Vroege computers waren volledig sequentieel. Elke instructie die de processor ontving, moest volledig worden voltooid voordat de volgende kon worden gestart. De meeste instructies omvatten vijf fasen: het ophalen van instructies, het decoderen van instructies, uitvoeren, geheugentoegang en terugschrijven. Respectievelijk krijgen deze fasen de instructie die moet worden voltooid, scheiden de bewerking van de waarden die zijn: geopereerd, voer de bewerking uit, open het register waarop het resultaat zal worden geschreven en schrijf het resultaat naar de geopende register.
Elk van deze fasen moet één cyclus in beslag nemen. Als de gegevens zich niet in een register bevinden, moeten deze helaas worden aangevraagd via de CPU-cache of het systeem-RAM. Dit is een stuk langzamer en voegt tientallen of honderden klokcycli van latentie toe. Ondertussen moet al het andere wachten omdat er geen andere gegevens of instructies kunnen worden verwerkt. Dit type processorontwerp wordt subscalair genoemd omdat het minder dan één instructie per klokcyclus uitvoert.

Pipelining naar scalair
Een scalaire processor kan worden bereikt door een systeempijplijn toe te passen. Elk van de vijf fasen van een instructie die wordt uitgevoerd, wordt uitgevoerd in verschillende stukjes hardware in de eigenlijke processorkern. Dus als u voorzichtig bent met de gegevens die u voor elke fase in de hardware invoert, kunt u ze elke cyclus bezig houden. In een perfecte wereld zou dit kunnen leiden tot een 5x snellere snelheid en voor de processor om perfect scalair te zijn en een volledige instructie per cyclus uit te voeren.

In werkelijkheid zijn programma's complex en verminderen ze de doorvoer. Als u bijvoorbeeld twee optelinstructies "a = b + c" en "d = e + f" hebt, kunnen deze zonder problemen in een pijplijn worden uitgevoerd. Als je echter "a = b + c" hebt, gevolgd door "d = a + e", heb je een probleem. Ervan uitgaande dat deze twee instructies direct na elkaar zijn, is het proces om de nieuwe waarde van "a" te berekenen niet voltooid, laat staan worden teruggeschreven naar het geheugen voordat de tweede instructie de oude waarde van "a" leest en vervolgens het verkeerde antwoord geeft voor "d".
Dit gedrag kan worden tegengegaan door een coördinator op te nemen, die aanstaande instructies analyseert en ervoor zorgt dat geen enkele instructie die van een andere afhankelijk is, te dicht achter elkaar wordt uitgevoerd. Het voert het programma eigenlijk in de verkeerde volgorde uit om dit op te lossen. Dit werkt, omdat veel instructies niet per se afhankelijk zijn van het resultaat van een vorige.
De pijplijn uitbreiden naar superscalar
Een superscalaire processor kan meer dan één volledige instructie per cyclus uitvoeren. Een manier om dit te doen is door de pijplijn uit te breiden zodat er twee of meer stukjes hardware zijn die elke fase aankunnen. Op deze manier kunnen er in elke cyclus twee instructies in elke fase van de pijplijn zijn. Dit resulteert uiteraard in een grotere ontwerpcomplexiteit omdat hardware wordt gedupliceerd, maar het biedt uitstekende mogelijkheden voor het opschalen van prestaties.
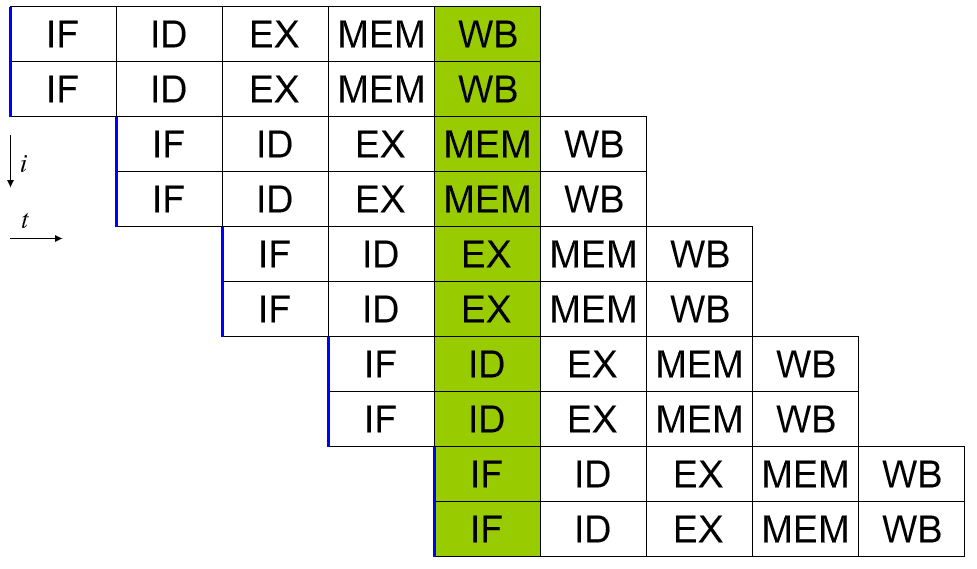
De prestatieverbetering door toenemende pijplijnen schaalt echter tot nu toe alleen efficiënt. Thermische en groottebeperkingen plaatsen enkele limieten. Er zijn ook belangrijke planningscomplicaties. Een efficiënte dispatcher is nu nog kritischer omdat hij ervoor moet zorgen dat geen van de twee sets instructies afhankelijk is van het resultaat van een van de andere instructies die worden verwerkt.
Een vertakkingsvoorspeller is een deel van de verzender dat steeds kritischer wordt naarmate een processor meer superscalair is. Sommige instructies kunnen twee mogelijke uitkomsten hebben, die elk leiden tot verschillende volgende instructies. Een eenvoudig voorbeeld zou een "als" -statement zijn. "Als dit waar is, doe dat dan, doe anders dit andere". Een vertakkingsvoorspeller probeert de uitkomst van een vertakkingsbewerking te voorspellen. Vervolgens plant het preventief de instructies en voert het uit volgens wat het denkt dat het waarschijnlijke resultaat is.
Er zit veel complexe logica in moderne vertakkingsvoorspellers, die kunnen resulteren in succespercentages van vertakkingsvoorspellingen in de orde van 98%. Een juiste voorspelling bespaart de tijd die verloren had kunnen gaan met wachten op het daadwerkelijke resultaat, een onjuiste voorspelling vereist dat de voorspelde instructies en elk van hun resultaten worden weggegooid en de echte instructies worden op hun plaats uitgevoerd, wat wordt geleverd met een lichte straf voor het hebben van net wachtte. Zo kunnen hoge voorspellingssuccespercentages de prestaties merkbaar verhogen.
Conclusie
Een computerprocessor wordt als superscalair beschouwd als deze meer dan één instructie per klokcyclus kan uitvoeren. Vroege computers waren volledig sequentieel en voerden slechts één instructie tegelijk uit. Dit betekende dat elke instructie meer dan één cyclus nodig had om te voltooien en dus waren deze processors subscalair. Een basispijplijn die het gebruik van de fasespecifieke hardware voor elke fase van een instructie mogelijk maakt, kan maximaal één instructie per klokcyclus uitvoeren, waardoor deze scalair wordt.
Opgemerkt moet worden dat geen enkele instructie volledig wordt verwerkt in een enkele klokcyclus. Het duurt nog steeds minstens vijf cycli. Er kunnen echter meerdere instructies tegelijk in de pijplijn zitten. Dit maakt een doorvoer mogelijk van één of meer voltooide instructies per cyclus.
Superscalar moet niet worden verward met hyperscaler, wat verwijst naar bedrijven die hyperscale computerresources kunnen aanbieden. Hyperscale computing omvat de mogelijkheid om hardwarebronnen, zoals rekenkracht, geheugen, netwerkbandbreedte en opslag, naadloos te schalen met de vraag. Dit is meestal te vinden in grote datacenters en cloud computing-omgevingen.