ほとんどすべてのコンピュータ プログラムには、別々のパスに分岐するコードの部分があります。 たとえば、if-then-else ステートメントには 2 つの可能な結果があります。 CPU はすべてのコマンドを順番に処理するため、これらのステートメントはシーケンシャル プロセッサには何の問題もありません。 複数の命令が一度に実行されるため、分岐はパイプライン化されたプロセッサに大きな問題をもたらします。
シナリオ
2 つの結果が考えられる分岐ステートメントを含むプログラムの場合、考えられる 2 つのコード パスを同じ場所にすることはできません。 いずれかのオプションを完了するために必要な処理は異なります。 そうしないと、プログラムは分岐しません。 if ステートメントのように、一度しか実行されない分岐ステートメントがかなりの数存在する可能性があります。
ループを形成する分岐文もあります。 これらは使い捨てステートメントほど数値的には一般的ではないかもしれませんが、一般的に統計的に繰り返されます。 分岐によってループを回避する可能性の方が高いと考えられます。
なぜこれが問題なのですか?
この問題が完全なシーケンシャル プロセッサでどのように表現されるかは問題ではありません。 それは単に問題ではありません。 どの分岐が行われるかは、次の命令の最初の部分が処理される前にわかります。
ただし、パイプライン化されたプロセッサでは、次の命令がキューに入れられます。 プロセッサがどの分岐が取られているかを知っているとき、それらはすでに処理されています。 では、プロセッサはこのシナリオをどのように処理する必要があるのでしょうか? いくつかのオプションがあります。 最悪の場合は、パイプラインを単に待ってアイドル状態のままにし、どの分岐で応答が得られるかを待ちます。 これは、分岐ステートメントがあるたびに、少なくともパイプラインのステージと同じ数のプロセッサ時間のサイクルを常に失うことを意味します。
または、パイプラインで両方のオプションを実行して、間違った選択を破棄することもできます。 これにより、何もしない場合の半分のペナルティが発生しますが、すべての分岐ステートメントでパフォーマンスが低下します。 最新の CPU は命令を順不同で実行することもできるため、すべての分岐命令をできるだけ早く実行しようとする可能性があります。 したがって、その結果は必要になる前にわかります。 このオプションは、スケーラブルではないことを除けば、役に立ちます。 比較的高密度の分岐ステートメントがあるとします。 その場合、アイドル時間なしですべてを早期に実行することはできません。
この問題は実際にどのように対処されていますか
実際には、プロセッサには分岐予測子が含まれています。 分岐予測子は、分岐選択のどの結果が採用されるかを推測しようとします。 次に、プロセッサは予測が正しいと想定し、命令をスケジュールします。 分岐予測子が正確であれば、パフォーマンスが低下することはありません。
分岐予測子が間違いを犯した場合は、パイプラインをフラッシュして、実際の結果の処理を開始する必要があります。 これにより、何もせずに結果を待つよりもパフォーマンスがわずかに低下します。 最高のパフォーマンスを得るには、分岐予測子が可能な限り正確であることを確認することが重要です。 これにはさまざまなアプローチがあります。
マッチングコード
機械語では、分岐は常に次の命令を読み取るか、別の命令セットにジャンプするかの選択です。 分岐予測子の初期の実装の中には、すべての分岐が常に行われるか、決して行われないと単純に仮定しているものがあります。 この実装は、コンパイラがこの動作を認識しており、それを実行している場合、驚くほど高い成功率を持つことができます。 最も可能性の高い結果がプロセッサの一般的な結果と一致するようにマシンコードを調整するように設計されています 予測。 これには、多くのソフトウェア開発習慣の調整と調整が必要です。
もう 1 つの方法は、統計から、一般にループが発生し、分岐が逆方向に進む場合は常にジャンプすることを学習することでした。 ジャンプが順方向の場合は決してジャンプしない。 ループ。 これらは両方とも静的分岐予測のタイプであり、分岐の結果はコンパイル時に予測されます。
動的分岐予測子
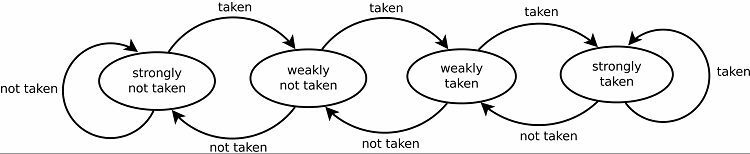
最新の分岐予測は動的であり、現在実行中のプログラムからの統計を使用して、予測の成功率を向上させます。 飽和カウンターは、すべての現在の分岐予測子の基礎です。 最初の推測は、静的またはランダムに決定されます。 分岐が行われるか行われなかった場合、その結果はメモリの一部に格納されます。 次に同じ分岐が発生すると、分岐予測子は以前と同じ結果を予測します。
これにより、当然、ループの予測率が向上します。 これには 2 つのバージョンがあります。 初期のバージョンでは、単一ビットのデータを使用して、分岐が行われたかどうかを示していました。 それ以降のバージョンでは、2 ビットを使用して、選択が弱いか強いか、または選択されていないかを示します。 このセットアップでは、プログラムがループに戻った場合にループの結果を予測することができ、一般的に成功率が高くなります。
追跡パターン
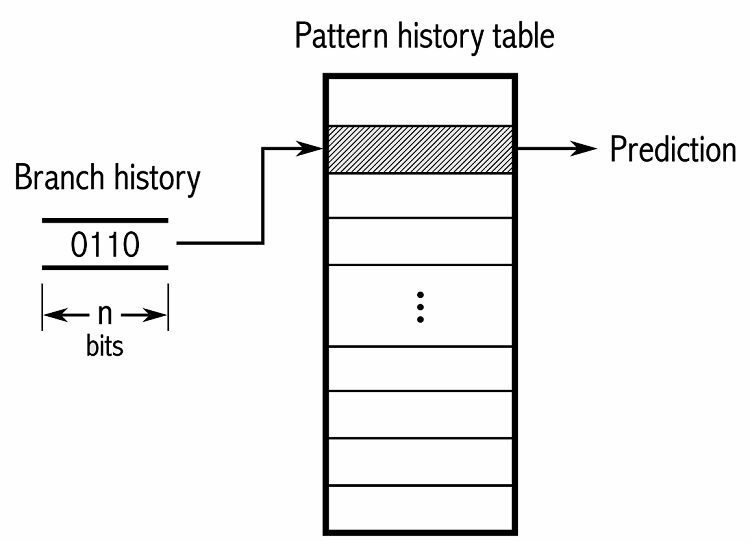
パターンを追跡するために、一部の分岐予測子は、どのような選択が行われたかの履歴を追跡します。 たとえば、ループが継続的に呼び出されているが、ループから抜け出す前に 4 回しかループしていないとします。 その場合、2 レベルの適応予測子はこのパターンを識別し、それが再び発生することを予測できます。 これにより、単純な飽和カウンターよりも成功率がさらに向上します。 最新の分岐予測器は、ニューラル ネットワークを使用してパターンを見つけて予測することで、これをさらに構築します。
一部の分岐予測子は複数のアルゴリズムを使用し、結果を比較して使用する予測を決定します。 一部のシステムは、ローカル分岐予測と呼ばれるもので、各分岐命令を個別に追跡します。 他の人は、グローバル分岐予測システムを使用して、最近のすべての分岐命令を追跡します。 どちらにも用途と欠点があります。
結論
分岐予測子は、パイプライン化された CPU の特別な部分です。 実際の命令が処理される前に、分岐命令の結果を予測しようとします。 これは、実行する必要がある命令が不明な場合でも、CPU がパイプラインを飽和状態に保つことができるため、パイプライン化された CPU のコア機能です。 それらが正しい場合、パフォーマンスが低下することはありません。 最新のアルゴリズムは、比較的予測可能なワークロードで 97% の確率で正確です。
完全な予測方法はないため、実装はさまざまです。 間違った予測を行った場合のパフォーマンスへの影響は、パイプラインの長さによって異なります。 具体的には、予測が間違っていたかどうかを判断できるようになるまでのパイプラインの長さです。 また、各パイプライン ステージにある命令の数にも依存します。 最新のハイエンド デスクトップ CPU には約 19 のパイプライン ステージがあり、各ステージで少なくとも 4 つの命令を同時に実行できます。