I nästan alla datorprogram finns det delar av koden som förgrenar sig i separata vägar. Till exempel har ett om-då-annat-påstående två möjliga utfall. Dessa uttalanden utgör inga problem för sekventiella processorer, eftersom CPU: n bearbetar varje kommando i ordning. Grenar utgör ett stort problem för pipelined processorer, eftersom flera instruktioner exekveras samtidigt.
Scenariot
I fallet med ett program med en förgreningssats med två möjliga utfall, kan de två möjliga kodvägarna inte vara på samma plats. Bearbetningen som krävs för att slutföra båda alternativen kommer att vara annorlunda. Annars skulle programmet inte förgrenas. Det kommer sannolikt att finnas ett ganska stort antal förgreningspåståenden som bara tas en gång, som ett if-uttalande.
Det finns också förgreningssatser som bildar en loop. Även om dessa kanske inte är lika numeriskt vanliga som engångspåståenden, upprepas de i allmänhet statistiskt. Det kan antas att det är mer troligt att en gren tar dig tillbaka runt en slinga än inte.
Varför är detta ett problem?
Det spelar ingen roll hur detta problem formuleras i en helt sekventiell processor. Det är helt enkelt inget problem. Vilken gren som kommer att tas är känt innan den första delen av följande instruktion bearbetas.
I en pipelined processor står dock följande instruktioner i kö. De bearbetas redan när processorn vet vilken gren som tas. Så hur ska processorn hantera detta scenario? Det finns några alternativ. Det värsta är helt enkelt att vänta och lämna rörledningen stillastående medan den väntar på svaret på vilken gren den ska ta. Detta skulle innebära att varje gång du har ett förgreningsuttalande, skulle du alltid förlora minst lika många cykler av processortid som du har stadier i pipelinen.
Alternativt kan du prova att köra båda alternativen i pipelinen och ignorera fel val. Detta skulle ha halva straffvärdet av att inte göra någonting men ändå medföra ett prestationsstraff för varje förgrenande uttalande. Med tanke på att moderna CPU: er också kan köra instruktioner ur funktion, kan du eventuellt försöka köra varje förgreningsinstruktion så snart som möjligt. Så resultatet är känt innan det behövs. Det här alternativet kan vara användbart, förutom att det inte är skalbart. Anta att du har en relativt hög täthet av förgreningssatser. I så fall kommer du helt enkelt inte att kunna köra alla tidigt utan att ha lite ledig tid.
Hur åtgärdas detta problem verkligen
I verkligheten inkluderar processorn en grenprediktor. Grenprediktorn försöker gissa vilket resultat av ett förgreningsval som kommer att tas. Processorn antar sedan att förutsägelsen är korrekt och schemalägger instruktioner. Om förgreningsprediktorn är korrekt finns det ingen prestationsstraff.
Om förgreningsprediktorn gör ett misstag måste du spola pipelinen och börja bearbeta det faktiska resultatet. Detta resulterar i ett något värre prestationsstraff än att inte ha gjort något och bara väntat på resultatet. För att få bästa prestanda är det viktigt att se till att grenprediktorn är så exakt som möjligt. Det finns en rad olika tillvägagångssätt för detta.
Matchande kod
I maskinkod är en gren alltid ett val mellan att läsa nästa instruktion eller att hoppa till en uppsättning instruktioner någon annanstans. Vissa tidiga implementeringar av grenprediktorer antog helt enkelt att alla grenar alltid eller aldrig skulle tas. Denna implementering kan ha en förvånansvärt god framgångsfrekvens om kompilatorer känner till detta beteende och är det utformad för att justera maskinkoden så att det mest sannolika resultatet överensstämmer med processorns allmänna antagande. Detta kräver mycket justering och justering av mjukvaruutvecklingsvanor.
Ett annat alternativ var att lära sig av statistiken att loopar i allmänhet tas och alltid hoppa om grenen går bakåt i instruktionsström och hoppa aldrig om hoppet är framåt eftersom det normalt skulle vara det statistiskt mindre sannolika tillståndet att lämna en slinga. Dessa är båda typerna av statisk grenprediktion, där resultatet av en gren förutsägs vid kompileringstidpunkten.
Dynamiska grenprediktorer
Moderna grenprediktorer är dynamiska och använder statistik från det program som för närvarande körs för att uppnå bättre framgångsfrekvenser för förutsägelser. En mättande räknare är en bas för alla aktuella grenprediktorer. Den första gissningen avgörs statiskt eller slumpmässigt. När en gren har tagits eller inte tagits, lagras resultatet i en del av minnet. Nästa gång samma gren kommer, förutspår grenprediktorn samma resultat som tidigare.
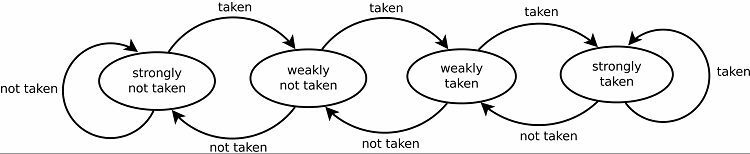
Detta resulterar naturligtvis i goda prediktionshastigheter för loopar. Det finns två versioner av detta. De tidiga versionerna använde helt enkelt en enda bit data för att indikera om grenen togs eller inte. Senare versioner använder två bitar för att indikera ett svagt eller starkt valt eller ej valt val. Denna inställning kan fortfarande förutsäga resultatet av att ta en loop om programmet återvänder till det, vilket generellt ökar framgångsfrekvensen.
Spårningsmönster
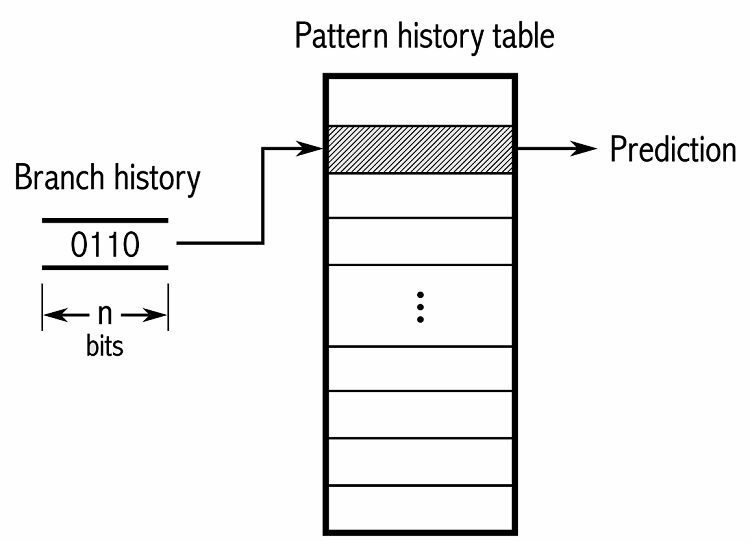
För att spåra mönster håller vissa grenprediktorer reda på en historik över vilka val som gjordes. Anta till exempel att en loop anropas kontinuerligt men bara loopar runt fyra gånger innan den bryts ut ur loopen. I så fall kan en adaptiv prediktor på två nivåer identifiera detta mönster och förutsäga att det händer igen. Detta ökar framgångsfrekvensen ytterligare över en enkel mättad räknare. Moderna grenprediktorer bygger vidare på detta genom att använda ett neuralt nätverk för att upptäcka och förutsäga mönster.
Vissa grenprediktorer använder flera algoritmer och jämför sedan resultaten för att avgöra vilken förutsägelse som ska användas. Vissa system håller reda på varje förgreningsinstruktion separat i vad som kallas lokal förgreningsprediktion. Andra använder ett globalt förgreningssystem för att spåra alla senaste förgreningsinstruktioner. Båda har sina användningsområden och nackdelar.
Slutsats
En grenprediktor är en speciell del av en pipelined CPU. Den försöker förutsäga resultatet av en greninstruktion innan den faktiska instruktionen bearbetas. Detta är en kärnfunktion för en pipelined CPU eftersom den tillåter CPU: n att hålla pipelinen mättad även om den är osäker på vilka instruktioner som behöver utföras. De ger ingen minskning av prestanda när de är korrekta. Moderna algoritmer kan vara exakta i relativt förutsägbara arbetsbelastningar så mycket som 97 % av tiden.
Det finns ingen perfekt metod för förutsägelse, så implementeringar varierar. Effekten av att göra en felaktig förutsägelse beror på längden på pipelinen. Specifikt kan rörledningens längd innan det avgöras om förutsägelsen var fel. Det beror också på hur många instruktioner som finns i varje steg i pipeline. Moderna avancerade stationära processorer har cirka 19 pipeline-steg och kan köra minst fyra instruktioner samtidigt i varje steg.