In bijna elk computerprogramma zijn er delen van de code die zich in afzonderlijke paden vertakken. Een if-then-else-statement heeft bijvoorbeeld twee mogelijke uitkomsten. Deze verklaringen vormen geen enkel probleem voor sequentiële processors, omdat de CPU elke opdracht in volgorde verwerkt. Branches vormen een groot probleem voor pijplijnprocessors, omdat meerdere instructies tegelijk worden uitgevoerd.
Het scenario
In het geval van een programma met een vertakkingsinstructie met twee mogelijke uitkomsten, kunnen de twee mogelijke codepaden niet op dezelfde plaats staan. De verwerking die nodig is om beide opties te voltooien, is anders. Anders zou het programma niet vertakken. Er zullen waarschijnlijk een behoorlijk aantal vertakkingsinstructies zijn die maar één keer worden genomen, zoals een if-statement.
Er zijn ook vertakkende instructies die een lus vormen. Hoewel deze numeriek misschien niet zo gebruikelijk zijn als verklaringen voor eenmalig gebruik, worden ze over het algemeen statistisch herhaald. Er kan worden aangenomen dat het waarschijnlijker is dat een vertakking je terug in een lus zal brengen dan niet.
Waarom is dit een probleem?
Het maakt niet uit hoe dit probleem wordt geformuleerd in een volledig sequentiële processor. Het is gewoon geen probleem. Welke tak zal worden genomen, is bekend voordat het eerste deel van de volgende instructie wordt verwerkt.
In een pijplijnprocessor worden de volgende instructies echter in de wachtrij geplaatst. Ze worden al verwerkt als de processor weet welke tak wordt genomen. Dus hoe moet de processor met dit scenario omgaan? Er zijn een paar opties. Het ergste is gewoon wachten en de pijplijn inactief laten terwijl hij wacht op het antwoord op welke tak hij moet nemen. Dit zou betekenen dat elke keer dat u een vertakkingsinstructie hebt, u altijd minstens zoveel processortijdcycli zou verliezen als er fasen in de pijplijn zitten.
U kunt ook proberen beide opties in de pijplijn uit te voeren en de verkeerde keuze weggooien. Dit zou de helft van de straf zijn van niets doen, maar nog steeds een prestatiestraf opleveren voor elke vertakkingsverklaring. Aangezien moderne CPU's ook instructies in de verkeerde volgorde kunnen uitvoeren, kunt u mogelijk proberen elke vertakkingsinstructie zo snel mogelijk uit te voeren. Het resultaat is dus bekend voordat het nodig is. Deze optie kan nuttig zijn, behalve dat deze niet schaalbaar is. Stel dat u een relatief hoge dichtheid aan vertakkingsverklaringen heeft. In dat geval kunt u ze gewoon niet allemaal eerder uitvoeren zonder enige tijd inactief te zijn.
Hoe wordt dit probleem echt aangepakt?
In werkelijkheid bevat de processor een vertakkingsvoorspeller. De vertakkingsvoorspeller probeert te raden welk resultaat van een vertakkingskeuze zal worden genomen. De processor neemt dan aan dat de voorspelling correct is en plant instructies. Als de vertakkingsvoorspeller nauwkeurig is, is er geen prestatiestraf.
Als de vertakkingsvoorspeller een fout maakt, moet u de pijplijn doorspoelen en beginnen met het verwerken van het werkelijke resultaat. Dit resulteert wel in een iets slechtere prestatiestraf dan niets doen en gewoon wachten op het resultaat. Om de beste prestaties te krijgen, is het belangrijk ervoor te zorgen dat de vertakkingsvoorspeller zo nauwkeurig mogelijk is. Hier zijn verschillende benaderingen voor.
Overeenkomende code
In machinecode is een vertakking altijd een keuze tussen het lezen van de volgende instructie of het springen naar een set instructies elders. Sommige vroege implementaties van vertakkingsvoorspellers gingen er simpelweg van uit dat alle vertakkingen altijd of nooit zouden worden genomen. Deze implementatie kan een verrassend goed slagingspercentage hebben als compilers dit gedrag kennen en zijn ontworpen om de machinecode aan te passen zodat het meest waarschijnlijke resultaat overeenkomt met de algemene van de processor veronderstelling. Dit vereist veel afstemming en aanpassing van de gewoontes van softwareontwikkeling.
Een ander alternatief was om van de statistiek te leren dat lussen over het algemeen worden genomen en altijd springen als de tak achteruit gaat in de instructiestroom en spring nooit als de sprong voorwaarts is, omdat dat normaal gesproken de statistisch minder waarschijnlijke toestand is van het verlaten van een lus. Dit zijn beide soorten statische vertakkingsvoorspelling, waarbij het resultaat van een vertakking wordt voorspeld tijdens het compileren.
Dynamische vertakkingsvoorspellers
Moderne branchevoorspellers zijn dynamisch en gebruiken statistieken van het momenteel lopende programma om betere voorspellingssuccespercentages te behalen. Een verzadigingsteller is een basis voor alle huidige takvoorspellers. De eerste gok wordt statisch of willekeurig bepaald. Zodra een tak is genomen of niet is genomen, wordt dat resultaat opgeslagen in een deel van het geheugen. De volgende keer dat dezelfde vertakking rondkomt, voorspelt de vertakkingsvoorspeller hetzelfde resultaat als voorheen.
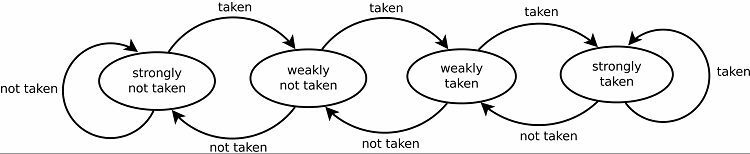
Dit resulteert natuurlijk in goede voorspellingspercentages voor lussen. Hier zijn twee versies van. De vroege versies gebruikten gewoon een enkel stukje gegevens om aan te geven of de tak werd genomen of niet. Latere versies gebruiken twee bits om een zwak of sterk genomen of niet genomen keuze aan te geven. Deze opstelling kan nog steeds het resultaat voorspellen van het nemen van een lus als het programma ernaar terugkeert, wat over het algemeen de slagingspercentages verhoogt.
Volgpatronen
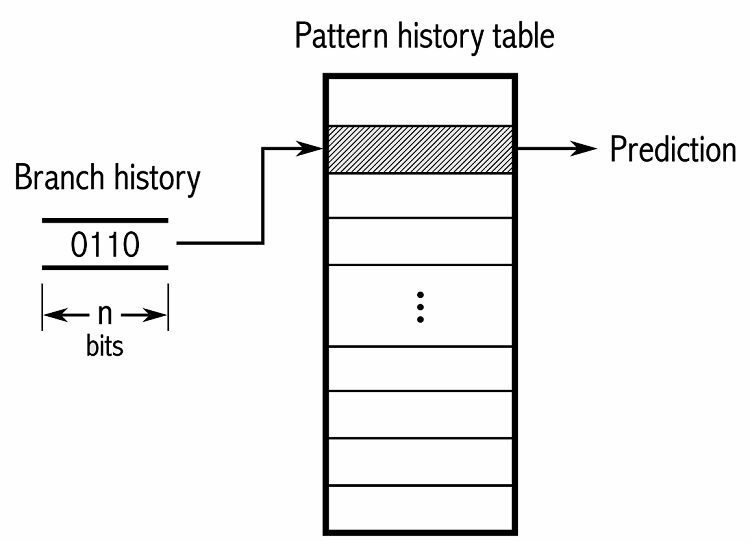
Om patronen te volgen, houden sommige branchevoorspellers een geschiedenis bij van welke keuzes zijn gemaakt. Stel bijvoorbeeld dat een lus continu wordt aangeroepen, maar slechts ongeveer vier keer wordt herhaald voordat de lus wordt verbroken. In dat geval kan een adaptieve voorspeller op twee niveaus dit patroon identificeren en voorspellen dat het opnieuw zal gebeuren. Dit verhoogt de slagingspercentages nog verder over een eenvoudige verzadigde teller. Moderne branchevoorspellers bouwen hierop voort door een neuraal netwerk te gebruiken om patronen te herkennen en te voorspellen.
Sommige branchevoorspellers gebruiken meerdere algoritmen en vergelijken vervolgens de resultaten om te beslissen welke voorspelling moet worden gebruikt. Sommige systemen houden elke vertakkingsinstructie afzonderlijk bij in de zogenaamde lokale vertakkingsvoorspelling. Anderen gebruiken een globaal vertakkingsvoorspellingssysteem om alle recente vertakkingsinstructies te volgen. Beide hebben hun gebruik en nadelen.
Conclusie
Een vertakkingsvoorspeller is een speciaal onderdeel van een gepijplijnde CPU. Het probeert de uitkomst van een vertakkingsinstructie te voorspellen voordat de eigenlijke instructie wordt verwerkt. Dit is een kernfunctie van een CPU met pijplijn, omdat het de CPU in staat stelt de pijplijn verzadigd te houden, zelfs als hij niet zeker weet welke instructies moeten worden uitgevoerd. Ze bieden geen prestatievermindering als ze correct zijn. Moderne algoritmen kunnen tot 97% van de tijd nauwkeurig zijn in relatief voorspelbare workloads.
Er is geen perfecte voorspellingsmethode, dus implementaties variëren. De prestatie-impact van het maken van een verkeerde voorspelling hangt af van de lengte van de pijplijn. Met name de lengte van de pijplijn voordat deze kan worden bepaald als de voorspelling verkeerd was. Het hangt ook af van het aantal instructies in elke pijplijnfase. Moderne high-end desktop-CPU's hebben ongeveer 19 pijplijnfasen en kunnen in elke fase ten minste vier instructies tegelijk uitvoeren.