Takmer v každom počítačovom programe sú časti kódu, ktoré sa rozvetvujú do samostatných ciest. Napríklad výrok if-then-else má dva možné výsledky. Tieto vyhlásenia nepredstavujú žiadny problém pre sekvenčné procesory, pretože CPU spracováva každý príkaz v poradí. Vetvy predstavujú veľký problém pre pipeline procesory, keďže sa vykonáva viacero inštrukcií naraz.
Scenár
V prípade programu s rozvetveným príkazom s dvoma možnými výstupmi nemôžu byť dve možné cesty kódu na rovnakom mieste. Spracovanie potrebné na dokončenie oboch možností sa bude líšiť. V opačnom prípade by sa program nerozvetvil. Pravdepodobne bude existovať značný počet rozvetvených príkazov, ktoré sa použijú iba raz, napríklad príkaz if.
Existujú aj vetviace príkazy, ktoré tvoria slučku. Hoci tieto čísla nemusia byť také bežné ako jednorazové vyhlásenia, vo všeobecnosti sa štatisticky opakujú. Dá sa predpokladať, že je pravdepodobnejšie, že vás pobočka vráti späť do slučky ako nie.
Prečo je to problém?
Nezáleží na tom, ako je tento problém formulovaný v plne sekvenčnom procesore. Jednoducho to nie je problém. Ktorá vetva sa použije, je známa pred spracovaním prvej časti nasledujúcej inštrukcie.
V zreťazenom procesore sú však nasledujúce inštrukcie zaradené do frontu. Už sa spracúvajú, keď procesor vie, ktorá vetva sa berie. Ako by teda mal procesor zvládnuť tento scenár? Možností je niekoľko. Najhoršie je jednoducho čakať a nechať potrubie nečinné, kým čaká na odpoveď, na ktorú vetvu sa má vybrať. To by znamenalo, že zakaždým, keď máte príkaz vetvenia, vždy by ste stratili aspoň toľko cyklov procesorového času, koľko máte fáz v potrubí.
Prípadne môžete skúsiť spustiť obe možnosti a zahodiť nesprávnu voľbu. To by malo polovičnú pokutu za to, že nič neurobíte, ale stále by to znamenalo trest za výkon pri každom rozvetvení. Vzhľadom na to, že moderné CPU môžu spúšťať inštrukcie aj mimo poradia, mohli by ste sa potenciálne pokúsiť spustiť každú vetviacu inštrukciu čo najskôr. Takže jeho výsledok je známy skôr, ako je potrebný. Táto možnosť môže byť užitočná, ale nie je škálovateľná. Predpokladajme, že máte relatívne vysokú hustotu rozvetvených príkazov. V takom prípade jednoducho nebudete môcť spustiť všetky z nich skoro bez toho, aby ste mali nejaký čas nečinnosti.
Ako sa tento problém skutočne rieši
V skutočnosti procesor obsahuje prediktor vetvy. Prediktor vetvenia sa pokúša uhádnuť, ktorý výsledok voľby vetvenia bude prijatý. Procesor potom predpokladá, že predpoveď je správna a naplánuje inštrukcie. Ak je prediktor vetvy presný, nedochádza k žiadnemu trestu za výkon.
Ak sa prediktor vetvenia pomýli, musíte potrubie prepláchnuť a začať spracovávať skutočný výsledok. To má za následok o niečo horšiu penalizáciu za výkon, ako keby ste nič neurobili a len čakali na výsledok. Ak chcete dosiahnuť najlepší výkon, je dôležité zabezpečiť, aby bol prediktor vetvy čo najpresnejší. K tomu existuje celý rad rôznych prístupov.
Zodpovedajúci kód
V strojovom kóde je vetva vždy voľbou medzi čítaním ďalšej inštrukcie alebo skokom na sadu inštrukcií inde. Niektoré skoré implementácie prediktorov vetiev jednoducho predpokladali, že všetky vetvy budú vždy alebo nikdy prijaté. Táto implementácia môže mať prekvapivo dobrú úspešnosť, ak kompilátory poznajú toto správanie a sú navrhnuté tak, aby upravili strojový kód tak, aby sa najpravdepodobnejší výsledok zhodoval so všeobecným procesorom predpoklad. To si vyžaduje veľa ladenia a úpravy návykov vývoja softvéru.
Ďalšou alternatívou bolo naučiť sa zo štatistiky, že slučky sa vo všeobecnosti berú a vždy preskočia, ak sa vetva vráti späť tok inštrukcií a nikdy neskočiť, ak je skok vpred, pretože to by bol normálne štatisticky menej pravdepodobný stav opustenia a slučka. Toto sú oba typy predikcie statickej vetvy, kde sa výsledok vetvenia predpovedá v čase kompilácie.
Dynamické prediktory vetví
Moderné prediktory vetiev sú dynamické a využívajú štatistiky z aktuálne spusteného programu na dosiahnutie lepšej miery úspešnosti predpovedí. Počítadlo saturácie je základom pre všetky súčasné prediktory vetvenia. Prvý tip sa rozhodne staticky alebo náhodne. Akonáhle je vetva vybratá alebo nie, tento výsledok sa uloží do časti pamäte. Keď nabudúce príde rovnaká vetva, prediktor vetvy predpovedá rovnaký výsledok ako predtým.
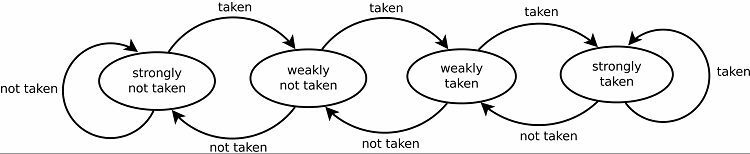
To prirodzene vedie k dobrým predpovediam pre slučky. Existujú dve verzie tohto. Prvé verzie jednoducho používali jeden bit údajov na označenie, či bola vetva odobratá alebo nie. Neskoršie verzie používajú dva bity na označenie slabo, silne alebo neprijatej voľby. Toto nastavenie môže stále predpovedať výsledok cyklu, ak sa k nemu program vráti, čo vo všeobecnosti zvyšuje úspešnosť.
Sledovacie vzory
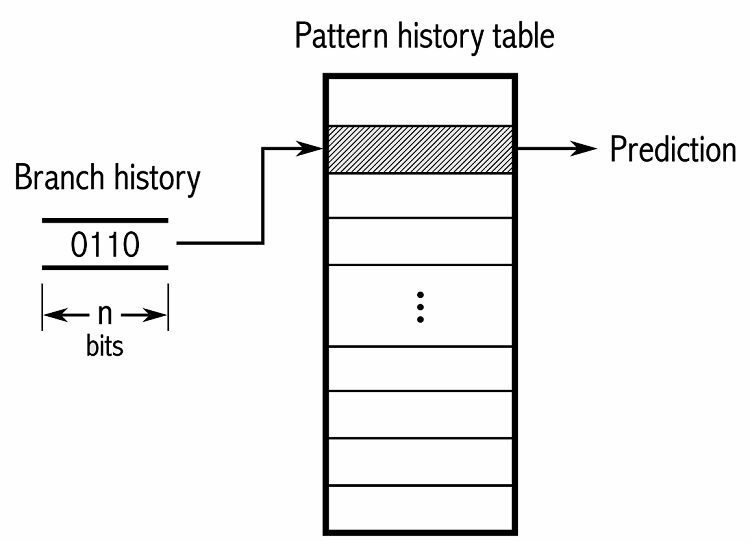
Na sledovanie vzorcov niektoré prediktory vetví sledujú históriu toho, aké voľby boli prijaté. Predpokladajme napríklad, že slučka je nepretržite volaná, ale pred prerušením slučky sa zacyklí iba štyrikrát. V takom prípade môže dvojúrovňový adaptívny prediktor identifikovať tento vzor a predpovedať, že sa bude opakovať. To ešte viac zvyšuje úspešnosť pri jednoduchom nasýtenom počítadle. Moderné prediktory vetiev na tom ďalej stavajú pomocou neurónovej siete na zistenie a predpovedanie vzorov.
Niektoré prediktory vetvy používajú viacero algoritmov a potom porovnávajú výsledky, aby sa rozhodli, ktorú predpoveď použiť. Niektoré systémy sledujú každú inštrukciu vetvenia oddelene v tom, čo sa nazýva predikcia lokálnej vetvy. Iní používajú globálny systém predikcie vetvenia na sledovanie všetkých nedávnych inštrukcií vetvenia. Oboje má svoje využitie aj negatíva.
Záver
Prediktor vetvy je špeciálna časť zreťazeného CPU. Pokúša sa predpovedať výsledok vetviacej inštrukcie pred spracovaním samotnej inštrukcie. Toto je základná funkcia zreťazeného CPU, pretože umožňuje CPU udržať potrubie nasýtené, aj keď si nie je istý, aké inštrukcie je potrebné vykonať. Neposkytujú žiadne zníženie výkonu, keď sú správne. Moderné algoritmy môžu byť presné pri relatívne predvídateľných pracovných zaťaženiach až v 97 % prípadov.
Neexistuje žiadna dokonalá metóda predpovedania, takže implementácie sa líšia. Vplyv nesprávnej predpovede na výkon závisí od dĺžky potrubia. Konkrétne, dĺžka potrubia pred ním môže byť určená, ak bola predpoveď nesprávna. Závisí to aj od toho, koľko inštrukcií je v každom štádiu potrubia. Moderné špičkové desktopové CPU majú približne 19 pipeline stupňov a v každej fáze môžu spúšťať najmenej štyri inštrukcie súčasne.