che nessuno dei due insiemi di istruzioni si basi sul risultato dell'elaborazione di una qualsiasi delle altre istruzioni.
Un predittore di ramo è una parte del dispatcher che diventa sempre più critica quanto più altamente superscalare è un processore. Alcune istruzioni possono avere due potenziali risultati, ognuno dei quali porta a istruzioni successive diverse. Un semplice esempio potrebbe essere un'istruzione "se". “Se questo è vero fai quello, altrimenti fai quest'altro”. Un predittore di diramazione tenta di prevedere l'esito di un'operazione di diramazione. Quindi pianifica ed esegue preventivamente le istruzioni seguendo quello che ritiene essere il probabile risultato.
C'è molta logica complessa nei moderni predittori di ramo, che può comportare tassi di successo della previsione di ramo dell'ordine del 98%. Una previsione corretta consente di risparmiare il tempo che avrebbe potuto essere sprecato in attesa del risultato effettivo, una previsione errata richiede che la previsione le istruzioni e tutti i loro risultati vengono scartati e le istruzioni vere vengono eseguite al loro posto, il che comporta una leggera penalità per aver solo aspettato. Pertanto, le percentuali di successo delle previsioni elevate possono aumentare notevolmente le prestazioni.
Conclusione
Un processore per computer è considerato superscalare se può eseguire più di un'istruzione per ciclo di clock. I primi computer erano interamente sequenziali, eseguivano solo un'istruzione alla volta. Ciò significava che ogni istruzione richiedeva più di un ciclo per essere completata e quindi questi processori erano subscalari. Una pipeline di base che consente l'utilizzo dell'hardware specifico dello stadio per ogni stadio di un'istruzione può eseguire al massimo un'istruzione per ciclo di clock, rendendola scalare.
Va notato che nessuna singola istruzione viene elaborata completamente in un singolo ciclo di clock. Ci vogliono ancora almeno cinque cicli. Più istruzioni, tuttavia, possono essere in cantiere contemporaneamente. Ciò consente un throughput di una o più istruzioni completate per ciclo.
Superscalar non deve essere confuso con hyperscaler che si riferisce alle aziende in grado di offrire risorse di calcolo iperscalabili. L'hyperscale computing include la capacità di scalare senza problemi le risorse hardware, come elaborazione, memoria, larghezza di banda di rete e storage, in base alla domanda. Questo si trova in genere nei grandi data center e negli ambienti di cloud computing.