Майже в будь-якій комп’ютерній програмі є частини коду, які розгалужуються на окремі шляхи. Наприклад, оператор if-then-else має два можливі результати. Ці заяви не створюють жодних проблем для послідовних процесорів, оскільки центральний процесор обробляє кожну команду по порядку. Розгалуження становлять велику проблему для конвеєрних процесорів, оскільки декілька інструкцій виконуються одночасно.
Сценарій
У випадку програми з інструкцією розгалуження з двома можливими результатами два можливі шляхи коду не можуть бути в одному місці. Обробка, необхідна для виконання будь-якого варіанту, буде різною. Інакше програма не розгалужується. Ймовірно, буде чимала кількість операторів розгалуження, які беруться лише один раз, як оператор if.
Існують також оператори розгалуження, які утворюють цикл. Хоча вони можуть бути не такими поширеними в чисельній формі, як одноразові твердження, вони, як правило, статистично повторюються. Можна припустити, що гілка швидше поверне вас по циклу, ніж ні.
Чому це проблема?
Немає значення, як ця проблема сформульована в повністю послідовному процесорі. Це просто не проблема. Яку гілку буде взято, відомо до того, як буде оброблено першу частину наступної інструкції.
Однак у конвеєрному процесорі наступні інструкції стоять у черзі. Вони вже обробляються, коли процесор знає, яку гілку займає. Отже, як процесор має впоратися з цим сценарієм? Є декілька варіантів. Найгірше просто чекати і залишати конвеєр бездіяльним, поки він очікує відповіді, яку гілку вибрати. Це означатиме, що кожного разу, коли у вас є оператор розгалуження, ви завжди втрачатимете принаймні стільки циклів процесорного часу, скільки у вас є етапів у конвеєрі.
Крім того, ви можете спробувати запустити обидва варіанти в конвеєрі та відхилити неправильний вибір. Це матиме половину штрафу за невиконання нічого, але все одно призведе до зниження продуктивності для кожного оператора розгалуження. Враховуючи, що сучасні ЦП також можуть виконувати інструкції не в порядку, ви потенційно можете спробувати виконати кожну інструкцію розгалуження якомога швидше. Тож його результат відомий ще до того, як він знадобиться. Цей параметр може бути корисним, за винятком того, що він не масштабується. Припустімо, що у вас відносно висока щільність операторів розгалуження. У такому випадку ви просто не зможете запустити їх усі раніше, не маючи деякого часу простою.
Як справді вирішується ця проблема
Насправді процесор включає в себе предиктор розгалужень. Прогноз розгалуження намагається вгадати, який результат вибору розгалуження буде використано. Потім процесор припускає, що передбачення правильне, і планує інструкції. Якщо предиктор розгалужень точний, покарання за продуктивність не буде.
Якщо предиктор розгалужень робить помилку, ви повинні очистити конвеєр і почати обробку фактичного результату. Це призводить до трохи гіршого покарання продуктивності, ніж якщо нічого не робити і просто чекати на результат. Щоб отримати найкращу продуктивність, важливо переконатися, що предиктор гілок є максимально точним. Існує ряд різних підходів до цього.
Код відповідності
У машинному коді розгалуження завжди є вибором між читанням наступної інструкції або переходом до набору інструкцій в іншому місці. Деякі ранні реалізації предикторів гілок просто припускали, що всі гілки завжди або ніколи не будуть зайняті. Ця реалізація може мати напрочуд високий рівень успіху, якщо компілятори знають про цю поведінку і знають призначений для налаштування машинного коду таким чином, щоб найбільш вірогідний результат узгоджувався із загальним процесором припущення. Це вимагає значного налаштування та коригування звичок розробки програмного забезпечення.
Іншою альтернативою було дізнатися зі статистики, що цикли, як правило, беруться і завжди перескакують, якщо гілка йде назад у потік інструкцій і ніколи не стрибайте, якщо стрибок здійснюється вперед, оскільки це, як правило, статистично менш ймовірний стан виходу з петля. Це обидва типи статичного передбачення розгалуження, де результат розгалуження прогнозується під час компіляції.
Динамічні прогнози гілок
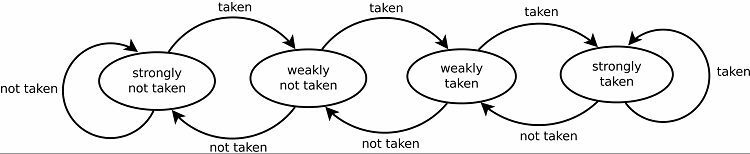
Сучасні предиктори гілок є динамічними, вони використовують статистичні дані з поточної запущеної програми для досягнення кращих показників успіху прогнозування. Лічильник насичення є основою для всіх поточних предикторів гілок. Перше припущення визначається статично або випадковим чином. Після того, як гілка була взята чи не взята, цей результат зберігається в частині пам’яті. Наступного разу, коли з’явиться та сама гілка, предиктор гілок передбачає той самий результат, що й раніше.
Це, природно, призводить до хороших показників передбачення для циклів. Існує дві версії цього. Ранні версії просто використовували один біт даних, щоб вказати, чи була гілка взята чи ні. Пізніші версії використовують два біти для вказівки на те, чи прийнято або не прийнято вибір слабо чи сильно. Ця настройка все ще може передбачити результат виконання циклу, якщо програма повернеться до нього, загалом підвищуючи рівень успіху.
Шаблони відстеження
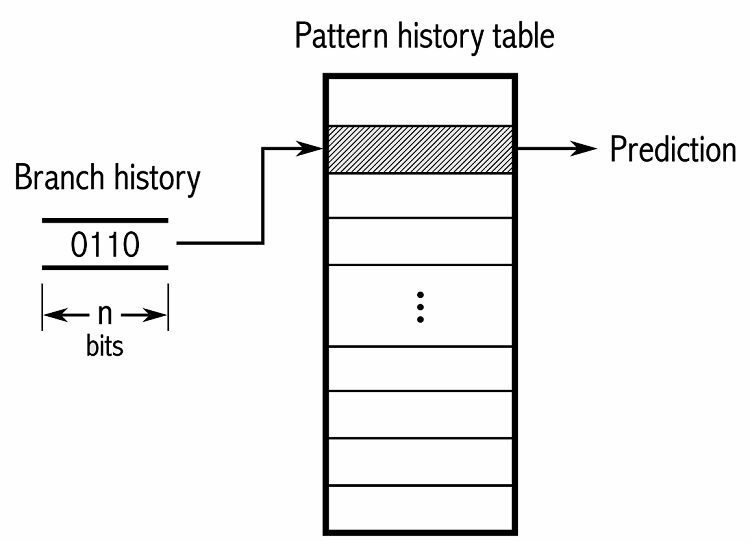
Щоб відстежувати закономірності, деякі предиктори розгалужень відстежують історію зроблених виборів. Наприклад, припустимо, що цикл безперервно викликається, але лише чотири рази, перш ніж вийти з циклу. У цьому випадку дворівневий адаптивний предиктор може ідентифікувати цю модель і передбачити її повторення. Це ще більше підвищує рівень успіху порівняно з простим насиченим лічильником. Сучасні засоби прогнозування гілок будують це далі, використовуючи нейронні мережі для виявлення та прогнозування закономірностей.
Деякі предиктори гілок використовують кілька алгоритмів, а потім порівнюють результати, щоб вирішити, який прогноз використовувати. Деякі системи відстежують кожну інструкцію розгалуження окремо в тому, що називається локальним передбаченням розгалуження. Інші використовують глобальну систему передбачення розгалужень для відстеження всіх останніх інструкцій розгалуження. Обидва мають свої переваги та недоліки.
Висновок
Прогноз розгалужень є спеціальною частиною конвеєрного ЦП. Він намагається передбачити результат інструкції розгалуження до того, як буде оброблено фактичну інструкцію. Це основна функція конвеєрного ЦП, оскільки вона дозволяє ЦП підтримувати конвеєр насиченим, навіть якщо він не впевнений, які інструкції потрібно виконати. Вони не забезпечують зниження продуктивності, якщо вони правильні. Сучасні алгоритми можуть бути точними у відносно передбачуваних навантаженнях у 97% випадків.
Немає ідеального методу передбачення, тому реалізації відрізняються. Вплив неправильного прогнозування на продуктивність залежить від довжини конвеєра. Зокрема, довжина трубопроводу до того, як можна буде визначити, чи був прогноз помилковим. Це також залежить від кількості інструкцій на кожному етапі конвеєра. Сучасні настільні процесори високого класу мають близько 19 етапів конвеєра і можуть виконувати щонайменше чотири інструкції одночасно на кожному етапі.