În aproape orice program de calculator, există părți ale codului care se ramifică în căi separate. De exemplu, o declarație dacă-atunci-altfel are două rezultate posibile. Aceste declarații nu prezintă nicio problemă pentru procesoarele secvențiale, deoarece procesorul procesează fiecare comandă în ordine. Ramurile prezintă o mare problemă pentru procesoarele pipeline, deoarece mai multe instrucțiuni sunt executate simultan.
Scenariul
În cazul unui program cu o instrucțiune de ramificare cu două rezultate posibile, cele două căi posibile de cod nu pot fi în același loc. Procesarea necesară pentru a finaliza oricare dintre opțiuni va fi diferită. În caz contrar, programul nu s-ar ramifica. Probabil că va exista un număr destul de mare de declarații de ramificare care sunt luate o singură dată, cum ar fi o declarație if.
Există, de asemenea, declarații de ramificare care formează o buclă. Deși acestea ar putea să nu fie la fel de frecvente numeric ca declarațiile de unică folosință, ele sunt în general repetate statistic. Se poate presupune că este mai probabil ca o ramură să te ducă înapoi în jurul unei bucle decât nu.
De ce este aceasta o problemă?
Nu contează modul în care această problemă este exprimată într-un procesor complet secvenţial. Pur și simplu nu este o problemă. Ce ramură va fi luată este cunoscută înainte ca prima parte a instrucțiunii următoare să fie procesată.
Într-un procesor pipeline, totuși, următoarele instrucțiuni sunt puse în coadă. Ele sunt deja procesate când procesorul știe ce ramură este luată. Deci, cum ar trebui procesorul să gestioneze acest scenariu? Există câteva opțiuni. Cel mai rău este pur și simplu să aștepți și să lași conducta inactivă în timp ce așteaptă răspunsul pe ce ramură să ia. Acest lucru ar însemna că de fiecare dată când aveți o declarație de ramificare, veți pierde întotdeauna cel puțin atât de multe cicluri de timp de procesor câte etape aveți în conductă.
Alternativ, puteți încerca să rulați ambele opțiuni în conductă și să renunțați la alegerea greșită. Acest lucru ar avea jumătate din penalizarea de a nu face nimic, dar va suporta totuși o penalizare de performanță pentru fiecare declarație de ramificare. Având în vedere că procesoarele moderne pot, de asemenea, să ruleze instrucțiunile din funcțiune, ați putea încerca să rulați fiecare instrucțiune de ramificare cât mai curând posibil. Deci rezultatul său este cunoscut înainte de a fi necesar. Această opțiune ar putea fi utilă, cu excepția faptului că nu este scalabilă. Să presupunem că aveți o densitate relativ mare de declarații de ramificare. În acest caz, pur și simplu nu veți putea să le rulați pe toate devreme fără să aveți timp inactiv.
Cum este abordată cu adevărat această problemă
În realitate, procesorul include un predictor de ramificație. Predictorul de ramificare încearcă să ghicească ce rezultat al unei alegeri de ramificare va fi luat. Procesorul presupune apoi că predicția este corectă și programează instrucțiuni. Dacă predictorul de ramură este precis, nu există nicio penalizare de performanță.
Dacă predictorul de ramură face o greșeală, trebuie să spălați conducta și să începeți procesarea rezultatului real. Acest lucru are ca rezultat o penalizare de performanță puțin mai proastă decât să nu fi făcut nimic și să așteptați rezultatul. Pentru a obține cea mai bună performanță, este important să vă asigurați că predictorul de ramură este cât mai precis posibil. Există o serie de abordări diferite în acest sens.
Cod de potrivire
În codul de mașină, o ramură este întotdeauna o alegere între a citi următoarea instrucțiune sau a sări la un set de instrucțiuni în altă parte. Unele implementări timpurii ale predictorilor de ramuri au presupus pur și simplu că toate ramurile vor fi luate întotdeauna sau niciodată. Această implementare poate avea o rată de succes surprinzător de bună dacă compilatorii cunosc acest comportament și sunt conceput pentru a ajusta codul mașinii astfel încât rezultatul cel mai probabil să se alinieze cu generalul procesorului presupunere. Acest lucru necesită multă reglare și ajustare a obiceiurilor de dezvoltare software.
O altă alternativă a fost să înveți din statistică că buclele sunt în general luate și să sară întotdeauna dacă ramura merge înapoi în flux de instrucțiuni și nu sări niciodată dacă saltul este înainte, deoarece aceasta ar fi în mod normal starea mai puțin probabilă din punct de vedere statistic de a părăsi un buclă. Acestea sunt ambele tipuri de predicție statică a ramurilor, în care rezultatul unei ramuri este prezis în timpul compilării.
Predictori dinamici de ramuri
Predictorii moderni de ramuri sunt dinamici, folosind statisticile din programul care rulează în prezent pentru a obține rate de succes mai bune ale predicției. Un contor de saturare este o bază pentru toți predictorii de ramuri curente. Prima presupunere se decide static sau aleatoriu. Odată ce o ramură a fost luată sau nu, rezultatul este stocat într-o porțiune de memorie. Data viitoare când apare aceeași ramură, predictorul de ramură prezice același rezultat ca înainte.
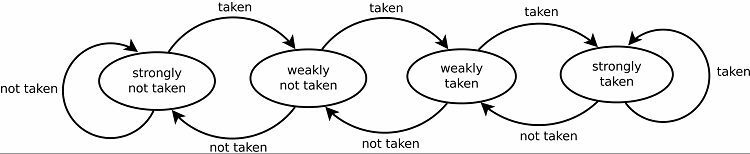
Acest lucru are ca rezultat în mod natural rate bune de predicție pentru bucle. Există două versiuni ale acestui lucru. Versiunile timpurii foloseau pur și simplu un singur bit de date pentru a indica dacă ramura a fost luată sau nu. Versiunile ulterioare folosesc doi biți pentru a indica o alegere slab sau puternic luată sau nu. Această configurare poate anticipa în continuare rezultatul unei bucle dacă programul revine la ea, crescând în general ratele de succes.
Modele de urmărire
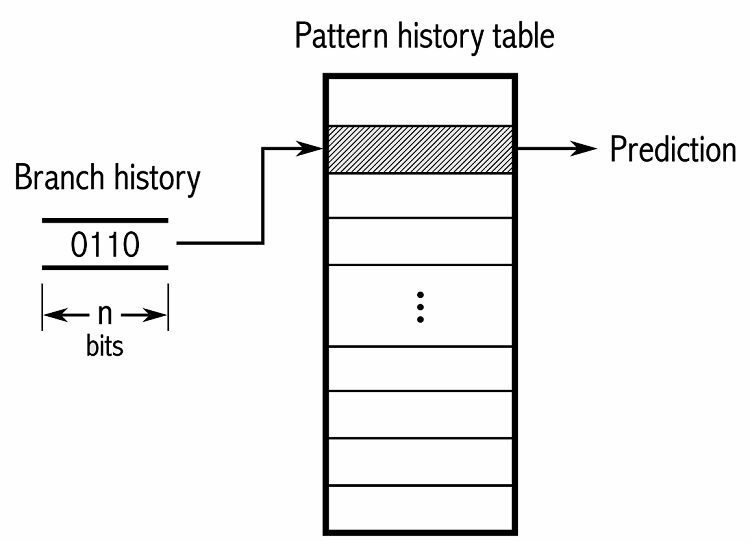
Pentru a urmări modelele, unii predictori de ramuri țin evidența unui istoric al alegerilor luate. De exemplu, să presupunem că o buclă este apelată în mod continuu, dar numai bucle de aproximativ patru ori înainte de a ieși din buclă. În acest caz, un predictor adaptiv pe două niveluri poate identifica acest model și poate prezice să se întâmple din nou. Acest lucru crește și mai mult ratele de succes față de un simplu contor saturat. Predictorii moderni de ramuri se bazează pe aceasta în continuare folosind o rețea neuronală pentru a identifica și prezice modele.
Unii predictori de ramuri folosesc mai mulți algoritmi și apoi compară rezultatele pentru a decide ce predicție să folosească. Unele sisteme țin evidența fiecărei instrucțiuni de ramificare separat în ceea ce se numește predicție locală de ramificare. Alții folosesc un sistem global de predicție a ramurilor pentru a urmări toate instrucțiunile recente de ramificare. Ambele au utilizările și dezavantajele lor.
Concluzie
Un predictor de ramură este o parte specială a unui CPU pipeline. Încearcă să prezică rezultatul unei instrucțiuni de ramificare înainte ca instrucțiunea reală să fie procesată. Aceasta este o funcție de bază a unui CPU pipeline, deoarece permite procesorului să mențină pipeline saturată chiar dacă nu este sigur ce instrucțiuni trebuie executate. Nu oferă nicio reducere a performanței atunci când sunt corecte. Algoritmii moderni pot fi acurați în sarcini de lucru relativ previzibile până la 97% din timp.
Nu există o metodă perfectă de predicție, așa că implementările variază. Impactul asupra performanței de a face o predicție greșită depinde de lungimea conductei. Mai exact, lungimea conductei înainte de a putea fi determinată dacă predicția a fost greșită. De asemenea, depinde de câte instrucțiuni sunt în fiecare etapă a conductei. Procesoarele desktop moderne de ultimă generație au aproximativ 19 etape pipeline și pot rula cel puțin patru instrucțiuni simultan în fiecare etapă.