Em quase todos os programas de computador, existem partes do código que se ramificam em caminhos separados. Por exemplo, uma instrução if-then-else tem dois resultados possíveis. Essas instruções não apresentam nenhum problema para processadores sequenciais, pois a CPU processa todos os comandos em ordem. As ramificações apresentam um grande problema para processadores em pipeline, pois várias instruções estão sendo executadas ao mesmo tempo.
O cenário
No caso de um programa com uma instrução de ramificação com dois resultados possíveis, os dois caminhos de código possíveis não podem estar no mesmo lugar. O processamento necessário para concluir qualquer uma das opções será diferente. Caso contrário, o programa não seria ramificado. Provavelmente haverá um número razoável de instruções de ramificação que são tomadas apenas uma vez, como uma instrução if.
Existem também instruções de ramificação que formam um loop. Embora possam não ser tão numericamente comuns quanto as declarações de uso único, geralmente são repetidas estatisticamente. Pode-se supor que é mais provável que uma ramificação o leve de volta em um loop do que não.
Por que isso é um problema?
Não importa como esse problema é formulado em um processador totalmente sequencial. Simplesmente não é um problema. Qual ramificação será tomada é conhecida antes que a primeira parte da instrução a seguir seja processada.
Em um processador em pipeline, no entanto, as instruções a seguir são enfileiradas. Eles já estão sendo processados quando o processador sabe qual ramificação está sendo tomada. Então, como o processador deve lidar com esse cenário? Existem algumas opções. O pior é simplesmente esperar e deixar o pipeline ocioso enquanto aguarda a resposta sobre qual branch tomar. Isso significaria que toda vez que você tivesse uma instrução de ramificação, sempre perderia pelo menos tantos ciclos de tempo de processador quantos estágios no pipeline.
Como alternativa, você pode tentar executar as duas opções no pipeline e descartar a escolha errada. Isso teria metade da penalidade de não fazer nada, mas ainda incorreria em uma penalidade de desempenho em cada declaração de ramificação. Dado que as CPUs modernas também podem executar instruções fora de ordem, você pode tentar executar todas as instruções de ramificação o mais rápido possível. Portanto, seu resultado é conhecido antes de ser necessário. Essa opção pode ser útil, exceto que não é escalável. Suponha que você tenha uma densidade relativamente alta de instruções de ramificação. Nesse caso, você simplesmente não poderá executar todos eles antecipadamente sem ter algum tempo ocioso.
Como esta questão é realmente abordada
Na realidade, o processador inclui um preditor de desvio. O preditor de ramificação tenta adivinhar qual resultado de uma escolha de ramificação será obtido. O processador então assume que a previsão está correta e programa as instruções. Se o preditor de ramificação for preciso, não haverá penalidade de desempenho.
Se o preditor de ramificação cometer um erro, você deverá liberar o pipeline e iniciar o processamento do resultado real. Isso resulta em uma penalidade de desempenho um pouco pior do que não ter feito nada e apenas esperado pelo resultado. Para obter o melhor desempenho, é importante garantir que o preditor de ramificação seja o mais preciso possível. Há uma variedade de abordagens diferentes para isso.
Código correspondente
Em código de máquina, uma ramificação é sempre uma escolha entre ler a próxima instrução ou pular para um conjunto de instruções em outro lugar. Algumas implementações iniciais de preditores de ramificação simplesmente presumiam que todas as ramificações sempre ou nunca seriam tomadas. Essa implementação pode ter uma taxa de sucesso surpreendentemente boa se os compiladores conhecerem esse comportamento e estiverem projetado para ajustar o código de máquina de modo que o resultado mais provável se alinhe com o padrão geral do processador. suposição. Isso requer muito ajuste e ajuste dos hábitos de desenvolvimento de software.
Outra alternativa foi aprender com a estatística que os loops geralmente são tomados e sempre saltam se o branch retroceder no fluxo de instruções e nunca salta se o salto for para frente porque normalmente seria o estado estatisticamente menos provável de deixar um ciclo. Esses são os dois tipos de previsão de ramificação estática, em que o resultado de uma ramificação é previsto em tempo de compilação.
Preditores Dinâmicos de Ramificação
Os preditores de ramificação modernos são dinâmicos, usando estatísticas do programa atualmente em execução para obter melhores taxas de sucesso de previsão. Um contador de saturação é uma base para todos os preditores de ramificação atuais. O primeiro palpite é decidido estaticamente ou aleatoriamente. Uma vez que uma ramificação foi tomada ou não, esse resultado é armazenado em uma parte da memória. Na próxima vez que a mesma ramificação aparecer, o preditor de ramificação prevê o mesmo resultado de antes.
Isso naturalmente resulta em boas taxas de previsão para loops. Existem duas versões disso. As primeiras versões simplesmente usavam um único bit de dados para indicar se a ramificação foi tomada ou não. Versões posteriores usam dois bits para indicar uma escolha fraca ou forte ou não tomada. Essa configuração ainda pode prever o resultado de fazer um loop se o programa retornar a ele, geralmente aumentando as taxas de sucesso.
Padrões de rastreamento
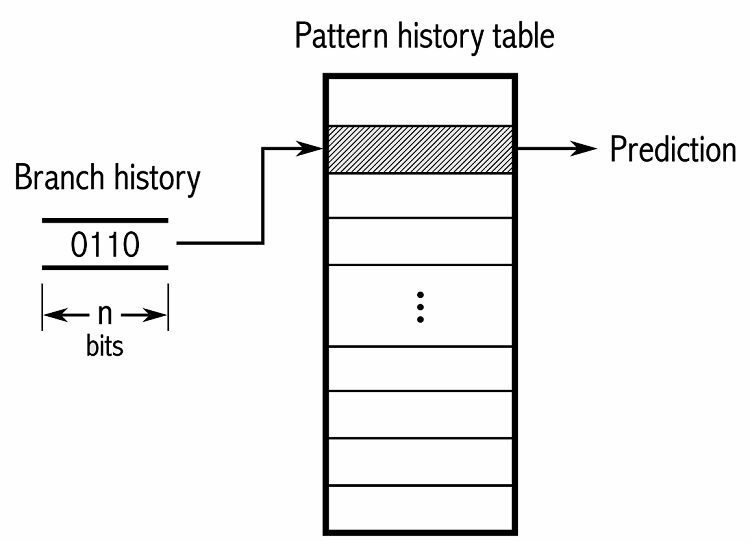
Para rastrear padrões, alguns preditores de ramificação mantêm um histórico de quais escolhas foram feitas. Por exemplo, suponha que um loop seja continuamente chamado, mas apenas dê um loop quatro vezes antes de sair do loop. Nesse caso, um preditor adaptativo de dois níveis pode identificar esse padrão e prever que ele aconteça novamente. Isso aumenta ainda mais as taxas de sucesso em um contador saturado simples. Os preditores de ramificação modernos se baseiam nisso ainda mais usando uma rede neural para identificar e prever padrões.
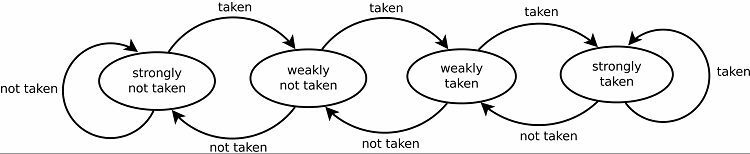
Alguns preditores de ramificação usam vários algoritmos e comparam os resultados para decidir qual previsão usar. Alguns sistemas rastreiam cada instrução de ramificação separadamente no que é chamado de previsão de ramificação local. Outros usam um sistema global de previsão de ramificação para rastrear todas as instruções de ramificação recentes. Ambos têm seus usos e desvantagens.
Conclusão
Um preditor de ramificação é uma parte especial de uma CPU em pipeline. Ele tenta prever o resultado de uma instrução de desvio antes que a instrução real seja processada. Esta é uma função central de uma CPU com pipeline, pois permite que a CPU mantenha o pipeline saturado, mesmo que não tenha certeza de quais instruções precisam ser executadas. Eles não oferecem redução no desempenho quando estão corretos. Algoritmos modernos podem ser precisos em cargas de trabalho relativamente previsíveis em até 97% do tempo.
Não existe um método perfeito de previsão, então as implementações variam. O impacto no desempenho de fazer uma previsão errada depende do comprimento do pipeline. Especificamente, o comprimento do pipeline antes dele pode ser determinado se a previsão estava errada. Também depende de quantas instruções estão em cada estágio do pipeline. As CPUs modernas de desktop de última geração têm cerca de 19 estágios de pipeline e podem executar pelo menos quatro instruções simultaneamente em cada estágio.