מחשבים מוקדמים היו לגמרי עוקבים. כל הוראה שהמעבד קיבל הייתה צריכה להסתיים במלואה לפי הסדר לפני שניתן היה להתחיל את ההוראה הבאה. ישנם חמישה שלבים לרוב ההוראות: אחזור הוראות, פענוח הוראות, ביצוע, גישה לזיכרון וכתיבה חוזרת. בהתאמה שלבים אלו מקבלים את ההוראה שצריך להשלים, מפרידים את הפעולה מההוויה הערכים מנותח, בצע את הפעולה, פתח את הפנקס עליו תיכתב התוצאה, וכתוב את התוצאה לפתוח הירשם.
כל אחד מהשלבים הללו צריך לקחת מחזור אחד. למרבה הצער, אם הנתונים אינם נמצאים ברישום, יש לבקש אותם ממטמון ה-CPU או מ-RAM של המערכת. זה הרבה יותר איטי, ומוסיף עשרות או מאות מחזורי שעון של חביון. בינתיים, כל השאר צריך להמתין מכיוון שלא ניתן לעבד נתונים או הוראות אחרות. סוג זה של עיצוב מעבד נקרא תת-סקלארי מכיוון שהוא מריץ פחות מהוראה אחת לכל מחזור שעון.

צנרת לסקלרית
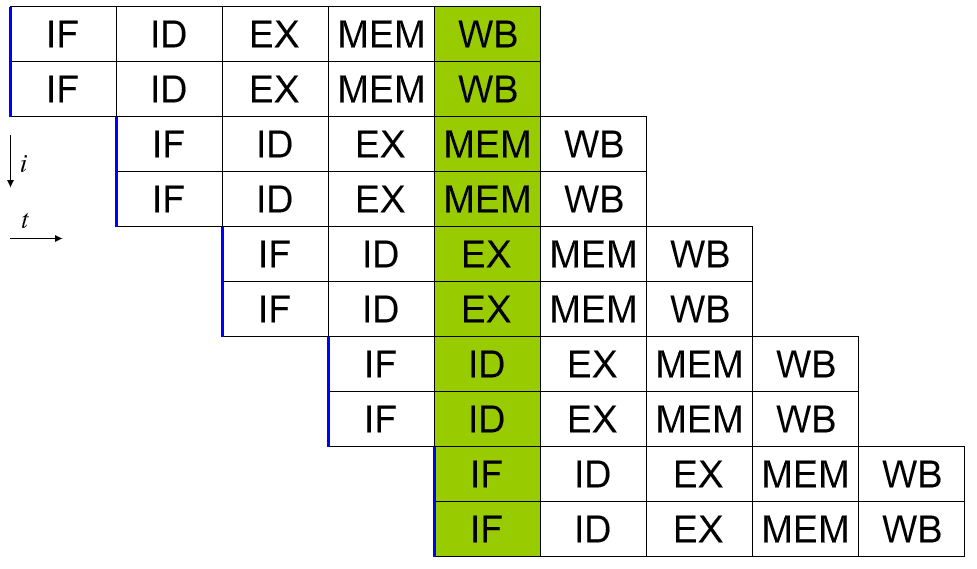
ניתן להשיג מעבד סקלארי על ידי יישום צינור מערכת. כל אחד מחמשת השלבים של הוראה שמתבצעת פועל בסיביות שונות של חומרה בליבת המעבד בפועל. לפיכך, אם אתה נזהר בנתונים שאתה מזין לחומרה עבור כל שלב, אתה יכול להעסיק כל אחד מהם בכל מחזור. בעולם מושלם, זה יכול להוביל להאצה של פי 5 ולמעבד להיות סקלרי מושלם, תוך הפעלת הוראה מלאה בכל מחזור.

במציאות, תוכניות מורכבות ומפחיתות את התפוקה. לדוגמה, אם יש לך שתי הוראות הוספה "a = b + c" ו- "d = e + f" ניתן להפעיל אותן בצינור ללא בעיה. עם זאת, אם יש לך "a = b + c" ואחריו "d = a + e" יש לך בעיה. בהנחה ששתי ההוראות הללו נמצאות ישירות אחת אחרי השנייה, התהליך לחישוב הערך החדש של "a" לא יסתיים, שלא לדבר על כתיבה חזרה לזיכרון לפני שההוראה השנייה קוראת את הערך הישן של "a" ואז נותנת את התשובה השגויה עבור "ד".
ניתן להתמודד עם התנהגות זו עם הכללת שדר, שמנתח הוראות עתידיות ומבטיח ששום הוראה שתלויה באחר לא מופעלת ברצף קרוב מדי. זה למעשה מריץ את התוכנית בסדר הלא נכון כדי לתקן את זה. זה עובד, מכיוון שהוראות רבות אינן בהכרח מסתמכות על התוצאה של קודמתה.
הרחבת הצינור לסופר סקלארי
מעבד על-סקלארי מסוגל להריץ יותר מהוראה אחת מלאה בכל מחזור. אחת הדרכים לעשות זאת היא על ידי הרחבת הצינור כך שיהיו שניים או יותר חלקי חומרה שיכולים להתמודד עם כל שלב. בדרך זו שתי הוראות יכולות להיות בכל שלב של הצינור בכל מחזור. זה כמובן מביא למורכבות עיצוב מוגברת מכיוון שהחומרה משוכפלת, עם זאת, היא מציעה אפשרויות קנה מידה מצוינות לביצועים.
עליית הביצועים מהגדלת צינורות רק מתרחבת עד כה ביעילות. מגבלות תרמיות וגודל מציבות גבולות מסוימים. ישנם גם סיבוכים משמעותיים בתזמון. משלח יעיל הוא כעת קריטי אף יותר מכיוון שעליו להבטיח שאף אחת משתי קבוצות ההוראות לא מסתמכות על התוצאה של אף אחת מההוראות האחרות המעובדות.
מנבא ענפים הוא חלק מהשולח שנעשה יותר ויותר קריטי ככל שהמעבד הוא בעל רמה גבוהה יותר של סופר סקלר. לחלק מההוראות יכולות להיות שתי תוצאות פוטנציאליות, שכל אחת מהן מובילה להנחיות שונות. דוגמה פשוטה תהיה הצהרת "אם". "אם זה נכון תעשה את זה, אחרת תעשה את הדבר האחר הזה". מנבא ענפים מנסה לחזות את התוצאה של פעולת הסתעפות. לאחר מכן, הוא מתזמן ומבצע את ההוראות מראש לפי מה שלדעתו הוא התוצאה הסבירה.
יש הרבה היגיון מורכב במנבאי סניפים מודרניים, שיכול לגרום לאחוזי הצלחה של חיזוי ענפים בסדר גודל של 98%. חיזוי נכון חוסך את הזמן שיכול היה להתבזבז בהמתנה לתוצאה בפועל, חיזוי שגוי מחייב את החזוי הוראות וכל אחת מהתוצאות שלהן יושלכו וההוראות האמיתיות יופעלו במקומן, מה שמגיע עם עונש קל על רק חיכה. לפיכך אחוזי הצלחה גבוהים יכולים להגביר את הביצועים בצורה ניכרת.
סיכום
מעבד מחשב נחשב על-סקלרי אם הוא יכול לבצע יותר מהוראה אחת בכל מחזור שעון. מחשבים מוקדמים היו לגמרי עוקבים, והריצו רק הוראה אחת בכל פעם. משמעות הדבר היא שכל הוראה לקחה יותר ממחזור אחד לבצע, ולכן המעבדים הללו היו תת-סקלארים. צינור בסיסי המאפשר ניצול של החומרה הספציפית לשלב עבור כל שלב של הוראה יכול לבצע לכל היותר הוראה אחת לכל מחזור שעון, מה שהופך אותה לסקלרית.
יש לציין שאף הוראה בודדת לא מעובדת במלואה במחזור שעון בודד. זה עדיין לוקח לפחות חמישה מחזורים. עם זאת, יכולות להיות הנחיות מרובות בבת אחת. זה מאפשר תפוקה של פקודה אחת או יותר שהושלמו לכל מחזור.
אין לבלבל בין Superscalar לבין Hyperscaler המתייחס לחברות שיכולות להציע משאבי מחשוב היפר-scale. מחשוב בקנה מידה גבוה כולל את היכולת להרחיב בצורה חלקה את משאבי החומרה, כגון מחשוב, זיכרון, רוחב פס רשת ואחסון, לפי דרישה. זה נמצא בדרך כלל במרכזי נתונים גדולים ובסביבות מחשוב ענן.