En casi cualquier programa de computadora, hay partes del código que se bifurcan en caminos separados. Por ejemplo, una declaración if-then-else tiene dos resultados posibles. Estas declaraciones no presentan ningún problema para los procesadores secuenciales, ya que la CPU procesa cada comando en orden. Las ramas presentan un gran problema para los procesadores segmentados, ya que se ejecutan varias instrucciones a la vez.
El escenario
En el caso de un programa con una declaración de bifurcación con dos resultados posibles, las dos rutas de código posibles no pueden estar en el mismo lugar. El procesamiento requerido para completar cualquiera de las opciones será diferente. De lo contrario, el programa no se bifurcaría. Es probable que haya una buena cantidad de declaraciones de bifurcación que solo se toman una vez, como una declaración if.
También hay declaraciones de bifurcación que forman un bucle. Si bien estos pueden no ser tan comunes numéricamente como las declaraciones de un solo uso, generalmente se repiten estadísticamente. Se puede suponer que es más probable que una rama lo lleve de regreso a un bucle que no.
¿Por qué es esto un problema?
No importa cómo se plantee este problema en un procesador completamente secuencial. Simplemente no es un problema. Se sabe qué bifurcación se tomará antes de que se procese la primera parte de la siguiente instrucción.
Sin embargo, en un procesador segmentado, las siguientes instrucciones están en cola. Ya se están procesando cuando el procesador sabe qué rama se está tomando. Entonces, ¿cómo debería manejar el procesador este escenario? Hay algunas opciones. Lo peor es simplemente esperar y dejar la tubería inactiva mientras espera la respuesta sobre qué rama tomar. Esto significaría que cada vez que tenga una declaración de bifurcación, siempre perderá al menos tantos ciclos de tiempo de procesador como etapas tenga en la canalización.
Alternativamente, podría intentar ejecutar ambas opciones en la canalización y descartar la opción incorrecta. Esto tendría la mitad de la penalización de no hacer nada, pero aún incurriría en una penalización de rendimiento en cada declaración de bifurcación. Dado que las CPU modernas también pueden ejecutar instrucciones desordenadas, podría intentar ejecutar todas las instrucciones de bifurcación lo antes posible. Por lo tanto, su resultado se conoce antes de que se necesite. Esta opción podría ser útil, excepto que no es escalable. Suponga que tiene una densidad relativamente alta de declaraciones de ramificación. En ese caso, simplemente no podrá ejecutarlos todos antes sin tener tiempo de inactividad.
¿Cómo se aborda realmente este problema?
En realidad, el procesador incluye un predictor de rama. El predictor de bifurcación intenta adivinar qué resultado de una elección de bifurcación se tomará. Luego, el procesador asume que la predicción es correcta y programa las instrucciones. Si el predictor de bifurcación es preciso, no hay penalización de rendimiento.
Si el predictor de bifurcación comete un error, debe vaciar la canalización y comenzar a procesar el resultado real. Esto da como resultado una penalización de rendimiento ligeramente peor que no haber hecho nada y solo esperar el resultado. Para obtener el mejor rendimiento, es importante asegurarse de que el predictor de bifurcación sea lo más preciso posible. Hay una variedad de enfoques diferentes para esto.
Código coincidente
En el código de máquina, una bifurcación es siempre una elección entre leer la siguiente instrucción o saltar a un conjunto de instrucciones en otro lugar. Algunas implementaciones tempranas de predictores de bifurcación simplemente asumieron que todas las bifurcaciones siempre o nunca serían tomadas. Esta implementación puede tener una tasa de éxito sorprendentemente buena si los compiladores conocen este comportamiento y están diseñado para ajustar el código de la máquina para que el resultado más probable se alinee con el código general del procesador suposición. Esto requiere muchos ajustes y ajustes en los hábitos de desarrollo de software.
Otra alternativa era aprender de la estadística que los bucles generalmente se toman y siempre saltan si la rama va hacia atrás en el flujo de instrucciones y nunca salte si el salto es hacia adelante porque normalmente ese sería el estado estadísticamente menos probable de dejar un círculo. Ambos son tipos de predicción de bifurcación estática, donde el resultado de una bifurcación se predice en tiempo de compilación.
Predictores de ramas dinámicas
Los predictores de bifurcación modernos son dinámicos y utilizan estadísticas del programa que se está ejecutando actualmente para lograr mejores tasas de éxito de predicción. Un contador de saturación es una base para todos los predictores de rama actuales. La primera conjetura se decide de forma estática o aleatoria. Una vez que se ha tomado o no una rama, ese resultado se almacena en una parte de la memoria. La próxima vez que aparezca la misma rama, el predictor de rama predice el mismo resultado que antes.
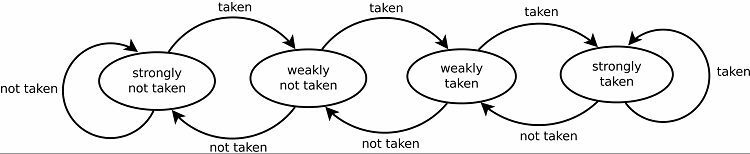
Naturalmente, esto da como resultado buenas tasas de predicción para los bucles. Hay dos versiones de esto. Las primeras versiones simplemente usaban un solo bit de datos para indicar si se tomó la rama o no. Las versiones posteriores usan dos bits para indicar una elección débil o fuertemente tomada o no tomada. Esta configuración aún puede predecir el resultado de realizar un bucle si el programa vuelve a él, lo que generalmente aumenta las tasas de éxito.
Patrones de seguimiento
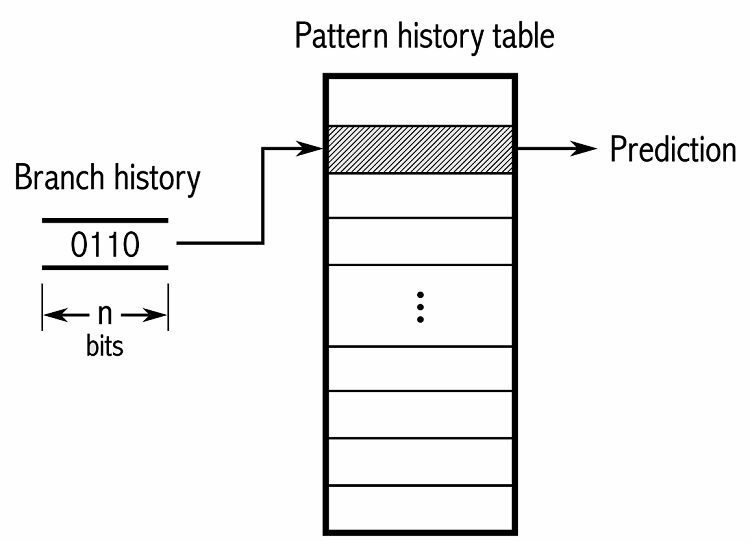
Para realizar un seguimiento de los patrones, algunos predictores de bifurcación realizan un seguimiento de un historial de las opciones que se tomaron. Por ejemplo, supongamos que se llama continuamente a un ciclo, pero solo se repite cuatro veces antes de salir del ciclo. En ese caso, un predictor adaptativo de dos niveles puede identificar este patrón y predecir que volverá a ocurrir. Esto aumenta aún más las tasas de éxito con respecto a un simple contador saturado. Los predictores de ramas modernos se basan en esto aún más mediante el uso de una red neuronal para detectar y predecir patrones.
Algunos predictores de bifurcación usan varios algoritmos y luego comparan los resultados para decidir qué predicción usar. Algunos sistemas realizan un seguimiento de cada instrucción de bifurcación por separado en lo que se denomina predicción de bifurcación local. Otros usan un sistema global de predicción de bifurcaciones para rastrear todas las instrucciones de bifurcación recientes. Ambos tienen sus usos y desventajas.
Conclusión
Un predictor de bifurcación es una parte especial de una CPU canalizada. Intenta predecir el resultado de una instrucción de bifurcación antes de que se procese la instrucción real. Esta es una función central de una CPU canalizada, ya que permite que la CPU mantenga la canalización saturada incluso si no está seguro de qué instrucciones deben ejecutarse. No ofrecen ninguna reducción en el rendimiento cuando son correctos. Los algoritmos modernos pueden ser precisos en cargas de trabajo relativamente predecibles hasta en un 97 % del tiempo.
No existe un método perfecto de predicción, por lo que las implementaciones varían. El impacto en el rendimiento de hacer una predicción incorrecta depende de la longitud de la canalización. Específicamente, la longitud de la tubería antes de que se pueda determinar si la predicción fue incorrecta. También depende de cuántas instrucciones haya en cada etapa de la canalización. Las CPU modernas de escritorio de gama alta tienen alrededor de 19 etapas de canalización y pueden ejecutar al menos cuatro instrucciones simultáneamente en cada etapa.