Existem muitas maneiras excelentes de encontrar informações na Internet. Ainda assim, existem algumas informações que são mais difíceis de encontrar, especialmente se você estiver procurando por coisas muito específicas. Os serviços de web scraping são uma ótima ferramenta para isso. Pilha de sucata é uma API que permite gerenciar seu próprio web scraping.
Um web scraper é uma ferramenta que visita um site e faz uma cópia de um tipo específico de dados. Em vez de passar por tudo manualmente, basta fornecer os dados do raspador para procurar e ele fará todo o trabalho. O Scrapestack é mais poderoso do que os raspadores de sites gratuitos que existem. Ele fornece melhor segurança, melhor confiabilidade e um servidor top de linha.
Começando
Começando com Pilha de sucata é muito fácil. Primeiro, você precisará configurar uma conta. Depois de criar uma conta, você receberá uma chave de API. Isso é o que você usará para acessar a API, sem surpresa. Você pode então usar o URL de destino para extrair dados de qualquer site que desejar.
http://api.scrapestack.com/scrape? access_key=YOUR_ACCESS_KEY&url=https://microsoft.comNo exemplo acima, você estaria copiando o site da Microsoft. Tudo que você precisa fazer é colocar sua chave API no local apropriado e alterar o domínio no final. Você receberá então o conteúdo da página sem estilos JavaScrip e CSS.
Existem outros parâmetros que você pode adicionar a esse URL de destino para refinar ainda mais as coisas.
|
[Obrigatório] Especifique sua chave de acesso de API exclusiva para autenticação com a API. Sua chave de acesso à API pode ser encontrada no painel da sua conta. |
|
[Obrigatório] Especifique o URL da página da web que você deseja copiar. |
|
[opcional] Defina como |
|
[opcional] Definir |
|
[opcional] Especifique o código de duas letras do país que você gostaria de usar como geolocalização proxy para sua solicitação de API de scraping. Os países suportados diferem por tipo de proxy, consulte o Locais de proxy seção para obter detalhes. |
|
[opcional] Definir |
Preços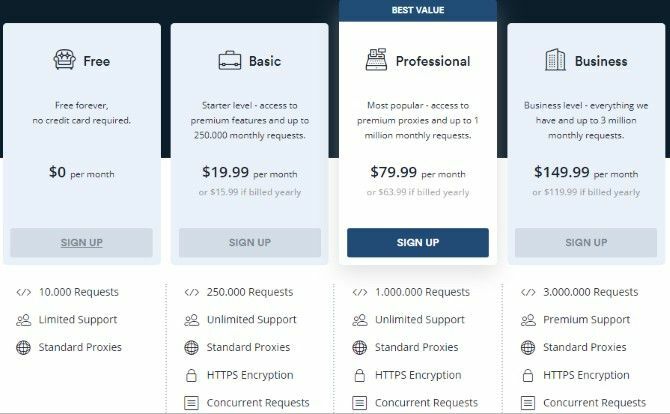
Existem vários níveis de preços para Pilha de sucata. O nível gratuito oferece 10.000 solicitações de API, proxies padrão e suporte limitado. A camada Básica adiciona 250.000 solicitações de API, criptografia HTTPS, solicitações simultâneas e suporte ilimitado. O básico custa US$ 19,99 por mês. Atingir o nível Profissional gera 1.000.000 de solicitações e, em seguida, o nível Business chega a 3.000.000 de solicitações. Eles custam US$ 79,99 e US$ 149,99 por mês, respectivamente.