W prawie każdym programie komputerowym istnieją części kodu, które rozgałęziają się na osobne ścieżki. Na przykład instrukcja if-the- else ma dwa możliwe wyniki. Te stwierdzenia nie stanowią problemu dla procesorów sekwencyjnych, ponieważ procesor przetwarza każde polecenie w kolejności. Gałęzie stanowią duży problem dla procesorów potokowych, ponieważ wiele instrukcji jest wykonywanych jednocześnie.
Scenariusz
W przypadku programu z instrukcją rozgałęzienia z dwoma możliwymi wynikami, dwie możliwe ścieżki kodu nie mogą znajdować się w tym samym miejscu. Przetwarzanie wymagane do wykonania obu opcji będzie inne. W przeciwnym razie program nie rozgałęziłby się. Prawdopodobnie będzie sporo instrukcji rozgałęziających, które są brane tylko raz, jak na przykład instrukcja if.
Istnieją również instrukcje rozgałęzione, które tworzą pętlę. Chociaż mogą one nie być tak częste liczbowo jak oświadczenia jednorazowego użytku, na ogół są one powtarzane statystycznie. Można założyć, że jest bardziej prawdopodobne, że gałąź zabierze Cię z powrotem w pętlę, niż nie.
Dlaczego jest to problem?
Nie ma znaczenia, jak ten problem jest sformułowany w w pełni sekwencyjnym procesorze. To po prostu nie jest problem. Która gałąź zostanie podjęta, jest znana przed przetworzeniem pierwszej części poniższej instrukcji.
Jednak w procesorze potokowym następujące instrukcje są umieszczane w kolejce. Są już przetwarzane, gdy procesor wie, która gałąź jest pobierana. Jak więc procesor powinien poradzić sobie z tym scenariuszem? Jest kilka opcji. Najgorsze jest po prostu czekanie i pozostawianie potoku w stanie bezczynności, podczas gdy czeka na odpowiedź na którą gałąź. Oznaczałoby to, że za każdym razem, gdy masz instrukcję rozgałęzienia, zawsze tracisz co najmniej tyle cykli czasu procesora, ile masz etapów w potoku.
Alternatywnie możesz spróbować uruchomić obie opcje w potoku i odrzucić zły wybór. Przyniosłoby to połowę kary za nierobienie niczego, ale nadal poniosłoby karę za wydajność w przypadku każdej instrukcji rozgałęziania. Biorąc pod uwagę, że nowoczesne procesory mogą również uruchamiać instrukcje w kolejności, możesz potencjalnie spróbować uruchomić każdą instrukcję rozgałęzienia tak szybko, jak to możliwe. Więc jego wynik jest znany, zanim będzie potrzebny. Ta opcja może być pomocna, ale nie jest skalowalna. Załóżmy, że masz stosunkowo dużą gęstość instrukcji rozgałęziających. W takim przypadku po prostu nie będziesz w stanie uruchomić ich wszystkich wcześnie bez czasu bezczynności.
Jak naprawdę rozwiązano ten problem?
W rzeczywistości procesor zawiera predyktor gałęzi. Predyktor rozgałęzień próbuje odgadnąć, który wynik wyboru rozgałęzienia zostanie przyjęty. Procesor zakłada następnie, że przewidywanie jest prawidłowe i planuje instrukcje. Jeśli predyktor rozgałęzień jest dokładny, nie ma spadku wydajności.
Jeśli predyktor rozgałęzień popełni błąd, musisz opróżnić potok i rozpocząć przetwarzanie rzeczywistego wyniku. Powoduje to nieco gorszy spadek wydajności niż nie zrobienie nic i po prostu czekanie na wynik. Aby uzyskać najlepszą wydajność, ważne jest, aby predyktor gałęzi był jak najdokładniejszy. Istnieje wiele różnych podejść do tego.
Pasujący kod
W kodzie maszynowym gałąź jest zawsze wyborem między odczytaniem następnej instrukcji lub przeskokiem do zestawu instrukcji w innym miejscu. Niektóre wczesne implementacje predyktorów rozgałęzień zakładały po prostu, że wszystkie rozgałęzienia będą zawsze lub nigdy nie zostaną wzięte. Ta implementacja może mieć zaskakująco dobry wskaźnik sukcesu, jeśli kompilatorzy znają to zachowanie i są zaprojektowany w celu dostosowania kodu maszynowego tak, aby najbardziej prawdopodobny wynik był zgodny z ogólnym procesorem założenie. Wymaga to wiele dostrojenia i dostosowania nawyków programistycznych.
Inną alternatywą było wyciągnięcie wniosków ze statystyk, że pętle są generalnie brane i zawsze przeskakują, jeśli gałąź cofa się w ciągu strumienia instrukcji i nigdy nie skacz, jeśli skok jest do przodu, ponieważ normalnie byłby to statystycznie mniej prawdopodobny stan wyjścia z a pętla. Są to oba typy przewidywania rozgałęzień statycznych, w których wynik rozgałęzienia jest przewidywany w czasie kompilacji.
Dynamiczne predyktory gałęzi
Nowoczesne predyktory gałęzi są dynamiczne i wykorzystują statystyki z aktualnie uruchomionego programu do osiągania lepszych wskaźników powodzenia predykcji. Licznik nasycenia jest podstawą wszystkich obecnych predyktorów gałęzi. Pierwsze przypuszczenie jest ustalane statycznie lub losowo. Gdy gałąź zostanie zajęta lub nie, wynik ten jest przechowywany w części pamięci. Następnym razem, gdy pojawi się ta sama gałąź, predyktor gałęzi przewiduje taki sam wynik jak poprzednio.
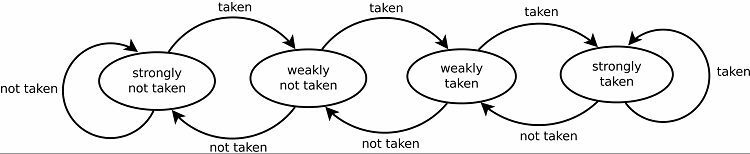
To naturalnie skutkuje dobrymi współczynnikami predykcji dla pętli. Istnieją dwie wersje tego. Wczesne wersje wykorzystywały po prostu pojedynczy bit danych, aby wskazać, czy gałąź została podjęta, czy nie. Późniejsze wersje używają dwóch bitów do wskazania słabo lub silnie podjętego lub niepodjętego wyboru. Ta konfiguracja może nadal przewidywać wynik wykonania pętli, jeśli program do niej powróci, zazwyczaj zwiększając wskaźniki powodzenia.
Wzorce śledzenia
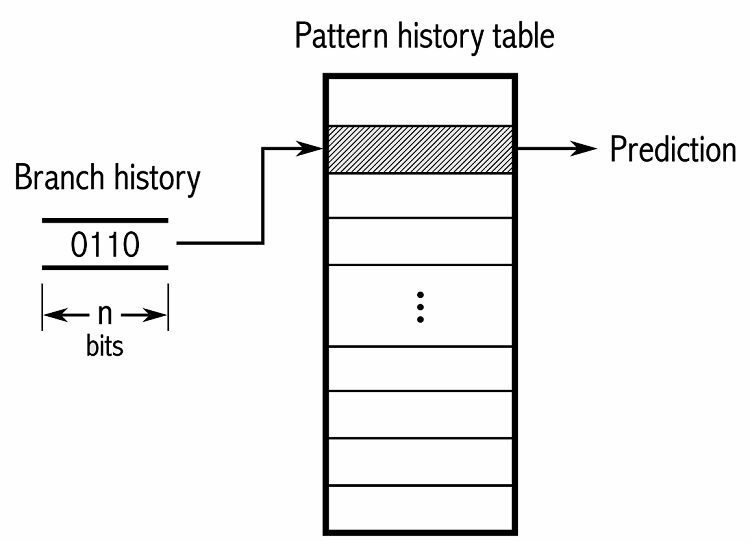
Aby śledzić wzorce, niektóre predyktory gałęzi śledzą historię dokonanych wyborów. Załóżmy na przykład, że pętla jest wywoływana w sposób ciągły, ale zapętla się tylko cztery razy przed przerwaniem pętli. W takim przypadku dwupoziomowy predyktor adaptacyjny może zidentyfikować ten wzorzec i przewidzieć, że wystąpi ponownie. To jeszcze bardziej zwiększa wskaźniki sukcesu w porównaniu z prostym nasyconym licznikiem. Nowoczesne predyktory rozgałęzień opierają się na tym dalej, wykorzystując sieć neuronową do wykrywania i przewidywania wzorców.
Niektóre predyktory rozgałęzień używają wielu algorytmów, a następnie porównują wyniki, aby zdecydować, której predykcji użyć. Niektóre systemy śledzą każdą instrukcję rozgałęzienia osobno w tak zwanym przewidywaniu rozgałęzień lokalnych. Inni używają globalnego systemu przewidywania rozgałęzień do śledzenia wszystkich ostatnich instrukcji rozgałęzień. Oba mają swoje zastosowania i wady.
Wniosek
Predyktor rozgałęzień to specjalna część procesora potokowego. Próbuje przewidzieć wynik instrukcji rozgałęziającej przed przetworzeniem rzeczywistej instrukcji. Jest to podstawowa funkcja procesora potokowego, ponieważ pozwala procesorowi utrzymać nasycenie potoku, nawet jeśli nie jest pewien, jakie instrukcje należy wykonać. Nie powodują obniżenia wydajności, gdy są poprawne. Nowoczesne algorytmy mogą być dokładne w stosunkowo przewidywalnych obciążeniach nawet w 97% przypadków.
Nie ma idealnej metody przewidywania, więc implementacje są różne. Wpływ błędnej prognozy na wydajność zależy od długości potoku. W szczególności długość potoku, zanim będzie można określić, czy prognoza była błędna. Zależy to również od tego, ile instrukcji znajduje się na każdym etapie potoku. Nowoczesne, wysokiej klasy procesory do komputerów stacjonarnych mają około 19 etapów potoku i mogą uruchamiać co najmniej cztery instrukcje jednocześnie na każdym etapie.