I nesten alle dataprogrammer er det deler av koden som forgrener seg i separate baner. For eksempel har en hvis-så-eller-setning to mulige utfall. Disse uttalelsene gir ikke noe problem for sekvensielle prosessorer, ettersom CPU-en behandler hver kommando i rekkefølge. Grener utgjør et stort problem for prosessorer med pipeline, ettersom flere instruksjoner blir utført på en gang.
Scenarioet
Når det gjelder et program med en forgreningssetning med to mulige utfall, kan ikke de to mulige kodebanene være på samme sted. Behandlingen som kreves for å fullføre begge alternativene vil være forskjellig. Ellers ville ikke programmet forgrene seg. Det vil sannsynligvis være et stort antall forgreningsutsagn som bare blir tatt én gang, som en if-utsagn.
Det er også forgreningsutsagn som danner en løkke. Selv om disse kanskje ikke er like numerisk vanlige som engangsutsagn, gjentas de vanligvis statistisk. Det kan antas at det er mer sannsynlig at en gren tar deg tilbake rundt en løkke enn ikke.
Hvorfor er dette et problem?
Det spiller ingen rolle hvordan dette problemet er formulert i en fullstendig sekvensiell prosessor. Det er rett og slett ikke et problem. Hvilken gren som blir tatt er kjent før første del av den følgende instruksen behandles.
I en prosessor med pipeline står imidlertid følgende instruksjoner i kø. De blir allerede behandlet når prosessoren vet hvilken gren som blir tatt. Så hvordan skal prosessoren håndtere dette scenariet? Det er noen få alternativer. Det verste er rett og slett å vente og la rørledningen stå stille mens den venter på svaret på hvilken gren den skal ta. Dette vil bety at hver gang du har en forgreningssetning, vil du alltid miste minst like mange sykluser med prosessortid som du har stadier i pipelinen.
Alternativt kan du prøve å kjøre begge alternativene i rørledningen og forkaste feil valg. Dette vil ha halve straffen for å ikke gjøre noe, men likevel pådra seg en ytelsesstraff for hver forgrening. Gitt at moderne CPUer også kan kjøre instruksjoner ute av drift, kan du potensielt forsøke å kjøre hver forgreningsinstruksjon så snart som mulig. Så resultatet er kjent før det er nødvendig. Dette alternativet kan være nyttig, bortsett fra at det ikke er skalerbart. Anta at du har en relativt høy tetthet av forgreningsutsagn. I så fall vil du rett og slett ikke kunne kjøre alle tidlig uten å ha litt ledig tid.
Hvordan er dette problemet egentlig løst
I virkeligheten inkluderer prosessoren en grenprediktor. Grenprediktoren prøver å gjette hvilket resultat av et forgreningsvalg som vil bli tatt. Prosessoren antar da at prediksjonen er korrekt og planlegger instruksjoner. Hvis grenprediktoren er nøyaktig, er det ingen ytelsesstraff.
Hvis grenprediktoren gjør en feil, må du spyle rørledningen og begynne å behandle det faktiske resultatet. Dette resulterer i en litt verre ytelsesstraff enn å ikke ha gjort noe og bare ventet på resultatet. For å få best mulig ytelse er det viktig å sikre at grenprediktoren er så nøyaktig som mulig. Det finnes en rekke ulike tilnærminger til dette.
Matchende kode
I maskinkode er en gren alltid et valg mellom å lese neste instruksjon eller hoppe til et sett med instruksjoner et annet sted. Noen tidlige implementeringer av grenprediktorer antok ganske enkelt at alle grener alltid eller aldri ville bli tatt. Denne implementeringen kan ha en overraskende god suksessrate hvis kompilatorer kjenner denne oppførselen og er det designet for å justere maskinkoden slik at det mest sannsynlige resultatet stemmer overens med prosessorens generelle antagelse. Dette krever mye tuning og justering av programvareutviklingsvaner.
Et annet alternativ var å lære av statistikken at løkker vanligvis tas og alltid hoppe hvis grenen går bakover i instruksjonsstrøm og aldri hopp hvis hoppet er forover fordi det normalt vil være den statistisk mindre sannsynlige tilstanden for å forlate en Løkke. Dette er begge typer statisk grenprediksjon, der resultatet av en gren blir predikert på kompileringstidspunktet.
Dynamiske grenprediktorer
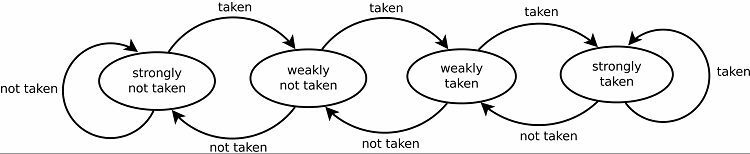
Moderne grenprediktorer er dynamiske, og bruker statistikk fra programmet som kjører for øyeblikket for å oppnå bedre prediksjonssuksessrater. En mettende teller er et grunnlag for alle gjeldende grenprediktorer. Den første gjetning avgjøres statisk eller tilfeldig. Når en gren er tatt eller ikke tatt, blir resultatet lagret i en del av minnet. Neste gang den samme grenen kommer, forutsier grenprediktoren det samme resultatet som før.
Dette resulterer naturligvis i gode prediksjonsrater for løkker. Det finnes to versjoner av dette. De tidlige versjonene brukte ganske enkelt en enkelt bit med data for å indikere om grenen ble tatt eller ikke. Senere versjoner bruker to biter for å indikere et svakt eller sterkt tatt eller ikke tatt valg. Dette oppsettet kan fortsatt forutsi resultatet av å ta en sløyfe hvis programmet går tilbake til det, og øker generelt suksessratene.
Sporingsmønstre
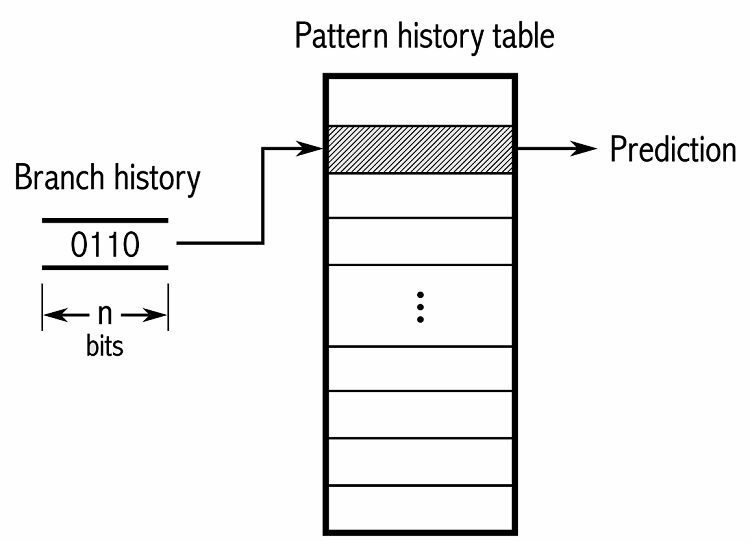
For å spore mønstre holder noen grenprediktorer oversikt over hvilke valg som ble tatt. Anta for eksempel at en løkke kalles kontinuerlig, men bare går rundt fire ganger før den bryter ut av løkken. I så fall kan en adaptiv prediktor på to nivåer identifisere dette mønsteret og forutsi at det skjer igjen. Dette øker suksessratene ytterligere over en enkel mettet teller. Moderne grenprediktorer bygger videre på dette ved å bruke et nevralt nettverk for å oppdage og forutsi mønstre.
Noen grenprediktorer bruker flere algoritmer og sammenligner deretter resultatene for å bestemme hvilken prediksjon som skal brukes. Noen systemer holder styr på hver greninstruksjon separat i det som kalles lokal grenprediksjon. Andre bruker et globalt grenprediksjonssystem for å spore alle nylige greninstruksjoner. Begge har sine bruksområder og ulemper.
Konklusjon
En grenprediktor er en spesiell del av en prosessor med pipeline. Den prøver å forutsi utfallet av en forgreningsinstruksjon før den faktiske instruksjonen behandles. Dette er en kjernefunksjon til en pipelinet CPU da den lar CPUen holde rørledningen mettet selv om den er usikker på hvilke instruksjoner som må utføres. De gir ingen reduksjon i ytelse når de er riktige. Moderne algoritmer kan være nøyaktige i relativt forutsigbare arbeidsbelastninger så mye som 97 % av tiden.
Det er ingen perfekt metode for prediksjon, så implementeringene varierer. Ytelseseffekten av å gjøre en feil prediksjon avhenger av lengden på rørledningen. Nærmere bestemt lengden på rørledningen før det kan bestemmes om prediksjonen var feil. Det avhenger også av hvor mange instruksjoner som er i hvert rørledningstrinn. Moderne avanserte stasjonære CPUer har rundt 19 pipeline-trinn og kan kjøre minst fire instruksjoner samtidig i hvert trinn.