초기 컴퓨터는 완전히 순차적이었습니다. 프로세서가 수신한 각 명령은 다음 명령이 시작되기 전에 순서대로 완전히 완료되어야 했습니다. 대부분의 명령어에는 명령어 페치, 명령어 디코드, 실행, 메모리 액세스 및 쓰기 되돌림의 5단계가 있습니다. 각 단계는 완료해야 하는 명령을 받고 작업을 수행 중인 값과 분리합니다. 작동, 작업 실행, 결과가 기록될 레지스터를 열고 결과를 열린 레지스터에 씁니다. 등록하다.
이러한 각 단계를 완료하는 데 한 주기가 걸립니다. 불행히도 데이터가 레지스터에 없으면 CPU 캐시나 시스템 RAM에서 데이터를 요청해야 합니다. 이것은 수십 또는 수백 클럭 사이클의 대기 시간을 추가하여 훨씬 느립니다. 그 동안 다른 데이터나 명령을 처리할 수 없으므로 다른 모든 작업은 기다려야 합니다. 이러한 유형의 프로세서 설계는 클록 주기당 하나의 명령어 미만을 실행하므로 서브스칼라라고 합니다.

스칼라로 파이프라이닝
스칼라 프로세서는 시스템 파이프라인을 적용하여 달성할 수 있습니다. 실행되는 명령어의 5단계 각각은 실제 프로세서 코어의 서로 다른 하드웨어 비트에서 실행됩니다. 따라서 각 단계의 하드웨어에 공급하는 데이터에 주의를 기울이면 각 단계를 매 주기 바쁘게 유지할 수 있습니다. 완벽한 세계에서 이것은 5배의 속도 향상과 프로세서가 사이클당 전체 명령을 실행하는 완벽한 스칼라가 될 수 있습니다.

실제로 프로그램은 복잡하고 처리량을 줄입니다. 예를 들어 "a = b + c" 및 "d = e + f"라는 두 개의 추가 명령어가 있는 경우 문제 없이 파이프라인에서 실행할 수 있습니다. 그러나 "a = b + c" 다음에 "d = a + e"가 붙는다면 문제가 있는 것입니다. 이 두 명령어가 서로 바로 뒤에 있다고 가정하면 "a"의 새 값을 계산하는 프로세스가 완료되지 않습니다. 두 번째 명령이 "a"의 이전 값을 읽은 다음 잘못된 답을 제공하기 전에 메모리에 다시 기록되는 것은 말할 것도 없습니다. "디".
이 동작은 예정된 명령을 분석하고 다른 명령에 종속된 명령이 너무 가깝게 연속적으로 실행되지 않도록 하는 디스패처를 포함하여 대응할 수 있습니다. 실제로 이 문제를 해결하기 위해 잘못된 순서로 프로그램을 실행합니다. 많은 명령어가 반드시 이전 명령어의 결과에 의존하지 않기 때문에 이것은 효과가 있습니다.
파이프라인을 슈퍼스칼라로 확장
수퍼스칼라 프로세서는 사이클당 하나 이상의 전체 명령어를 실행할 수 있습니다. 이를 수행하는 한 가지 방법은 각 단계를 처리할 수 있는 두 개 이상의 하드웨어 비트가 있도록 파이프라인을 확장하는 것입니다. 이렇게 하면 모든 주기에서 파이프라인의 각 단계에 두 개의 명령이 있을 수 있습니다. 이것은 하드웨어가 복제됨에 따라 설계 복잡성을 증가시키는 결과를 낳지만 탁월한 성능 확장 가능성을 제공합니다.
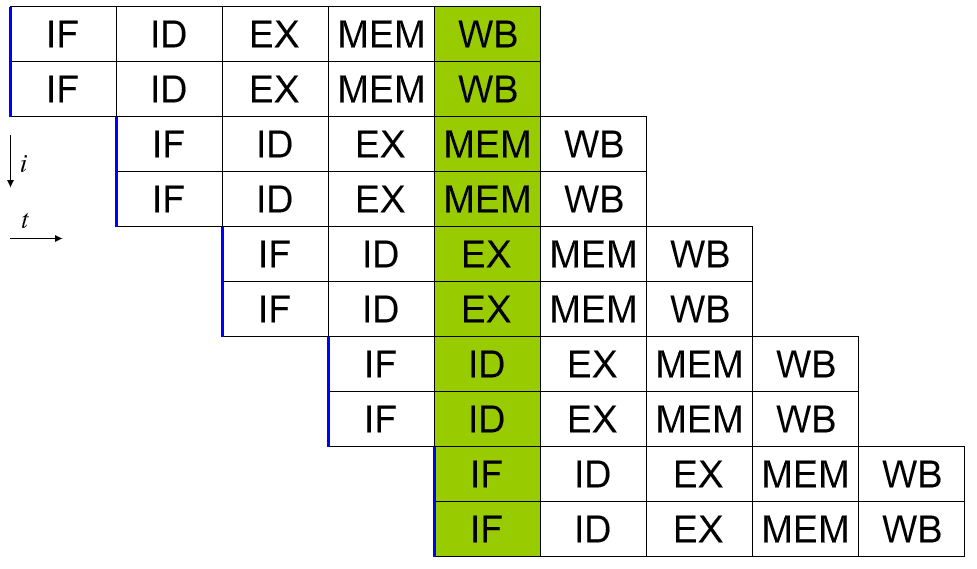
파이프라인을 늘리면 성능이 향상되지만 지금까지는 효율적으로 확장됩니다. 열 및 크기 제약으로 인해 몇 가지 제한이 있습니다. 또한 상당한 일정 복잡도가 있습니다. 효율적인 디스패처는 이제 두 세트의 명령어 중 어느 것도 처리 중인 다른 명령어의 결과에 의존하지 않도록 해야 하므로 훨씬 더 중요합니다.
분기 예측기는 프로세서의 수퍼스칼라가 높을수록 점점 더 중요해지는 디스패처의 일부입니다. 일부 지침에는 두 가지 잠재적인 결과가 있을 수 있으며, 각각은 서로 다른 지침을 따릅니다. 간단한 예는 "if" 문입니다. “이것이 사실이라면 저것도 하고, 그렇지 않으면 다른 것도 하라.” 분기 예측자는 분기 작업의 결과를 예측하려고 시도합니다. 그런 다음 예상되는 결과에 따라 지시 사항을 선제적으로 예약하고 실행합니다.
최신 분기 예측기에는 98% 정도의 분기 예측 성공률을 초래할 수 있는 복잡한 논리가 많이 있습니다. 정확한 예측은 실제 결과를 기다리는 데 낭비될 수 있는 시간을 절약하고, 잘못된 예측은 예측된 지시 사항과 그 결과는 폐기되고 실제 지시 사항이 그 자리에서 실행됩니다. 기다렸다. 따라서 높은 예측 성공률은 성능을 눈에 띄게 향상시킬 수 있습니다.
결론
컴퓨터 프로세서는 클록 주기당 하나 이상의 명령을 수행할 수 있는 경우 슈퍼스칼라로 간주됩니다. 초기 컴퓨터는 한 번에 하나의 명령만 실행하는 완전히 순차적이었습니다. 이것은 각 명령어가 완료하는 데 한 사이클 이상 소요되었으며 이러한 프로세서는 하위 스칼라임을 의미했습니다. 명령의 각 단계에 대해 단계별 하드웨어를 사용할 수 있게 하는 기본 파이프라인은 클록 주기당 최대 하나의 명령을 실행할 수 있으므로 스칼라가 됩니다.
단일 클럭 사이클에서 개별 명령어가 완전히 처리되지 않는다는 점에 유의해야 합니다. 여전히 최소 5주기가 걸립니다. 그러나 한 번에 여러 명령이 파이프라인에 있을 수 있습니다. 이를 통해 주기당 하나 이상의 완료된 명령의 처리량이 허용됩니다.
슈퍼스칼라는 하이퍼스케일 컴퓨팅 리소스를 제공할 수 있는 회사를 지칭하는 하이퍼스케일러와 혼동되어서는 안 됩니다. 하이퍼스케일 컴퓨팅에는 컴퓨팅, 메모리, 네트워크 대역폭 및 스토리지와 같은 하드웨어 리소스를 수요에 따라 원활하게 확장할 수 있는 기능이 포함됩니다. 이는 일반적으로 대규모 데이터 센터 및 클라우드 컴퓨팅 환경에서 발견됩니다.