Os primeiros computadores eram inteiramente sequenciais. Cada instrução recebida pelo processador precisava ser completada na íntegra para que a próxima pudesse ser iniciada. Há cinco estágios para a maioria das instruções: busca de instruções, decodificação de instruções, execução, acesso à memória e writeback. Respectivamente, esses estágios recebem a instrução que precisa ser concluída, separam a operação dos valores que estão sendo operado, execute a operação, abra o registrador no qual o resultado será escrito e escreva o resultado no registro.
Cada um desses estágios deve levar um ciclo para ser concluído. Infelizmente, se os dados não estiverem em um registro, eles devem ser solicitados do cache da CPU ou da RAM do sistema. Isso é muito mais lento, adicionando dezenas ou centenas de ciclos de clock de latência. Enquanto isso, todo o resto precisa esperar, pois nenhum outro dado ou instrução pode ser processado. Esse tipo de projeto de processador é chamado de subescalar, pois executa menos de uma instrução por ciclo de clock.

Pipeline para escalar
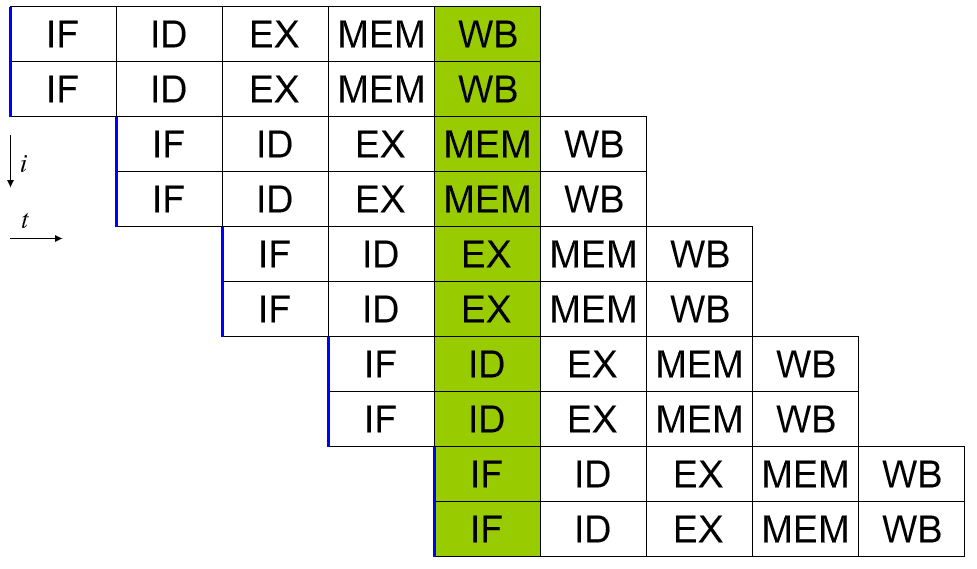
Um processador escalar pode ser obtido aplicando um pipeline de sistema. Cada um dos cinco estágios de uma instrução que está sendo executada é executado em diferentes bits de hardware no núcleo do processador real. Assim, se você for cuidadoso com os dados que alimenta o hardware para cada estágio, poderá manter cada um deles ocupado a cada ciclo. Em um mundo perfeito, isso poderia levar a uma velocidade de 5x e ao processador ser perfeitamente escalar, executando uma instrução completa por ciclo.

Na realidade, os programas são complexos e reduzem o rendimento. Por exemplo, se você tiver duas instruções de adição “a = b + c” e “d = e + f”, elas podem ser executadas em um pipeline sem problemas. Se, no entanto, você tiver “a = b + c” seguido de “d = a + e”, você tem um problema. Supondo que essas duas instruções estejam diretamente uma após a outra, o processo para calcular o novo valor de “a” não será concluído, quanto mais ser escrito de volta na memória antes que a segunda instrução leia o valor antigo de “a” e então dê a resposta errada para “d”.
Esse comportamento pode ser combatido com a inclusão de um dispatcher, que analisa as instruções futuras e garante que nenhuma instrução dependente de outra seja executada em uma sucessão muito próxima. Na verdade, ele executa o programa na ordem errada para corrigir isso. Isso funciona, porque muitas instruções não dependem necessariamente do resultado de uma anterior.
Expandindo o pipeline para superescalar
Um processador superescalar é capaz de executar mais de uma instrução completa por ciclo. Uma maneira de fazer isso é expandir o pipeline para que haja dois ou mais bits de hardware que possam lidar com cada estágio. Dessa forma, duas instruções podem estar em cada estágio do pipeline em cada ciclo. Isso obviamente resulta em maior complexidade de design, pois o hardware é duplicado, no entanto, oferece excelentes possibilidades de dimensionamento de desempenho.
O aumento de desempenho de pipelines crescentes só é dimensionado até agora com eficiência. Restrições térmicas e de tamanho impõem alguns limites. Há também complicações significativas de agendamento. Um despachante eficiente agora é ainda mais crítico, pois precisa garantir que nenhum dos dois conjuntos de instruções dependa do resultado de qualquer uma das outras instruções sendo processadas.
Um preditor de ramificação é uma parte do dispatcher que se torna cada vez mais crítica quanto mais altamente superescalar for um processador. Algumas instruções podem ter dois resultados potenciais, cada um levando a diferentes instruções a seguir. Um exemplo simples seria uma declaração “se”. “Se isso é verdade, faça isso, caso contrário, faça outra coisa”. Um preditor de ramificação tenta prever o resultado de uma operação de ramificação. Em seguida, ele agenda e executa preventivamente as instruções seguindo o que acredita ser o resultado provável.
Há muita lógica complexa em preditores de ramificação modernos, que podem resultar em taxas de sucesso de previsão de ramificação na ordem de 98%. Uma previsão correta economiza o tempo que poderia ter sido desperdiçado esperando o resultado real, uma previsão incorreta exige que o previsto instruções e quaisquer de seus resultados sejam descartados e as instruções verdadeiras sejam executadas em seu lugar, o que vem com uma pequena penalidade por ter apenas esperou. Assim, altas taxas de sucesso de previsão podem aumentar notavelmente o desempenho.
Conclusão
Um processador de computador é considerado superescalar se puder executar mais de uma instrução por ciclo de clock. Os primeiros computadores eram totalmente sequenciais, executando apenas uma instrução por vez. Isso significava que cada instrução levava mais de um ciclo para ser concluída e, portanto, esses processadores eram subescalares. Um pipeline básico que permite a utilização do hardware específico do estágio para cada estágio de uma instrução pode executar no máximo uma instrução por ciclo de clock, tornando-o escalar.
Deve-se notar que nenhuma instrução individual é totalmente processada em um único ciclo de clock. Ainda leva pelo menos cinco ciclos. Várias instruções, no entanto, podem estar no pipeline de uma só vez. Isso permite um rendimento de uma ou mais instruções concluídas por ciclo.
Superescalar não deve ser confundido com hiperescalador, que se refere a empresas que podem oferecer recursos de computação em hiperescala. A computação em hiperescala inclui a capacidade de dimensionar perfeitamente recursos de hardware, como computação, memória, largura de banda de rede e armazenamento, de acordo com a demanda. Isso geralmente é encontrado em grandes data centers e ambientes de computação em nuvem.