Tidlige computere var helt sekventielle. Hver instruktion, som processoren modtog, skulle fuldføres i sin fulde rækkefølge, før den næste kunne startes. Der er fem trin til de fleste instruktioner: Hentning af instruktioner, afkodning af instruktioner, Udfør, hukommelsesadgang og tilbageskrivning. Henholdsvis disse stadier får den instruktion, der skal afsluttes, adskiller operationen fra værdierne opereret, udfør operationen, åbn registret, som resultatet vil blive skrevet på, og skriv resultatet til det åbnede Tilmeld.
Hver af disse stadier bør tage en cyklus at fuldføre. Desværre, hvis dataene ikke er i et register, skal de anmodes om fra CPU-cachen eller systemets RAM. Dette er meget langsommere og tilføjer snesevis eller hundredvis af clock-cyklusser med latens. I mellemtiden skal alt andet vente, da ingen andre data eller instruktioner kan behandles. Denne type processordesign kaldes subscalar, da den kører mindre end én instruktion pr. clock-cyklus.

Rørledning til skalar
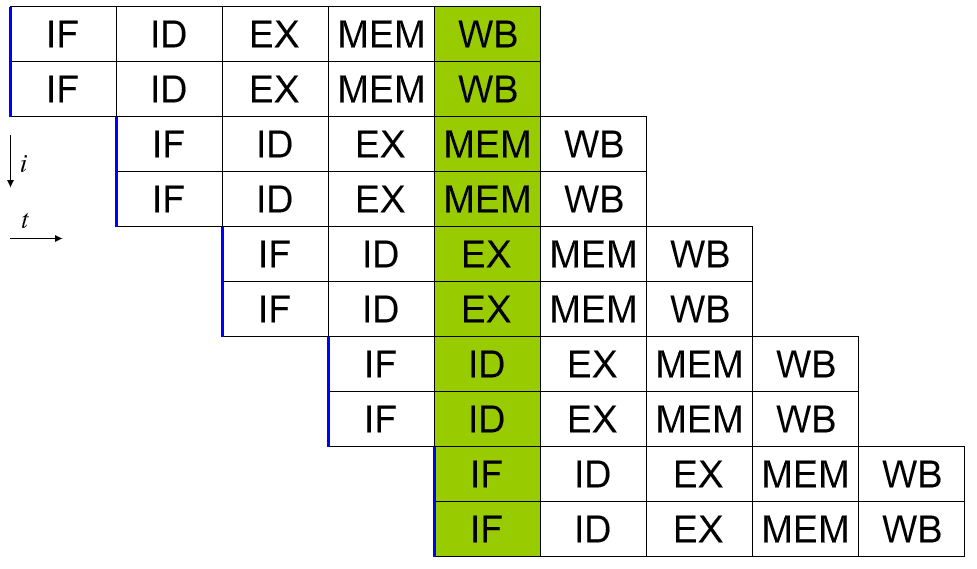
En skalær processor kan opnås ved at anvende en systempipeline. Hvert af de fem stadier af en instruktion, der udføres, kører i forskellige bits af hardware i den faktiske processorkerne. Så hvis du er forsigtig med de data, du indlæser i hardwaren for hvert trin, kan du holde hver af dem beskæftiget hver cyklus. I en perfekt verden kan dette føre til en 5x hastighed, og at processoren bliver perfekt skalar, idet den kører en fuld instruktion pr. cyklus.

I virkeligheden er programmer komplekse og reducerer gennemløbet. For eksempel, hvis du har to tilføjelsesinstruktioner "a = b + c" og "d = e + f", kan disse køres i en pipeline uden problemer. Hvis du derimod har "a = b + c" efterfulgt af "d = a + e", har du et problem. Forudsat at disse to instruktioner er direkte efter hinanden, vil processen til at beregne den nye værdi af "a" ikke være fuldført, endsige skrives tilbage til hukommelsen, før den anden instruktion læser den gamle værdi af "a" og derefter giver det forkerte svar for "d".
Denne adfærd kan imødegås med inddragelsen af en dispatcher, der analyserer kommende instruktioner og sikrer, at ingen instruktion, der er afhængig af en anden, køres i for tæt rækkefølge. Det kører faktisk programmet i den forkerte rækkefølge for at rette dette. Dette virker, fordi mange instruktioner ikke nødvendigvis er afhængige af resultatet af en tidligere.
Udvidelse af pipeline til superskalar
En superskalar processor er i stand til at køre mere end én fuld instruktion pr. cyklus. En måde at gøre dette på er ved at udvide pipelinen, så der er to eller flere stykker hardware, der kan håndtere hvert trin. På denne måde kan der være to instruktioner i hvert trin i rørledningen i hver cyklus. Dette resulterer naturligvis i øget designkompleksitet, da hardware duplikeres, men det giver fremragende ydeevneskaleringsmuligheder.
Ydeevneforøgelsen fra stigende pipelines skalerer dog kun effektivt indtil videre. Termiske og størrelsesmæssige begrænsninger sætter nogle begrænsninger. Der er også betydelige planlægningskomplikationer. En effektiv dispatcher er nu endnu mere kritisk, da den skal sikre, at ingen af de to sæt instruktioner er afhængige af resultatet af nogen af de andre instruktioner, der behandles.
En grenprædiktor er en del af dispatcheren, der bliver mere og mere kritisk, jo mere superskalær en processor er. Nogle instruktioner kan have to potentielle udfald, som hver fører til forskellige følgende instruktioner. Et simpelt eksempel ville være en "hvis"-erklæring. "Hvis dette er sandt, gør det, ellers gør dette andet". En forgreningsprædiktor forsøger at forudsige resultatet af en forgreningsoperation. Den planlægger og udfører derefter instruktionerne på forhånd efter, hvad den mener er det sandsynlige resultat.
Der er en masse kompleks logik i moderne grenprædiktorer, som kan resultere i grenforudsigelsessuccesrater i størrelsesordenen 98%. En korrekt forudsigelse sparer den tid, der kunne have været spildt på at vente på det faktiske resultat, en forkert forudsigelse nødvendiggør, at den forudsagte instruktioner og alle deres resultater kasseres, og de sande instruktioner køres i deres sted, hvilket kommer med en lille straf over at have bare ventede. Således kan succesrater med høje forudsigelser øge ydeevnen mærkbart.
Konklusion
En computerprocessor betragtes som superskalær, hvis den kan udføre mere end én instruktion pr. clock-cyklus. Tidlige computere var helt sekventielle og kørte kun én instruktion ad gangen. Dette betød, at hver instruktion tog mere end én cyklus at fuldføre, og derfor var disse processorer subskalære. En grundlæggende pipeline, der muliggør brugen af den trinspecifikke hardware for hvert trin af en instruktion, kan højst udføre én instruktion pr. clock-cyklus, hvilket gør den skalær.
Det skal bemærkes, at ingen individuel instruktion behandles fuldt ud i en enkelt clock-cyklus. Det tager stadig mindst fem cyklusser. Flere instruktioner kan dog være i pipelinen på én gang. Dette tillader en gennemstrømning af en eller flere fuldførte instruktioner pr. cyklus.
Superscalar må ikke forveksles med hyperscaler, der refererer til virksomheder, der kan tilbyde hyperscale computing ressourcer. Hyperscale computing inkluderer muligheden for problemfrit at skalere hardwareressourcer, såsom computer, hukommelse, netværksbåndbredde og lagring, med efterspørgsel. Dette findes typisk i store datacentre og cloud computing-miljøer.