Tidiga datorer var helt sekventiella. Varje instruktion som processorn fick behövde slutföras i sin ordning innan nästa kunde startas. Det finns fem steg för de flesta instruktioner: Instruktionshämtning, Instruktionsavkodning, Execute, Minnesåtkomst och Writeback. Respektive dessa steg får instruktionen som måste slutföras, separera operationen från värdena opererade, utför operationen, öppna registret som resultatet kommer att skrivas på och skriv resultatet till den öppnade Registrera.
Var och en av dessa steg bör ta en cykel att slutföra. Tyvärr, om data inte finns i ett register, måste de begäras från CPU-cachen eller systemets RAM. Detta är mycket långsammare och lägger till dussintals eller hundratals klockcykler av latens. Under tiden måste allt annat vänta eftersom inga andra uppgifter eller instruktioner kan behandlas. Denna typ av processordesign kallas subskalär eftersom den kör mindre än en instruktion per klockcykel.

Pipelining till skalär
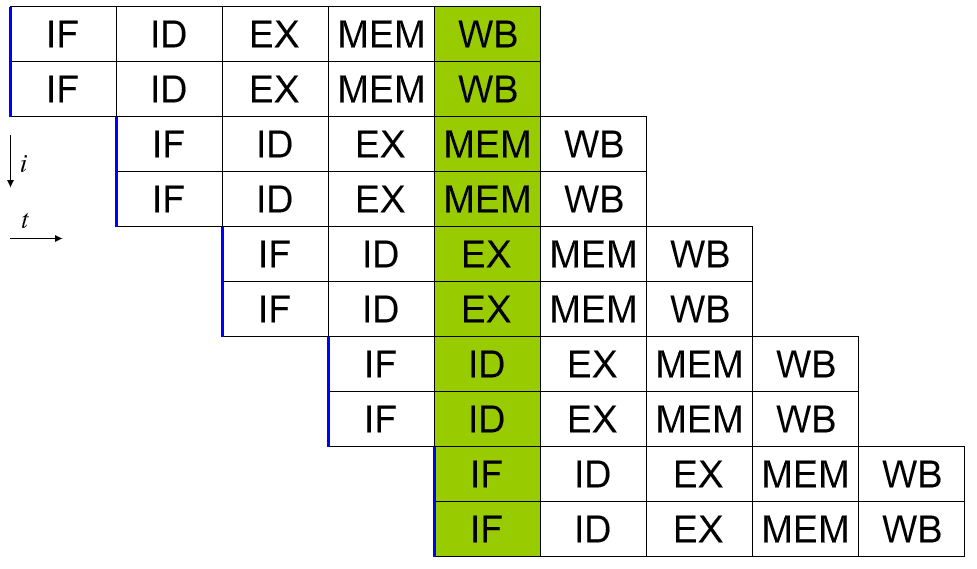
En skalär processor kan uppnås genom att tillämpa en systempipeline. Vart och ett av de fem stegen i en instruktion som exekveras körs i olika bitar av hårdvara i själva processorkärnan. Således, om du är försiktig med den data du matar in i hårdvaran för varje steg, kan du hålla var och en av dem sysselsatta varje cykel. I en perfekt värld kan detta leda till en 5x snabbare hastighet och att processorn blir perfekt skalär och kör en fullständig instruktion per cykel.

I verkligheten är program komplexa och minskar genomströmningen. Till exempel, om du har två tilläggsinstruktioner "a = b + c" och "d = e + f" kan dessa köras i en pipeline utan problem. Om du däremot har "a = b + c" följt av "d = a + e" har du ett problem. Förutsatt att dessa två instruktioner ligger direkt efter varandra, kommer processen för att beräkna det nya värdet på "a" inte att ha slutförts, än mindre skrivas tillbaka till minnet innan den andra instruktionen läser det gamla värdet på "a" och sedan ger fel svar för "d".
Detta beteende kan motverkas genom att inkludera en avsändare, som analyserar kommande instruktioner och säkerställer att ingen instruktion som är beroende av en annan körs i för nära följd. Det kör faktiskt programmet i fel ordning för att fixa detta. Detta fungerar, eftersom många instruktioner inte nödvändigtvis förlitar sig på resultatet av en tidigare.
Expandera pipeline till superskalär
En superskalär processor kan köra mer än en fullständig instruktion per cykel. Ett sätt att göra detta är att utöka pipelinen så att det finns två eller flera bitar av hårdvara som kan hantera varje steg. På så sätt kan två instruktioner finnas i varje steg i pipelinen i varje cykel. Detta resulterar uppenbarligen i ökad designkomplexitet eftersom hårdvaran dupliceras, men den erbjuder utmärkta möjligheter till skalning av prestanda.
Prestandaökningen från ökande pipelines skalar dock bara så långt effektivt. Termiska begränsningar och storleksbegränsningar sätter vissa begränsningar. Det finns också betydande schemaläggningskomplikationer. En effektiv avsändare är nu ännu mer kritisk eftersom den måste se till att ingen av två uppsättningar instruktioner förlitar sig på resultatet av någon av de andra instruktionerna som bearbetas.
En grenprediktor är en del av avsändaren som blir mer och mer kritisk ju mer superskalär en processor är. Vissa instruktioner kan ha två potentiella utfall, var och en leder till olika följande instruktioner. Ett enkelt exempel skulle vara ett "om"-påstående. "Om detta är sant, gör det, annars gör det här." En förgreningsprediktor försöker förutsäga resultatet av en förgreningsoperation. Den schemalägger och utför sedan instruktionerna i förebyggande syfte enligt vad den tror är det troliga resultatet.
Det finns mycket komplex logik i moderna grenprediktorer, som kan resultera i framgångsfrekvenser för grenförutsägelser i storleksordningen 98%. En korrekt förutsägelse sparar den tid som kunde ha gått till spillo på att vänta på det faktiska resultatet, en felaktig förutsägelse kräver att den förutspådda instruktioner och alla deras resultat kasseras och de verkliga instruktionerna körs i deras ställe, vilket kommer med ett litet straff över att bara ha väntade. Således kan höga framgångsfrekvenser för förutsägelser öka prestandan märkbart.
Slutsats
En datorprocessor anses vara superskalär om den kan utföra mer än en instruktion per klockcykel. Tidiga datorer var helt sekventiella och körde bara en instruktion åt gången. Detta innebar att varje instruktion tog mer än en cykel att göra och därför var dessa processorer subskalära. En grundläggande pipeline som möjliggör användning av den stegspecifika hårdvaran för varje steg i en instruktion kan exekvera högst en instruktion per klockcykel, vilket gör den skalär.
Det bör noteras att ingen individuell instruktion bearbetas fullständigt i en enda klockcykel. Det tar fortfarande minst fem cykler. Flera instruktioner kan dock vara i pipelinen samtidigt. Detta tillåter en genomströmning av en eller flera färdiga instruktioner per cykel.
Superscalar ska inte förväxlas med hyperscaler som syftar på företag som kan erbjuda hyperscaledatorresurser. Hyperscale computing inkluderar möjligheten att sömlöst skala hårdvaruresurser, såsom beräkning, minne, nätverksbandbredd och lagring, med efterfrågan. Detta finns vanligtvis i stora datacenter och molnmiljöer.