Wczesne komputery były całkowicie sekwencyjne. Każda otrzymana przez procesor instrukcja musiała zostać wykonana w całości, aby mogła zostać uruchomiona następna. Większość instrukcji składa się z pięciu etapów: pobieranie instrukcji, dekodowanie instrukcji, wykonywanie, dostęp do pamięci i zapisywanie zwrotne. Odpowiednio te etapy otrzymują instrukcję, którą należy wykonać, oddziel operację od wartości będących operowany, wykonaj operację, otwórz rejestr, w którym zostanie zapisany wynik, i zapisz wynik do otwartego Zarejestruj się.
Każdy z tych etapów powinien zająć jeden cykl. Niestety, jeśli dane nie znajdują się w rejestrze, należy je zażądać z pamięci podręcznej procesora lub pamięci RAM systemu. Jest to o wiele wolniejsze, dodając dziesiątki lub setki cykli zegara opóźnienia. W międzyczasie wszystko inne musi poczekać, ponieważ żadne inne dane ani instrukcje nie mogą być przetwarzane. Ten typ konstrukcji procesora jest nazywany subskalarnym, ponieważ wykonuje mniej niż jedną instrukcję na cykl zegara.

Potokowanie do skalaru
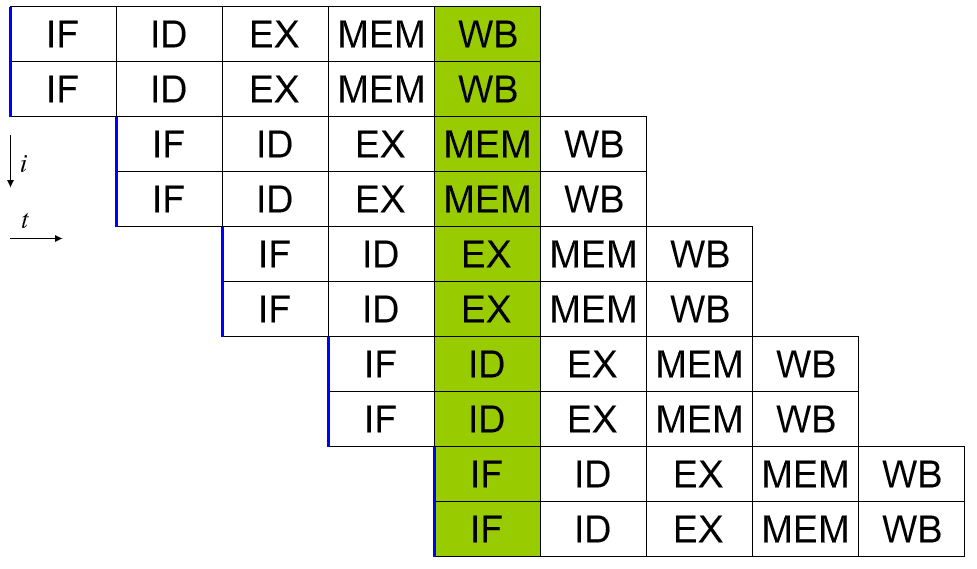
Procesor skalarny można uzyskać, stosując potok systemowy. Każdy z pięciu etapów wykonywanej instrukcji działa na różnych bitach sprzętu w rzeczywistym rdzeniu procesora. Tak więc, jeśli jesteś ostrożny z danymi, które wprowadzasz do sprzętu na każdym etapie, możesz utrzymać każdy z nich zajęty w każdym cyklu. W idealnym świecie może to prowadzić do 5-krotnego przyspieszenia i idealnie skalarnego procesora, wykonującego pełną instrukcję na cykl.

W rzeczywistości programy są złożone i zmniejszają przepustowość. Na przykład, jeśli masz dwie instrukcje dodawania „a = b + c” i „d = e + f”, można je uruchomić w potoku bez problemu. Jeśli jednak masz „a = b + c”, a następnie „d = a + e”, masz problem. Zakładając, że te dwie instrukcje znajdują się bezpośrednio po sobie, proces obliczania nowej wartości „a” nie zostanie zakończony, nie mówiąc już o zapisaniu z powrotem do pamięci, zanim druga instrukcja odczyta starą wartość „a”, a następnie poda złą odpowiedź dla "d".
Takiemu zachowaniu można przeciwdziałać poprzez włączenie dyspozytora, który analizuje nadchodzące instrukcje i zapewnia, że żadna instrukcja zależna od innej nie jest uruchamiana w zbyt bliskiej kolejności. W rzeczywistości uruchamia program w złej kolejności, aby to naprawić. To działa, ponieważ wiele instrukcji niekoniecznie opiera się na wyniku poprzedniej.
Rozszerzenie potoku do superskalarnego
Procesor superskalarny może wykonać więcej niż jedną pełną instrukcję na cykl. Jednym ze sposobów na osiągnięcie tego jest rozszerzenie potoku tak, aby istniały dwa lub więcej bitów sprzętu, które mogą obsłużyć każdy etap. W ten sposób dwie instrukcje mogą znajdować się na każdym etapie potoku w każdym cyklu. To oczywiście skutkuje zwiększoną złożonością projektu, ponieważ sprzęt jest duplikowany, jednak oferuje doskonałe możliwości skalowania wydajności.
Wzrost wydajności wynikający ze zwiększania potoków skaluje się jednak do tej pory wydajnie. Ograniczenia termiczne i wielkości nakładają pewne ograniczenia. Istnieją również poważne komplikacje w planowaniu. Wydajny dyspozytor jest teraz jeszcze bardziej krytyczny, ponieważ musi zapewnić, że żaden z dwóch zestawów instrukcji nie opiera się na wyniku przetwarzania innych instrukcji.
Predyktor gałęzi to część dyspozytora, która staje się coraz bardziej krytyczna, im bardziej superskalarny jest procesor. Niektóre instrukcje mogą mieć dwa potencjalne wyniki, z których każdy prowadzi do innych instrukcji. Prostym przykładem może być instrukcja „jeśli”. „Jeśli to prawda, zrób to, w przeciwnym razie zrób tę inną rzecz”. Predyktor rozgałęzień próbuje przewidzieć wynik operacji rozgałęzienia. Następnie zapobiegawczo planuje i wykonuje instrukcje zgodnie z tym, co uważa za prawdopodobny wynik.
W nowoczesnych predyktorach rozgałęzień jest dużo skomplikowanej logiki, która może skutkować wskaźnikami powodzenia przewidywania rozgałęzień rzędu 98%. Prawidłowa prognoza oszczędza czas, który można było zmarnować w oczekiwaniu na rzeczywisty wynik, nieprawidłowa prognoza wymaga, aby przewidywana instrukcje i wszelkie ich wyniki zostaną odrzucone, a prawdziwe instrukcje zostaną uruchomione w ich miejsce, co wiąże się z niewielką karą za posiadanie tylko czekał. W ten sposób wysokie wskaźniki sukcesu mogą znacznie zwiększyć wydajność.
Wniosek
Procesor komputerowy jest uważany za superskalarny, jeśli może wykonać więcej niż jedną instrukcję na cykl zegara. Wczesne komputery były całkowicie sekwencyjne, uruchamiały tylko jedną instrukcję na raz. Oznaczało to, że wykonanie każdej instrukcji zajmowało więcej niż jeden cykl, więc te procesory były podskalarne. Podstawowy potok, który umożliwia wykorzystanie sprzętu specyficznego dla danego etapu dla każdego etapu instrukcji, może wykonać co najwyżej jedną instrukcję na cykl zegara, co czyni go skalarnym.
Należy zauważyć, że żadna pojedyncza instrukcja nie jest w pełni przetwarzana w jednym cyklu zegara. Nadal trwa co najmniej pięć cykli. Jednak wiele instrukcji może być jednocześnie w potoku. Pozwala to na przepustowość jednej lub więcej ukończonych instrukcji na cykl.
Superskalar nie powinien być mylony z hiperskalerem, który odnosi się do firm, które mogą oferować hiperskalowe zasoby obliczeniowe. Przetwarzanie w hiperskalowaniu obejmuje możliwość bezproblemowego skalowania zasobów sprzętowych, takich jak moc obliczeniowa, pamięć, przepustowość sieci i pamięć masowa, zgodnie z zapotrzebowaniem. Zwykle występuje to w dużych centrach danych i środowiskach przetwarzania w chmurze.