Există o mulțime de modalități excelente de a găsi informații pe internet. Totuși, există unele informații care sunt mai greu de găsit, mai ales dacă cauți lucruri foarte specifice. Serviciile de web scraping sunt un instrument excelent pentru aceasta. Scrapestack este un API care vă permite să vă gestionați propriul web scraping.
Un web scraper este un instrument care va vizita un site web și va prelua o copie a unui anumit tip de date. Mai degrabă decât să parcurgeți totul manual, doar dați datele scraper de căutat și va face toată treaba. Scrapestack este mai puternic decât scraper-urile gratuite de site-uri de acolo. Oferă o securitate mai bună, o fiabilitate mai bună și un server de vârf.
Noțiuni de bază
Începeți cu Scrapestack Este foarte ușor. Mai întâi, va trebui să configurați un cont. Odată ce aveți un cont, vi se va oferi o cheie API. Acesta este ceea ce veți folosi pentru a accesa API-ul, fără a fi surprinzător. Puteți utiliza apoi adresa URL țintă pentru a răzui datele de pe orice site web dorit.
http://api.scrapestack.com/scrape? access_key=YOUR_ACCESS_KEY&url=https://microsoft.comÎn exemplul de mai sus, ați răzui site-ul Microsoft. Tot ce trebuie să faceți este să plasați cheia API în locul potrivit și să schimbați domeniul la sfârșit. Apoi vi se va oferi conținutul paginii fără stiluri JavaScrip și CSS.
Există și alți parametri pe care îi puteți adăuga la acea adresă URL țintă pentru a rafina și mai mult lucrurile.
|
[Necesar] Specificați cheia dvs. unică de acces API pentru a vă autentifica cu API. Cheia dvs. de acces API poate fi găsită în tabloul de bord al contului. |
|
[Necesar] Specificați adresa URL a paginii web pe care doriți să o curățați. |
|
[opțional] Setați la |
|
[opțional] Setați |
|
[opțional] Specificați codul din 2 litere al țării pe care doriți să ni-l primiți ca geolocație proxy pentru solicitarea dvs. de scraping API. Țările acceptate diferă în funcție de tipul de proxy, vă rugăm să consultați Locații proxy secțiune pentru detalii. |
|
[opțional] Setați |
Prețuri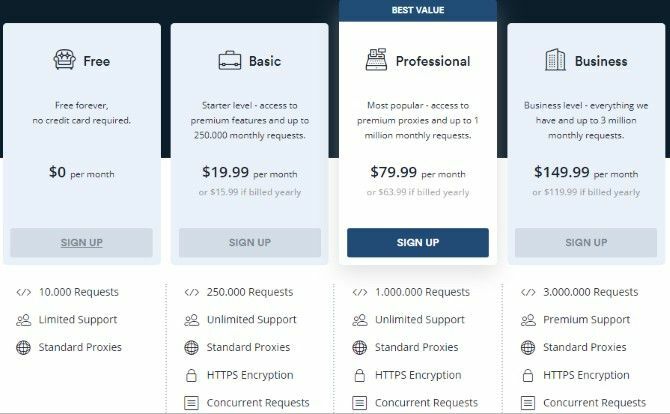
Există mai multe niveluri de preț pentru Scrapestack. Nivelul gratuit oferă 10.000 de solicitări API, proxy standard și suport limitat. Nivelul de bază adaugă 250.000 de solicitări API, criptare HTTPS, solicitări simultane și suport nelimitat. De bază costă 19,99 USD pe lună. Trecerea la nivelul Professional vă aduce 1.000.000 de solicitări, iar apoi nivelul Business ajunge până la 3.000.000 de solicitări. Acestea costă 79,99 USD și, respectiv, 149,99 USD pe lună.